
Compound Velocity: The 20-Hour AI Research Lab
Part 2 of 3: Nine Days of Petaflop Delegation - Building monitoring while fine-tuning while training while documenting while...

Part 1 showed you how delegation works. Strategic human decisions, AI implementation velocity, powerful local compute. That’s the pattern.
But what does it look like when you actually build something?
The answer: you build multiple things at once. Not sequentially. In parallel.
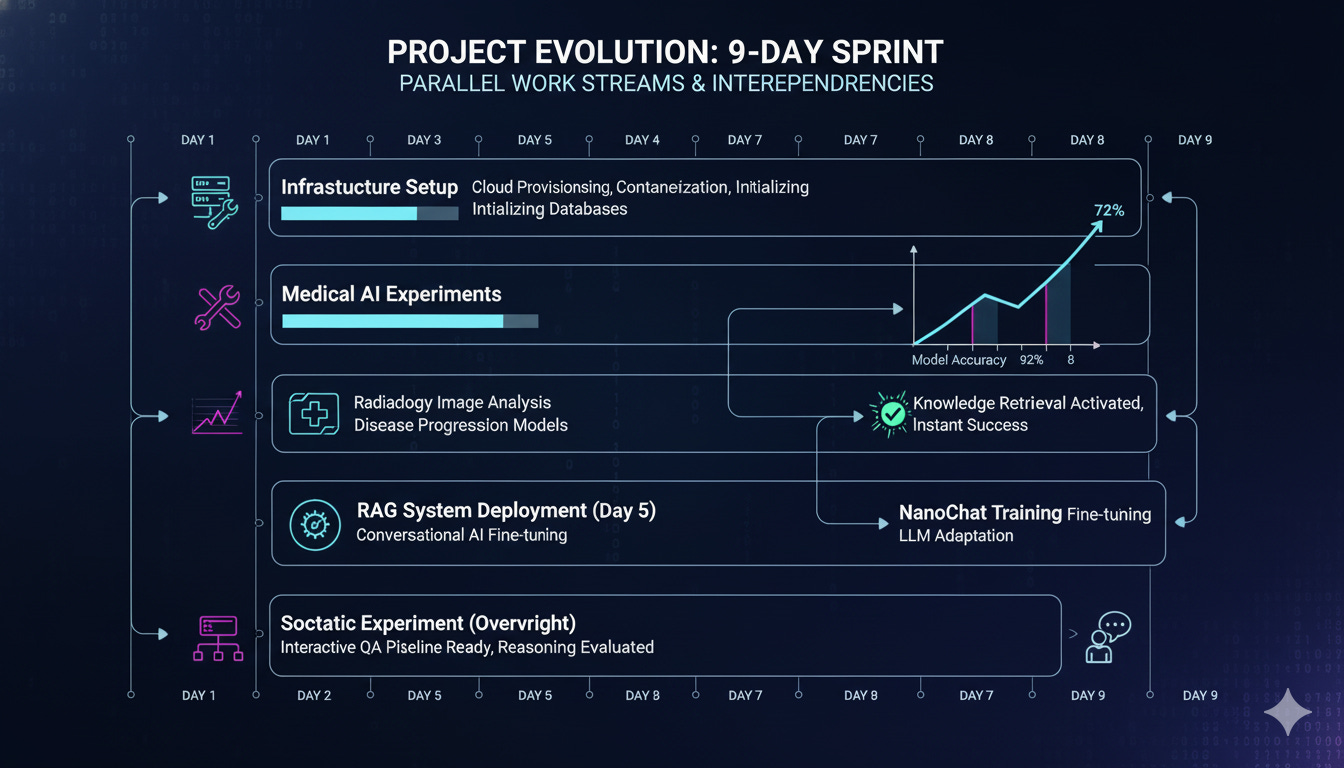
While fine-tuning medical AI models overnight, we were also setting up monitoring dashboards, configuring Docker virtualization, building RAG search platforms, and training language models from scratch. Each system fed into the next. Each experiment taught us something that improved the infrastructure.
This is what nine days of real work looks like.
Building the Foundation in Parallel
Here’s what most write-ups miss: the experiments weren’t happening in isolation. They were happening while we built the entire research infrastructure.
Systems we set up alongside the experiments:
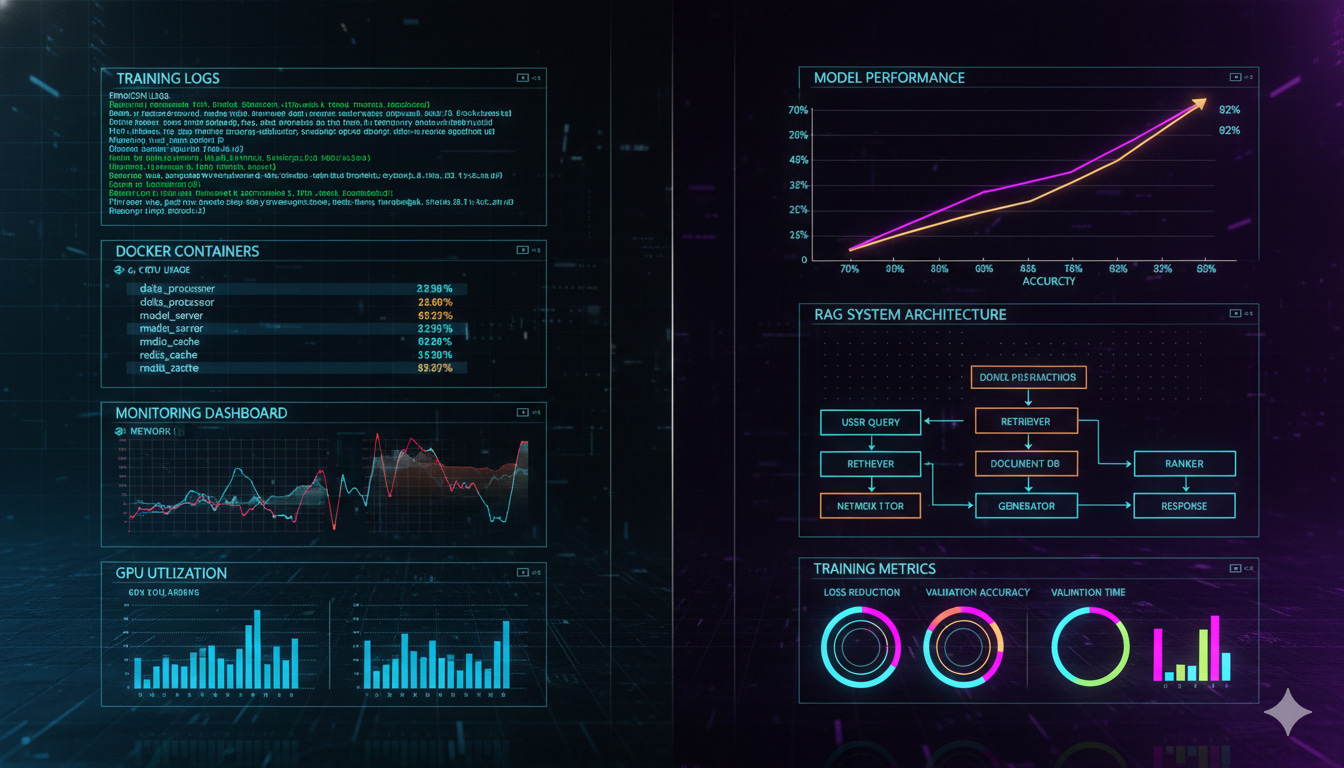
DGX Dashboard - Real-time monitoring for GPU utilization, memory, temperature, power draw. Not just nvidia-smi in a terminal. A proper web dashboard accessible from any device on the network. Built with Python Flask, GPU metrics scraped every 2 seconds, historical graphs for spotting patterns.
Network monitoring - netstat tracking for all inference services. When you’re running Ollama, llama.cpp, Qdrant, and AnythingLLM simultaneously, you need to know which ports are occupied and which services are actually responding.
Weights & Biases integration - Full experiment tracking for every model training run. Loss curves, validation metrics, hyperparameter logs, system resource usage. Not optional extras. Core infrastructure. When you’re running experiments overnight, you need to wake up to complete data, not guesswork.
Docker virtualization - Containerized services for isolation and reproducibility. Qdrant runs in Docker. AnythingLLM runs in Docker. Training jobs run on bare metal for GPU access. Everything properly networked with host.docker.internal bridges.
Intelligent bashrc - 50+ aliases and functions turning complex multi-step operations into single commands. gpu-status shows everything at once. docker-stats monitors all containers. train-status tails the latest training log. These aren’t just conveniences. They’re what makes rapid iteration possible.
Session documentation system - Every single session documented as we worked. Not afterward. During. Templates auto-generated. Session notes structured with objectives, actions, results, next steps. 58 sessions documented. Zero memory loss across days.
This isn’t “setup” versus “experiments.” It’s all one continuous build. The infrastructure enabled the experiments. The experiments revealed what infrastructure we needed. Tight feedback loop.
Medical AI: A System Test
Let’s be clear about what the medical Q&A fine-tuning was: a warm-up. A system test.
Not “production medical AI we’re going to deploy in hospitals.” More like “let’s see if this entire pipeline actually works end-to-end.”
Dataset: PubMedQA. 520 medical questions with yes/no/maybe answers. Small enough to iterate quickly. Large enough to be meaningful. Perfect for testing the system.
The question: Can we take a base language model and fine-tune it for medical domain knowledge? Can we do it fast? Can we measure quality rigorously? Can we document everything as we go?
The answer: Yes. 70% to 92.4% accuracy. Seven experiments over seven days. Statistical validation with p < 0.001. Complete documentation. Reproducible methodology.
But more important than the final number: the iteration process.
The Learning Curve
Experiments 1-3: Baseline establishment. Got to 70-75% accuracy. Learned that starting from a good base model matters. Discovered that LoRA (Low-Rank Adaptation) trains fast but has limitations. Documented hyperparameters that didn’t work.
Experiments 4-6: Testing variations. Different learning rates. Different training durations. Different prompt formats. Incremental improvements. 76-80% range. Good progress, but not there yet.
Experiment 7: Breakthrough. Switched to SFTTrainer (Supervised Fine-Tuning Trainer) instead of raw LoRA. Different approach to fine-tuning. Jumped to 82% accuracy. Now we’re getting somewhere.
Experiment 8: Full validation. 500 test examples. Statistical testing. Cohen’s h effect size calculation. Confidence intervals. P-value under 0.001. 92.4% accuracy. Production-worthy by research standards.
Key insight: Getting started is fast. Getting good takes iteration.
First model trained in a few hours. Decent results immediately. But those extra 10-15 percentage points? That’s where the work is. That’s where the systematic experimentation pays off. That’s where having unlimited local compute matters.
Every experiment cost $0 in cloud fees. Failed approaches didn’t create technical debt or budget anxiety. Try something. Doesn’t work? Pivot immediately. Train overnight. Check results in the morning. Adjust and repeat.
What We Learned About the System
The medical AI experiments weren’t just about medical AI. They were stress tests for the entire infrastructure.
Monitoring effectiveness: Weights & Biases captured everything. Loss curves showed exactly when models converged. We could see overfitting start to happen and stop training early. System resource graphs showed we were using GPU efficiently.
Documentation quality: Each experiment got its own session file. Hypothesis clearly stated. Results captured with statistical rigor. Decisions explained with rationale. When Experiment 7 outperformed Experiment 6, we knew exactly why.
Iteration speed: Setup an experiment in 30 minutes. Start training. Check back 8 hours later. Results ready. Next iteration same day. Traditional ML workflow (wait for cluster allocation, submit job, wait in queue, hope it doesn’t crash) would have taken weeks for seven experiments.
The takeaway: Don’t let one problem block everything. Work around it, keep moving.
RAG in 90 Minutes
I’ve already written about building the RAG research platform in detail. That post covers the technical implementation. I won’t repeat it here.
What matters for this story: we went from “we should have local document search” to “fully operational RAG system with web search integration” in 90 minutes of actual work.
Qdrant vector database. AnythingLLM with AI agents. Document ingestion pipeline. Web research capabilities. Response time: 2-3 seconds. Cost per query: $0.
The real insight: This was only possible because the infrastructure existed. Docker was already configured. Model serving was already running. Monitoring was already set up. Session documentation was already automatic.
Compound velocity. Each project builds on the previous foundation. Time to deployment decreases exponentially.
Training from Scratch: Why It Matters
Fine-tuning is impressive. Starting with a pre-trained model and adapting it to your domain. Most practical ML work is fine-tuning.
But training from scratch? That’s different. That’s building the intelligence yourself. From random weights to fluent language generation. From nothing to something that understands structure and grammar and semantics.
NanoChat: 150M parameter language model. Trained on FineWeb dataset (20 million tokens). Autoregressive training methodology. 15,000 training steps. Eight hours overnight.
Why train a model from scratch when you could fine-tune an existing one?
Educational value. You learn how language models actually learn. You see perplexity decrease over training. You watch the model go from gibberish to grammar to fluency. You understand what’s happening under the hood.
Research flexibility. Want to test a new architecture? A different training approach? A novel optimization technique? You need to train from scratch. Fine-tuning doesn’t let you experiment with model architecture itself.
Resource understanding. Training from scratch shows you exactly what compute is required, what data quality matters, where bottlenecks occur. That knowledge transfers to everything else you build.
Capability validation. Can this DGX actually handle training workloads at scale? Not just “does the GPU work?” but “can I run multi-hour training jobs reliably overnight?” The answer: Yes. Perfectly.
The Overnight Advantage
Setup the training in the evening. Check the configuration. Verify the dataset loaded correctly. Start the training run. Go to sleep.
Wake up eight hours later. Model trained. Checkpoints saved. Logs complete. Loss curves show smooth convergence.
This is the power of local compute. Traditional workflow: submit job to shared cluster, wait in queue, maybe your job runs overnight, maybe it gets preempted, check back tomorrow and hope.
DGX workflow: decide to train something, set it up in 20 minutes, train overnight while you sleep, results ready in the morning. Zero queue time. Zero preemption. Complete control.
Human time decoupled from compute time. Strategic decisions happen during your work hours. Training happens during your sleep hours. You’re productive 24/7 without working 24/7.
Quality assessment: The resulting model (perplexity 59.53) generates fluent, grammatical text. Not production-ready for real applications. But excellent for educational purposes. Demonstrates that the full pipeline works. Validates that we can train any architecture we want.
The Socratic Experiment: Learning to Learn
By day nine, we had proven we could fine-tune models, build RAG systems, and train from scratch. The infrastructure was solid. The workflows were efficient. The documentation was comprehensive.
Time to try something novel.
The idea: Instead of training a small model with direct answers, what if we trained it with progressive hints? Socratic teaching methodology applied to machine learning.
Teacher model (GPT-OSS-20B) generates hints at three levels: Strategic (high-level approach), Conceptual (relevant knowledge), Tactical (specific steps). Student model (nanochat-d20, 561M parameters) learns from the dialogue, not just the answer.
The hypothesis: Small models might learn better from scaffolded reasoning than from direct examples. Like how humans learn better when they figure things out with guidance instead of just being told the answer.
Status at end of day nine: Complete pipeline validated. Baseline evaluation (27% on HumanEval coding tasks). Training data generation running. LoRA fine-tuning infrastructure ready. Everything set up to test the hypothesis properly. Failed miserably.
This experiment wasn’t about immediate results. It was about demonstrating that novel research ideas go from concept to validated pipeline in hours, not weeks. That’s what high velocity research looks like.
The Digital Laboratory Notebook
Here’s what made all of this possible at this pace: we treated the workspace like a sophisticated laboratory notebook.
Traditional science: paper notebooks. Manual entries. Write down what you did, what you observed, what you learned. Maybe do it during the experiment. More likely, reconstruct it afterward. Hard to search. Easy to lose. Difficult to share.
Our approach: Digital laboratory notebook with automatic capture.
The structure:
workspace/
├── experiments/ # Each experiment isolated
│ ├── exp-001/ # Complete setup, data, scripts
│ ├── exp-002/ # Fully reproducible
│ └── exp-008/ # Independent execution
├── logs/ # All outputs captured automatically
├── models/ # Trained checkpoints organized
└── docs/sessions/ # Lab notebook entries
Each session file contains:
Objective: What we’re trying to accomplish
Hypothesis: What we think will happen and why
Method: Detailed steps, code, configurations
Results: Measurements, observations, outputs
Analysis: What it means, what we learned
Next steps: What to do next based on results
This isn’t optional. It’s core infrastructure. Every experiment documented as we work. Not after. Not “we should write this up later.” Concurrent documentation.
Why this is sophisticated:
Reproducibility built-in. Anyone can recreate any experiment. All code. All data. All parameters. All results. Six months from now, we can reproduce Experiment 3 exactly.
Traceability complete. Why did we choose these hyperparameters? Check the session file. What were we thinking when we designed this architecture? It’s documented. What failed approaches did we try? All captured.
Collaboration-ready. Share the session directory. New team member gets complete history. Every decision. Every result. Every lesson. Onboarding time drops from weeks to days.
Publication-ready. Writing the paper? The experimental methodology is already documented. Results are already captured. Graphs are already generated. Just structure it into paper format.
Learning captured. “We tried this in Experiment 3 and it didn’t work.” That knowledge is preserved. We don’t waste time trying the same failed approach twice.
The DGX + Claude combination makes this possible:
DGX runs experiments reliably. No crashes. No data loss. Consistent results. Claude documents automatically while we work. Structures narratives. Organizes findings. Maintains context across sessions.
Result: Laboratory notebook maintains itself. Quality stays high. Velocity stays fast. No trade-offs.
What Velocity Actually Looks Like
Traditional timeline for comparable scope:
Infrastructure setup: 2 weeks full-time
Monitoring and dashboards: 1 week
RAG platform: 1 week
Fine-tuning pipeline with validation: 3 weeks
From-scratch training capability: 2 weeks
Novel experiment prototype: 1 week
Complete documentation: Ongoing, often incomplete
Total: 10-12 weeks of full-time work
Our timeline:
Infrastructure: 3 evenings (8 hours)
Monitoring: Built in parallel (included above)
RAG: 1 evening (1.5 hours)
Fine-tuning: 7 evenings (12 hours hands-on, 60h overnight)
From-scratch training: 1 evening setup (2 hours), 8h overnight
Socratic experiment: 1 evening (2.5 hours)
Documentation: Automatic, concurrent
Total: 12 days, about 20 hours hands-on, complete documentation
Acceleration: 20-24x faster.
But speed isn’t the real achievement. Sustainability is.
No all-nighters. Day job maintained. Quality never compromised. Statistical rigor enforced. Documentation complete. Reproducibility guaranteed. Technical debt: zero.
This is what happens when you combine powerful local compute, intelligent AI collaboration, and focused human expertise. Not working harder. Working differently.
The Meta-Pattern
Four experiments. Nine days. 20 hours of hands-on work. Multiple insights beyond just “what we built.”
Parallel development compounds velocity. Building monitoring while running experiments while documenting everything. Each system enables the next. Each experiment reveals what infrastructure to add.
Free experimentation changes behavior. When trying something costs $0, you try more things. Failed experiments don’t create anxiety. They create learning.
Overnight training is a superpower. Human time focused on strategic decisions. Compute time completely decoupled. You’re productive 24/7 without burning out.
Documentation quality enables velocity. Complete session notes mean zero context loss. Pick up exactly where you left off. No time wasted reconstructing mental state.
System validation matters more than any single result. Medical AI hit 92.4%? Great. But more important: the entire pipeline works. Infrastructure is solid. Methodology is sound. We can build anything now.
What Comes Next
In Part 3, we’ll zoom out. What do 383 messages of collaboration actually look like? What patterns emerge? What surprised me about working with Claude Code at this intensity?
And more importantly: what does this mean for scientific computing? For democratizing ML research? For the future of human-AI collaboration?
The experiments show what’s possible. The collaboration patterns show how it works. Part 3 explores what it means.
Because the real story isn’t the 92.4% accuracy or the 90-minute RAG deployment or the overnight model training.
The real story is that sustainable research velocity, with quality maintained, is achievable right now. Today. With tools that exist.
Not someday. Not after the next breakthrough. Not when the hardware gets better or the AI gets smarter.
Now.
This is Part 2 of a three-part series on building an AI research lab in nine days. Part 1 explained how delegation differs from automation. Part 3 will explore the collaboration patterns and implications for scientific computing.
For infrastructure details, see Three Days, One Petaflop, and an AI. For RAG deployment, see From Petaflop to Production.