
The Research Flywheel: Science That Compounds
Recursive Science, From Paper to Paper with Autonomous Research

I read a paper about speculative decoding (Yeah, I lead a glamorous life). Wondered: what if we tested rejection patterns across different domains? Forty-eight hours later, I had a 5,200-word manuscript with novel findings, five publication-quality figures, and an analysis of 292,917 token-level decisions (Yeah, I’m a nerd).

The AI did most of the work.
Not the thinking. Not the judgment calls. But the execution, the iteration, the tedious parts that usually kill research momentum before it starts.
This is what happens when you stop treating AI as a chatbot and start treating it as a research collaborator.
The Problem With Research Velocity
Papers pile up. Ideas stay untested. The gap between “I should look into this” and “I have results” stretches into weeks, months, never.
The bottleneck is not intelligence. It is execution. Designing experiments takes time. Writing code takes time. Running iterations takes time. Analyzing results takes time. By the time you finish one experiment, you have forgotten why you started.
I wanted something different. A system where reading a paper could lead directly to testable hypotheses, where those hypotheses could become running experiments, where results could feed back into new questions. Automatically. Incrementally. Building on what came before.
The output of one research cycle becomes the input to the next.
What Makes This Possible Now
Two things changed recently that made this workflow viable.
First, Claude Opus 4.5 and Gemini 3 Pro. These models can actually reason through multi-step research problems. They can decompose a vague question into testable hypotheses. They can design experiments with proper methodology. They can analyze results and identify what to test next.
This would not have worked before them. Earlier models could generate code, but they could not think through the research process. The difference is not incremental. It is categorical.
Second, tool calling matured. These models can execute code, check results, and iterate based on what they find. Not just generate text about what they would do. Actually do it.
The combination unlocks something new: AI that can run the research loop autonomously while you focus on the parts that require human judgment.
The Core Concept: Building on Published Science
My approach is simple. Find papers I think are valuable. Ask: how can I build on what they did?
Not reproduce. Extend.
The Autonomous Researcher project by Matt Shumer provided the foundation. An LLM-powered agent that can design, run, and analyze ML experiments. I forked it, added local GPU execution, and built a workflow around incremental research.
Here is how it works:
1. Start with a paper. Something interesting from arXiv. Something with open questions.
2. Identify the gap. What did they not test? What assumptions did they make? What would happen in a different domain?
3. Let the AI decompose it. The system breaks your question into testable hypotheses. Not one experiment. A research agenda.
4. Execute autonomously. Real Python code runs on real GPUs. The agent iterates, analyzes, refines.
5. Synthesize results. The output is not just data. It is a structured paper with methodology, results, and discussion.
6. Publish everything. Code goes to GitHub. Artifacts go to HuggingFace. The work becomes discoverable, reproducible, citable.
Then the cycle repeats. The findings from one experiment inform the next question.
A Concrete Example: Speculative Decoding Across Domains
Let me show you what this looks like in practice.
I read TiDAR: Think in Diffusion, Talk in Autoregression. Interesting paper. Claims 4.7x to 5.9x throughput gains via speculative decoding with a hybrid diffusion-autoregressive architecture.
The code was not released. I could have waited. Instead, I pivoted to a novel question the paper did not address:
When and why do verifier models reject draft tokens in speculative decoding, and how do these dynamics vary across domains?
I fed this to the autonomous researcher. Here is what happened:
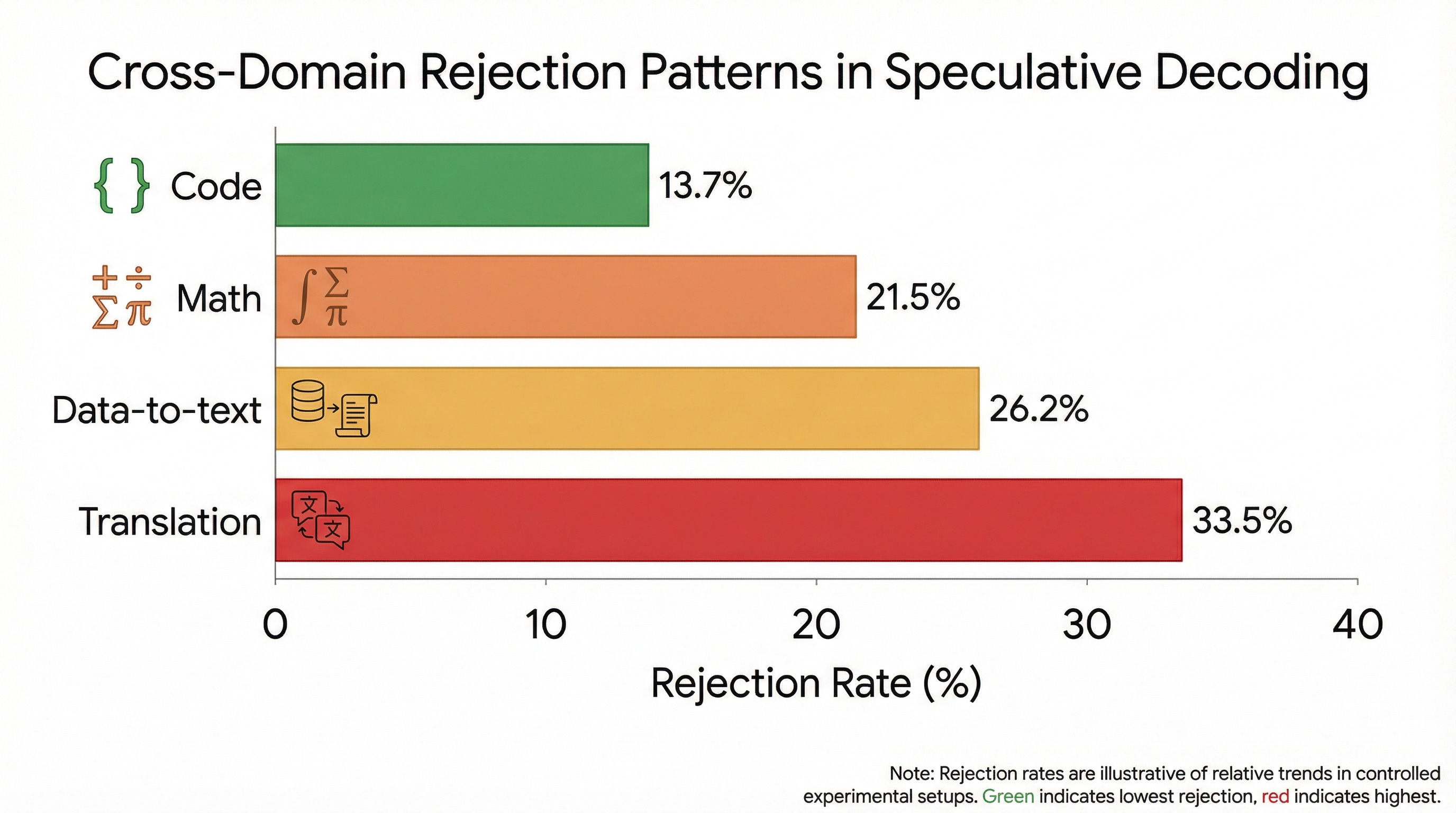
The system decomposed the question into four domain-specific experiments: code generation, mathematical reasoning, translation, and data-to-text.
It designed the methodology: Instrumented speculative decoding using Qwen2.5 models (0.5B draft, 3B verifier). Five different attention mask architectures. Systematic data collection.
It executed the experiments: 292,917 token-level decisions analyzed. Real GPU execution. Real statistical tests.
It produced surprising findings:

The conventional wisdom was wrong. Code generation, with its strict syntax, should be harder to predict. Instead, syntax constraints make draft tokens MORE predictable. Translation, which seems fluent and natural, has the highest rejection rate because semantic choices are less constrained.
The output: A 5,200-word paper ready for submission. Five publication-quality figures. Complete methodology section. Statistical analysis with proper tests.
The Research Brainstormer: From Paper to Experiment Plan
The autonomous researcher handles execution. But what about the planning phase?
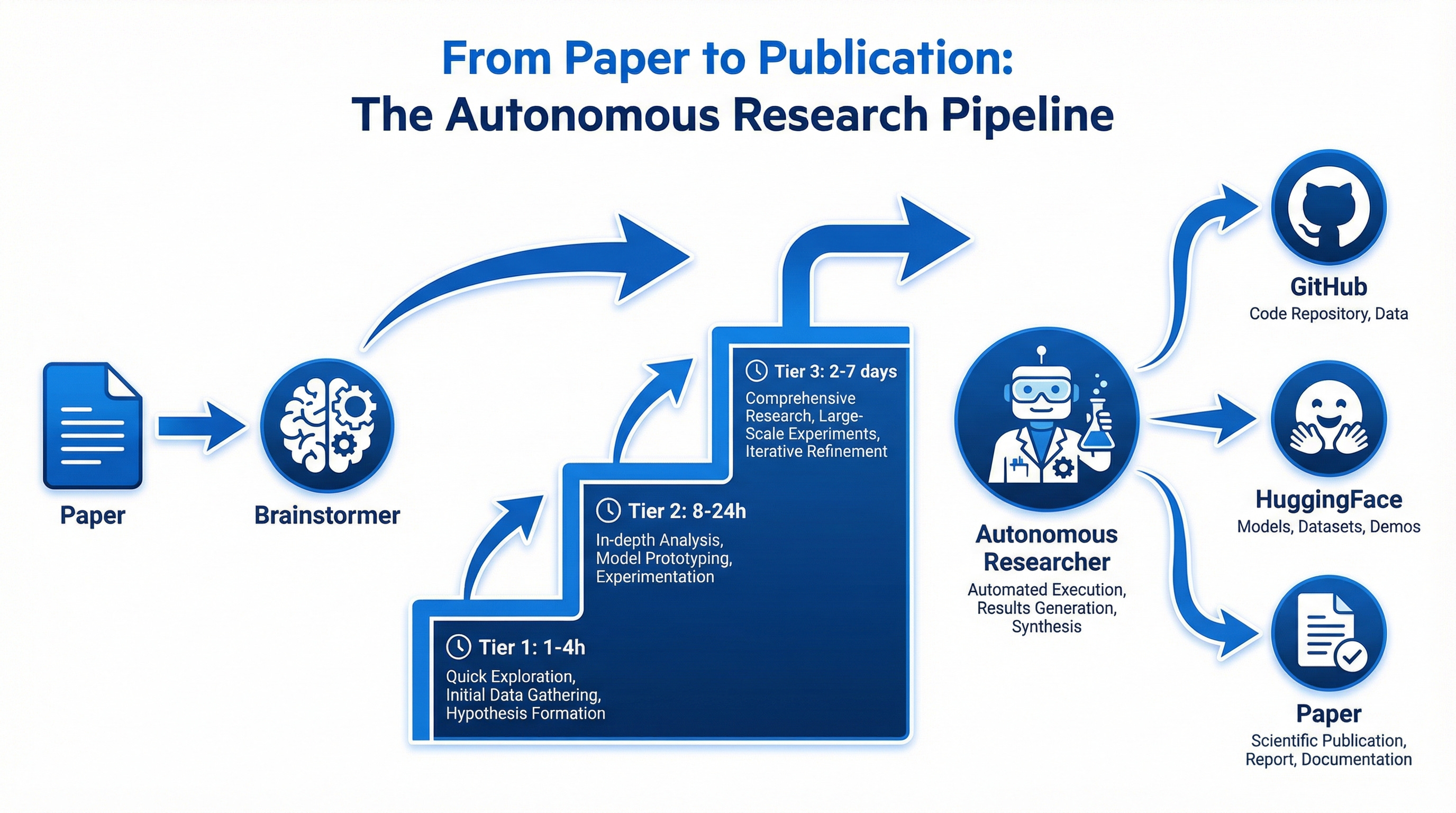
I built a complementary skill in Claude Code called the Experiment Brainstormer. It transforms papers, ideas, or concepts into actionable experiment plans optimized for my infrastructure.
Here is the workflow:
Input: An arXiv URL, a PDF, or just a research idea in plain text.
Phase 1: Analysis. The system extracts key concepts, models, datasets. Computes a clarity score. Identifies what is testable.
Phase 2: Parallel Research. Six threads run simultaneously:
Deep research via Perplexity (state of the art, latest benchmarks)
Web search for comparison points
Check for duplicate experiments in my workspace
GPU resource availability
Infrastructure constraints
Related work in my research archive
Phase 3: Tiered Experiments. The system generates three experiment proposals:
Tier 1 (1-4 hours): Quick validation. Establish baseline. Low risk.
Tier 2 (8-24 hours): Research contribution. Publishable if successful.
Tier 3 (2-7 days): Ambitious exploration. High novelty, high risk.
Phase 4: Refinement. One to three targeted questions. Tier selection. Emphasis areas. Dataset preferences.
Phase 5: Feasibility. GPU memory estimation. Package compatibility checks. Container recommendations.
Output: Two files. EXPERIMENT_PLAN.md with detailed methodology. README.md with quick start instructions.
Total time: under 10 minutes from paper to actionable plan.
Why Incrementalism Matters
The real power is not any single experiment. It is the compounding.
Each experiment produces:
Findings that inform the next question
Code that can be reused and extended
Data that enables meta-analysis
Methodology that improves over iterations
The speculative decoding work led to questions about attention mask architectures. Those experiments will inform work on domain-adaptive inference. Each cycle builds on the last.
This is how research actually progresses. Not through isolated breakthroughs, but through systematic accumulation. The AI handles the accumulation. I handle the direction.
The Publishing Workflow: Open Auto Science
Every successful experiment gets published. Not because I am altruistic. Because publishing creates value.
Discoverability. Others can find and build on the work.
Reproducibility. Code and data available for verification.
Attribution. Contributions documented and citable.
The workflow is simple:
During execution: The agent automatically uploads artifacts to HuggingFace. Models, datasets, intermediate results. Everything tagged with autonomous-researcher for filtering.
After completion: A helper script pushes code to GitHub. Cross-links everything. Updates model cards with repository links.
Naming convention:
HuggingFace:
RyeCatcher/[topic]-[method]-[date]GitHub:
BioInfo/autonomous-researcher-[experiment-name]
The speculative decoding work is at:
Paper and analysis: GitHub: autonomous-researcher-speculative-decoding
Data and artifacts: HuggingFace: RyeCatcher/speculative-decoding-analysis-20251130
The Z-Image quantization benchmark:
Negative Results Are Results
One of my experiments produced a finding that surprised me.
I was benchmarking Z-Image, Alibaba’s 6B parameter diffusion model. The question: how does quantization affect performance?
The expected answer: INT8 should be faster than FP16 with minimal quality loss. Standard optimization story.
The actual finding: INT8 is 36% slower than FP16.
PrecisionLatency (1024x1024)MemoryFP169.95s23.27GBINT813.57s (+36%)Higher
Why? The 4-step Turbo scheduler is already highly optimized. Quantization overhead outweighs compute savings. The model is memory-bound, not compute-bound.
This is a valuable negative result. It tells practitioners: do not quantize Z-Image-Turbo. You will make it slower.
Traditional research incentives bury negative results. They do not get published. They do not get cited. But they save everyone else from wasting time on the same dead end.
The autonomous workflow publishes everything. Positive, negative, inconclusive. All of it goes to HuggingFace. All of it becomes searchable.
What This Is Not
Let me be clear about limitations.
This is not AGI doing science. The AI cannot identify which questions are worth asking. It cannot evaluate whether findings are important. It cannot navigate the social dynamics of peer review.
This is not a replacement for domain expertise. You need to know enough to ask good questions and evaluate whether the answers make sense.
This is not fully autonomous. I review experiment plans before execution. I read the papers before deciding what to extend. I make judgment calls about what to publish.
What it is: a force multiplier. The AI handles execution. I handle direction. Together, we move faster than either could alone.
The Bigger Picture
I think about this as a preview of how research will work in five years.
Not AI replacing scientists. AI augmenting scientists. Handling the parts that are tedious but necessary. Freeing humans to focus on the parts that require creativity and judgment.
The output of one experiment becomes the input to the next. The cycle accelerates. The accumulation compounds.
We are not there yet. The tools are rough. The workflow requires technical sophistication. The models make mistakes that require human correction.
But the direction is clear. And the gap between “I wonder if...” and “here are the results” is shrinking.
Links and Resources
My Fork:
Original Project:
My Experiments:
Papers Referenced:
HuggingFace Profile:
The future of research is not AI replacing scientists. It is AI handling the execution while humans handle the direction. The output of one experiment becomes the input to the next. The cycle accelerates. The accumulation compounds.