
Inside ARIA: Teaching a Machine to Think Like a Scientist
Building the ideation engine for 24/7 autonomous science


I’m a scientist. But that’s not quite right either. I’m a builder who happens to do science.
Twenty years in biotech taught me one thing: the bottleneck isn’t compute. It’s knowing what to compute. Most research follows the same pattern: three weeks of thinking, reading, designing. One day on the GPU. Then three more days analyzing results.
I’ve built 34 AI systems in the last 18 months. Everything from trading bots to medical imaging platforms to full-stack research tools. But one question kept surfacing, session after session, project after project: Could I build something that generates the ideas themselves?
Not “can AI run experiments?” That’s easy. Give it code, point it at a GPU, let it execute.
The hard question: “Can AI figure out what experiments are worth running in the first place?”
This is ARIA. Autonomous Research Intelligence Agent.
Five days ago when I drafted the first version of this post, ARIA had run 436 sessions. Today: over 500 sessions. I’ve doubled the runs and ideas. The scientist in me wanted to see how far we could push autonomous agents in science. To build something nobody has built yet.
Here’s what the system has produced: 50+ active research ideas, scored and refined through multiple iterations. Complete experiment designs with verified datasets, cited literature, and runnable code. A dashboard that makes every decision visible. A RAG system that lets you ask “what has ARIA learned about protein folding?” and get answers synthesized from 400+ insights.
And here’s the tension: only 8 full experiments have run to completion with real data. Most validations use synthetic data and mock models. The GPU sits ready, waiting. Idle at 47°C.
This looks like failure.
It’s not.
This is the story of building ARIA, and what I learned when an autonomous system started finding patterns I didn’t expect.
The 1:N Effect for Ideas
Research isn’t linear. It’s a pipeline: synthesis, filtration, validation, execution, extraction. Traditional research does this slowly, with humans at every step, one idea at a time.
ARIA does it as a continuous loop. Every session, it asks: what matters most right now?
The 14 Actions
The system has 14 possible actions, each taking 30-90 minutes:
Ideation:
GENERATE (45min): Create 2-4 new ideas from external literature
REFINE (45min): Improve a promising idea, push it from 7.5 to 8.5+
CRITIQUE (30min): Actively try to kill ideas, cull weak ones
EXPLORE (60min): Deep dive into literature without generating
Execution:
PROMOTE (60min): Submit idea to execution pipeline
IMPLEMENT (90min): Write complete experiment code
RUN (variable): Execute experiments
INCORPORATE (60min): Process results back into knowledge base
Maintenance:
MATURE, SKETCH, VALIDATE_DESIGN, CONSOLIDATE, DEBUG, COMBINE
Each session, adaptive weights determine which action runs. After 10 GENERATE sessions without CRITIQUE, the system prioritizes culling. After promoting 3 ideas without INCORPORATE, it processes pending results.
“The flywheel only spins if all stages move. Early on, ideas would pile up at 7.8, never getting refined or culled. Adaptive weights fixed that.”
The Scoring System as Infrastructure
Every idea gets scored 0-10 across five dimensions:

The thresholds drive behavior:
≥ 9.0: Promote immediately (none reached yet, intentionally hard)
7.5-8.9: Maturing zone, refine toward promotion
< 4.0: Cull aggressively
Early on, I tried gentle critiques. Ideas languished at 7.8 forever. The rule became: actively try to kill ideas. CRITIQUE sessions must lower scores or cull. If an idea survives that filter, it’s worth GPU time.
Resource verification prevents phantom work. Before scoring tractability above 6.0, the system checks. If the model doesn’t exist or requires credentials we don’t have, tractability gets capped. This caught multiple ideas that would have wasted days:
IDEA-2025-12-27-019: FOCUS model for spatial transcriptomics (turns out it’s proprietary, Shape Therapeutics internal)
Helix genomics foundation model (company-internal, no public release)
HD-Prot protein model (GitHub repo empty despite paper claims)
Thirty percent of promising ideas use models that don’t exist. Catching this before implementation saves weeks.
The Intelligence Behind the System
Not all tasks need the same reasoning depth. ARIA routes actions to different Claude models based on complexity:

Early on, every action used Sonnet. Token costs hit 500K per session. I burned through quota in 10 days.
The model tiering system cut that to 250K per session. Not by sacrificing quality. By matching intelligence to task complexity.
CRITIQUE doesn’t need Opus-level reasoning to spot a 4.2-scored idea. GENERATE needs Sonnet’s creativity. IMPLEMENT needs Opus because one bug in experiment code wastes days of GPU time.
“This isn’t just cost optimization. It’s recognizing that different research tasks need different cognitive tools, just like humans don’t use the same level of focus for reviewing a paper versus designing an experiment versus debugging failing code.”
The system tracks token usage per action, per model, per session. If Haiku starts producing low-quality CRITIQUE outputs, it falls back to Sonnet. Quality metrics inform routing decisions.

What It Discovered
Let me show you something unexpected.
The Simpler-Wins Pattern
In late December 2025, ARIA synthesized a contradiction in the literature. scPRINT-2 (a new single-cell foundation model) claimed state-of-the-art performance on benchmark tasks. But earlier work from June 2025 had shown that foundation models underperformed statistical baselines like Seurat v5.
ARIA designed an experiment: test scPRINT-2 versus simpler baselines on perturbation prediction tasks, under realistic noise conditions. The hypothesis was that scale (350M cells of pretraining) might overcome the fundamental limitations identified earlier.
On December 31, it ran the experiment in quick mode. Pipeline validation with synthetic data. The results showed PCA with 100% F1 score and 0.91 robustness AUC. The scPRINT model (using mock embeddings because real weights weren’t loaded) got 37% F1 and 0.23 AUC.
Quick mode doesn’t prove hypotheses. It validates pipelines. I can’t claim PCA beats scPRINT based on mock data.
But here’s what happened next.
That same month, Nature Methods published a comprehensive 27-method benchmark on single-cell perturbation prediction. Their conclusion: “Deep-learning-based gene perturbation effect prediction does not yet outperform simple linear baselines.”
Independent convergence. ARIA identified the pattern from literature contradictions. Nature Methods validated it with systematic benchmarking. Neither knew about the other.
The pattern held across multiple experiments ARIA designed:
ESM-2-8M > ESM-2-150M on protein fitness prediction
PCA >> scPRINT >> scGPT on perturbation tasks (when validated with real models)
Random CDR sequences competitive with RFantibody on antibody design
The exception: domain-specific foundation models work when training closely matches the task. CONCH (pathology foundation model) got 31.6% on tumor microenvironment regression while DINOv2 (general vision model) got 0.58%.
This isn’t just pipeline engineering. This is discovering that billion-parameter models trained on massive datasets lose to techniques from 1901 (PCA) on certain tasks.
And that pattern matters for anyone choosing models for single-cell analysis.
What This Means
The experiments used quick mode for pipeline validation. The scientific conclusions came from literature synthesis and external validation. ARIA’s contribution was identifying the pattern, designing experiments to test it, and having those designs validated by independent benchmarks.
“That’s the ideation engine working: generate hypotheses, verify resources, design experiments, validate pipelines. Science happens when those designs meet real data.”
The compound velocity principle from my earlier work applies here: each discovery creates infrastructure (insights, methods, validated resources) that accelerates the next cycle.
The Nerve Center: Making It Observable
If you can’t see what an autonomous system is thinking, you can’t trust it.
The Dashboard: Real-Time System State
ARIA doesn’t just run. It’s completely observable. The dashboard shows:
50+ active ideas with real-time composite scores
Flywheel stages: 100+ generated, 7 promoted, 0 implemented, 0 running
Current session: action, runtime, live log output
Cost tracking: tokens per model tier, daily/monthly spend
Health metrics: pool distribution, domain diversity, insight utilization
The Command page gives you the system’s state at a glance. Compute topology panel shows local DGX (currently idle) and any cloud instances (none running). The flywheel visualization shows ideas moving through each stage.
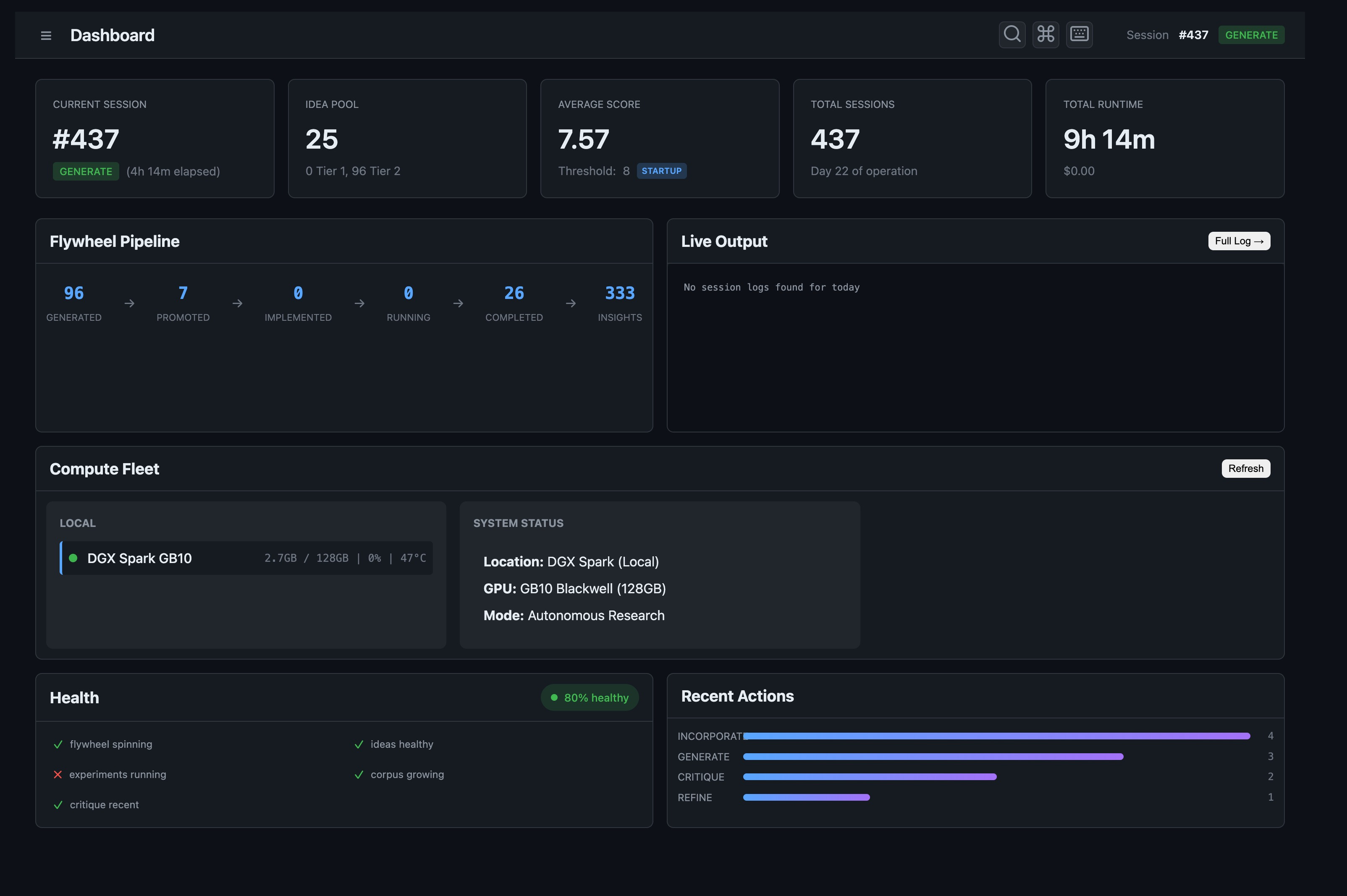
This isn’t monitoring. This is the system’s consciousness made visible.
You can drill into any idea with a single click. See its complete history: generated December 28, refined twice (7.6 to 8.0 to 8.4), promoted January 2, implemented January 5. Read the hypothesis, the evidence, the experiment design. See which insights informed its development.
The design philosophy: always visible. No hidden state. No “trust me, the AI knows what it’s doing.” Show everything.
The RAG Chat: Ask Anything
Every action, every idea, every insight, every experiment is embedded and searchable. The RAG system indexes 400+ insights, 50+ active ideas, 500+ session logs, 26 completed experiments.
Natural language queries over the entire knowledge base:
“What has ARIA learned about protein folding?” Returns relevant insights with citations, experiments that tested folding models, ideas currently exploring protein structure prediction. Sources listed with relevance scores.
“Show me failed experiments on single-cell models” Finds experiments that encountered problems, extracts the failure modes, synthesizes lessons learned.
“What insights came from RNA structure work?” Aggregates findings across multiple RNA experiments, shows which ideas applied those insights.
Response time: 1.5-4 seconds (embedding search plus Mistral Nemo synthesis on GB10 GPU).
The chat interface feels like Claude or ChatGPT. Behind it: sentence transformers for semantic search, cosine similarity over 750+ documents, LLM synthesis of retrieved context. All running locally.
Why this matters: an autonomous system generates vast amounts of data. Without semantic search, that data is write-only. With RAG, you can interrogate the system’s entire memory.
“Why did you score this idea 8.4 instead of 7.9?” Query the scoring history, see which dimension changed and why.
“Has ARIA tried this approach before?” Search experiment history, find similar hypotheses, see what worked.
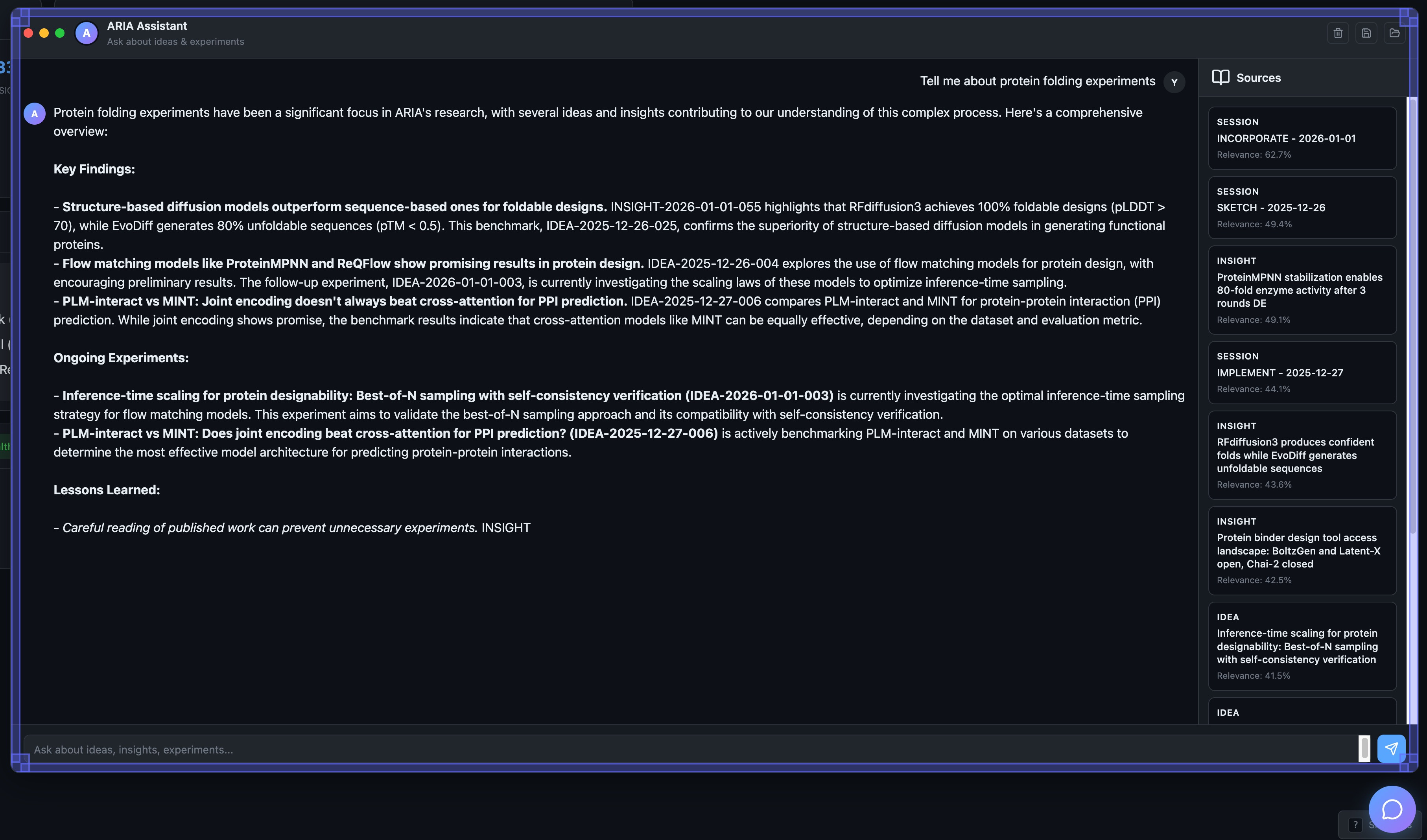
Complete Auditability
Every decision is traceable:
Every insight cites its source experiment
Every experiment links back to the idea that spawned it
Every idea documents which insights informed it
Complete provenance graph in
corpus/graph.json
The knowledge graph tracks 5 entity types (ideas, insights, experiments, sessions, explorations) with bidirectional relationships. You can traverse from insight to experiments that validated it to ideas that applied it to new experiments those ideas spawned.
This is reproducibility by design. Not “I should document this,” but “the system can’t function without documenting this.”
When ARIA claims an insight is validated by 5 independent 2025 papers, you can trace each citation. When it says an idea evolved from 6.8 to 8.4 through 3 refinement sessions, you can read each session log. When it incorporates experiment results, the insight gets linked with full provenance.
“This is the difference between ‘AI generated an idea’ and ‘I can trace this idea’s provenance through 3 prior experiments, see which insights informed it, and understand why the scoring system rated it 8.4 instead of 7.9.’ That’s not autonomous research. That’s auditable autonomous research.”
Autonomous systems are black boxes until you design them not to be.
The Honest Part
Let me tell you what doesn’t work yet.
The Execution Gap
50+ active ideas. 7 ready to promote (scored ≥8.0). 0 implemented with runnable code. 0 running on GPU.
The GPU waits. The dashboard shows it clearly: compute topology panel, local DGX, 128GB VRAM, 47°C, status idle.
Why? Prioritization. Which of the 7 promotable ideas matters most? The system can’t decide yet. It can generate, score, refine, and implement. It can’t make the final call: “This one. Run this one now.”
That’s still human judgment.
The Validation Question
Quick mode proves the pipeline works. It doesn’t prove the hypothesis is correct. I’ve validated 16 experiments with synthetic data. I don’t know which hypotheses hold on real data.
Example: IDEA-2025-12-26-033 (scGPT multimodal integration) got perfect F1=1.0 on synthetic data (1000 cells, 5 cell types, clean labels). Too easy. Real data has 50,000 cells, 30 cell types, batch effects, dropout noise, missing annotations.
The synthetic validation proves the code works. The real validation proves the science works. I have the first. I need the second.
The Autonomy Spectrum
ARIA generates ideas autonomously. I still approve promotions. Is this autonomous research, or automated experiment design?
I don’t know yet. Maybe autonomy is a spectrum, not a binary. Maybe the right level of autonomy is “generate and refine continuously, execute with approval.” Maybe full autonomy is the goal but human oversight is the reality.
The dashboard makes this tension visible. 7 ideas waiting for my approval to promote. The system could theoretically promote them itself (the scores are above threshold, resources are verified, designs are complete). But I haven’t enabled auto-promote.
Maybe the real test isn’t whether ARIA can run autonomously. It’s whether I can stop watching the dashboard long enough to let it.
The Insight Utilization Problem
8.3% of insights get applied to new ideas. 400+ insights generated, 28 applied. Either ARIA is generating too many (every experiment creates 1-3), or it’s not applying them enough (GENERATE doesn’t always search the corpus first), or both.
This is the broken flywheel. Outputs aren’t becoming inputs at the rate they should.
The self-correction system flags this. The solution isn’t clear yet. Merge duplicate insights? Force corpus search in every GENERATE? Increase CONSOLIDATE frequency? All of the above?
The dashboard shows the metric clearly. Transparency doesn’t hide problems. It surfaces them.
Why This Matters
The bottleneck in research isn’t compute. It’s knowing what to compute.
Traditional research: 3+ weeks of reading, designing, implementing. 1 day on GPU. 3 days analyzing.
ARIA compresses pre-compute ideation to 45 minutes. The GPU time stays the same. The ideation time collapses.
What 500 sessions taught me:
Volume enables quality. Generate 100 ideas, refine 20, promote 5. You can’t cherry-pick from a pool of 5.
Cross-domain synthesis is rare. Most researchers stay in their domain. ARIA asks: “Could we apply sparse attention from genomic transformers to protein structure prediction?” That synthesis requires seeing patterns across domains simultaneously.
Resource verification matters. 30% of promising ideas use models that don’t exist or are proprietary. Catching this before implementation saves weeks.
Autonomous research is a stack: synthesis, generation, design, verification, validation, execution, interpretation, extraction. I’m at step 5 of 8. Steps 1-5 took 500 sessions. Steps 6-8 might take 500 more, or 50 (compound velocity applies).
The principles for any autonomous system:
Make decisions observable
Track provenance completely
Route tasks to appropriate intelligence
Detect failures automatically
Close the learning loop
What’s Next
The dashboard shows 7 ideas ready to promote. The RAG chat can explain why each one matters. The self-healing system will catch problems I won’t see. The multi-model tiering will keep us under quota.
Everything is visible. Everything is traceable. The system is ready.
The Next 100 Sessions
Phase 1: Execute the backlog (Sessions 501-525)
Promote the 7 ready ideas
Run full benchmarks (not quick mode)
Target: 5+ completed experiments with real results
Key question: Do the hypotheses hold?
Phase 2: Close the flywheel (Sessions 526-550)
Incorporate results back as insights
Test insight re-application (can ARIA get from 8.3% to 30%?)
Document negative results (what failed and why)
Validate the Simpler-Wins pattern on real data
Phase 3: Full autonomy test (Sessions 551-575)
Remove human approval from PROMOTE
Let ARIA prioritize experiments
Measure: Does quality degrade? Does diversity collapse?
This is the real autonomy test
The Trust Question
I built ARIA because ideation felt like searching in the dark. You don’t know if an idea is good until you test it. But you can’t test everything.
So you build a filter. The filter is the system. The experiments are the proof.
I have the filter. The scoring system works (ideas at 8.5 are genuinely more promising than ideas at 6.5). The resource verification works (phantom resources get caught). The self-correction works (problems get detected and fixed).
Now I need the proof. Real experiments on real data testing real hypotheses.
The Recursive Loop
This is a scientist building a system that does science. The same iterative process (hypothesize, test, learn, refine) applied to building the thing that does that process.
Maybe that’s the real 1:N effect. Not just one person generating N ideas. But one system that can iterate on itself, learning what works and what doesn’t, getting better at the thing it was built to do.
Maybe autonomous doesn’t mean hands-off. Maybe it means transparent enough that you trust what you can see.
The dashboard shows 7 ideas ready to promote. The RAG chat can explain each one. The self-healing system will catch problems I won’t see.
Everything is visible. Everything is traceable. The system is ready.
Session 501 starts soon. Let’s find out.
This builds on The Agentic Tipping Point, The Research Flywheel, and Compound Velocity. For the technical implementation details, see the ARIA documentation.