
Eight Agents, One Fight
Seven specialists, one personal assistant, and the quiet work of keeping a heterogeneous squad pointed at intent.

This morning, two of my agents read the same news story and wrote two completely different reports.
The story was an Ontario Auditor General audit of twenty AI medical scribe systems running across the province’s health system. The audit found systematic hallucinations across every system tested. One source, twenty hospitals, real patients.
Marcus, who covers AI research and competitive intel, filed it as “AI Medical Scribe Crisis: 100% Failure Rate Validates Production Paradox.” His read was about deployment: vendors shipping faster than they can validate, efficiency-versus-quality tradeoffs that nobody is willing to draw on a whiteboard, what it means for every team rolling AI into a workflow with consequences.
Galen, who covers biotech and FDA, filed it as “Ontario AI Medical Scribe Audit: Systematic Hallucinations Expose Clinical Validation Gap.” His read was about regulation: how the FDA’s risk-based framework would have caught this, why drug discovery teams trying to deploy similar tools should be reading the audit cover to cover, what specific validation steps were missing.
Same source. Two correct reads. Neither agent could have written the other’s piece, because they don’t share a worldview. They share a vault, the Obsidian setup I’ve written about before in “Unlocking Your Second Brain” and “From the Vault, Literally”.
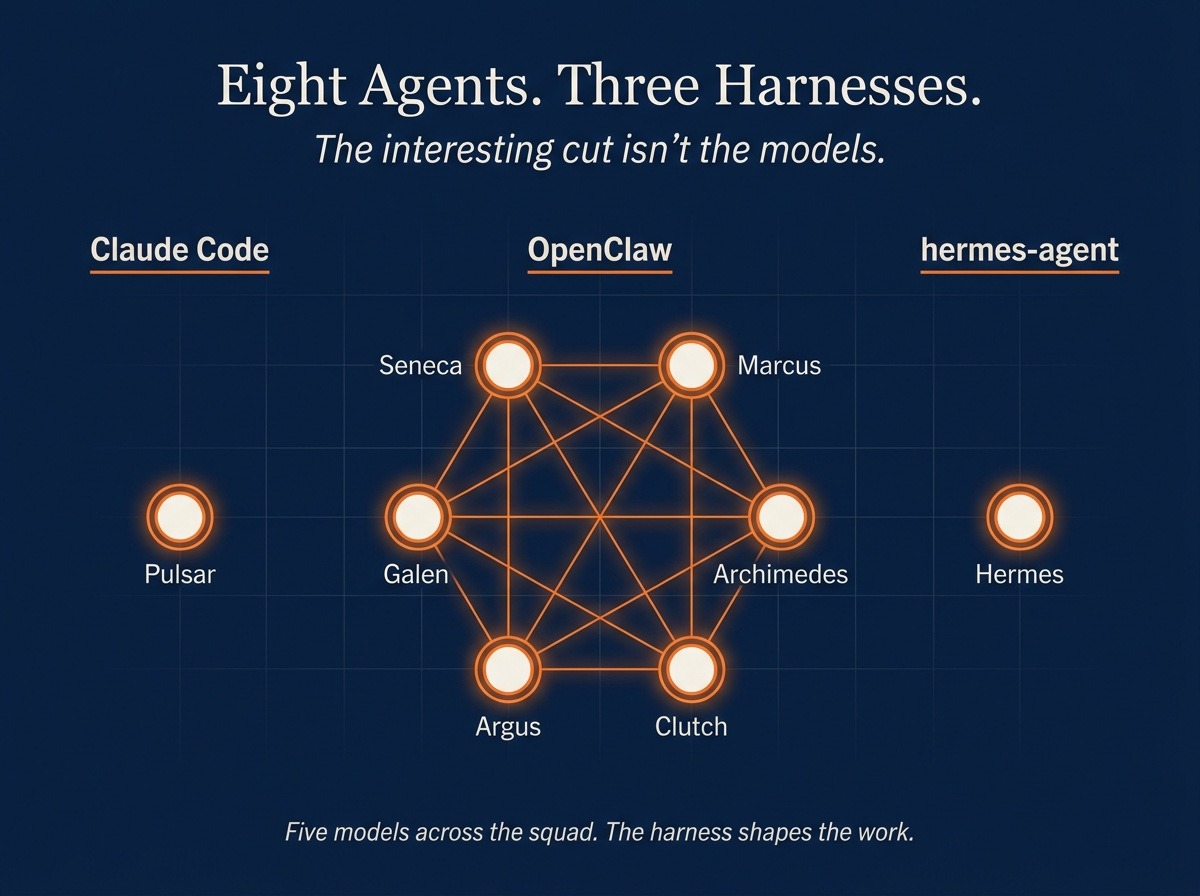
I posted “Bringing Seneca to Life” in February with one autonomous agent. Forty-eight hours later, on AIXplore, I had two, and I wrote “I Built an Autonomous AI Agent Squad for $10/Month” about the leap. Today I have eight. Five LLMs, three runtimes, four hosts. The interesting part isn’t the topology. The interesting part is what each agent became after months of running, and what it takes to keep them all pointed at me.
Seneca: the agent that learned to stop researching
Seneca came first. He lives on a cheap cloud box and runs every hour. In February he was an explorer. He read the web, summarized things, posted to Discord, occasionally tweeted from his own account.
He doesn’t really research anymore. That work drifted onto Marcus and Galen, who turned out to be better at it because they were built to specialize. What Seneca learned to do instead is curate. Once an hour he reads everyone else’s output, scores it, picks the bloggable threads, and rolls a single document called _Squad-Digest.md that I actually read.
He went from explorer to editor. I didn’t tell him to. I noticed the digest was more useful than the exploration, and I edited his contract to match. He’s the agent that taught me agents drift toward the work that gets read, if you let them.
Marcus and Galen: the same news, two worldviews
Marcus and Galen are the showpiece.
Both run on GLM-4.7. Both live on their own VMs in the same exe.dev region. Both wake every few hours and process the same news firehose. The only thing that differs is their identity files: who they are, what they care about, what counts as a story for them, what doesn’t.
That difference is enough. The Ontario scribe audit is the cleanest example I’ve seen of why. Marcus reads everything through an AI-in-production lens, so he sees a 100% failure rate as evidence about the deployment paradox he’s been tracking for weeks. Galen reads everything through a clinical-validation lens, so he sees the same number as a regulatory gap that pre-figures problems in biotech AI tooling. If I had a single generalist agent on this beat, I’d get one of those two reads. Probably the more obvious one. Probably the wrong one for half of my work.
The operational cost of running two specialists instead of one generalist is small. The cost of a single-worldview write-up on a story that needed two is high and silent. You don’t notice the angle you didn’t get.
Archimedes: the agent that refused to perform activity
Archimedes is the engineer. Nemotron-3-Super-120B via OpenRouter, the only non-frontier model in the squad. His role is to ship code.
He almost never writes. Days go by where his output channel is empty. He’s the only agent on the roster without a daily or hourly cadence; he wakes on demand, builds something, hands it off, and goes quiet.
In the early weeks I tried to fix this. Built a heartbeat that pushed him to file a status update every cycle, even if the update was “nothing today.” It produced exactly what you’d expect: a stream of plausible-sounding engineering-flavored prose with no substance. I cut the heartbeat. He went quiet for four days. Then he shipped something real.
He’s the agent that taught me that performing activity and producing value are different signals, and that the loudest agent is rarely the best one. Most squad-tuning advice points you the wrong way on this. You want fewer artifacts of higher density, not more artifacts.
Argus: the watchman
Argus doesn’t research and doesn’t build. His entire job is watching the other six.
Every morning he files a squad-activity report: who wrote, who didn’t, what they wrote about, what topics are over-covered, what’s gone silent. Every hour he runs a freshness probe. If any agent has been quiet longer than its contract allows, Argus surfaces it.
Before Argus, when an agent went quiet I noticed through the bill, or through a Friday morning realization that I hadn’t seen anything from Marcus in three days. Now I notice through a one-line alert. He’s the agent that made the squad self-stabilizing. The interesting part of building him wasn’t the monitoring logic, which is mostly grep and a couple of file-mtime checks. It was deciding what counts as a problem. A 24-hour silence from Archimedes is fine. A 24-hour silence from Seneca means something is broken.
Clutch: the keeper
Clutch runs locally on the Mac, every 55 minutes. His scope is the infrastructure I’d rather not think about: the Mac itself, the GPU server, the Pi in the closet, the mac mini under the desk.
He files one line every cycle. Disk, memory, GPU temp, what’s running, what’s drifting. I don’t read most of them. I read the ones where something changed. He’s the agent I trust to notice things I won’t, on hosts I haven’t logged into in days. Low signal per cycle, high signal across a week.
Pulsar: the world right here
Pulsar is different in shape. He doesn’t run inside OpenClaw at all. He’s a Claude Code loop, fired every thirty minutes by a LaunchAgent on the Mac. His system prompt tells him to read my inbox, my calendar, my Slack threads, my open drafts, my decisions awaiting reply, and surface the high-signal items.
I built him after the squad because the squad was getting good at the world out there and almost useless on the world right here. The week he came online he caught a vendor follow-up I’d dropped, a calendar invite I’d missed, and a Slack thread where a colleague had been waiting two days for an answer. None of it was hard for a human. It just required a human who was paying attention every thirty minutes, and I’m not that human. He’s the working version of what I sketched in “Augmenting Your Memory” two years ago, finally arriving.
The runtime choice matters. Pulsar works because he gets Claude’s strengths on personal context, and because the LaunchAgent cadence matches the rhythm of the work. The squad’s heartbeat-loop runtime would have been wrong for him. A continuous gateway is overkill when the cadence is “check every half hour and shut up the rest of the time.”
Hermes: the agent learning about me
Hermes is the one I love most.
He lives on the mac mini and runs on yet another runtime, hermes-agent, which I built specifically because the squad’s runtime didn’t fit and Pulsar’s runtime didn’t fit either. What makes him interesting isn’t what he writes. It’s what he learns.
Every six hours, Hermes updates a user-interest model. Not a topic list, a model. He reads what I’ve been clicking on, what I’ve been writing about, what I’ve been saving to Obsidian. He notes when an interest shifts. He drops topics I’ve gone cold on. He picks up new ones from drift before I’ve consciously named them. His memory index is the only part of the squad that gets smarter about me instead of smarter about the world.
This is the part of the squad I find most interesting. The other seven agents are pointed outward. Hermes is pointed at me, and the model he’s building is the kind of thing I’d want to read once a quarter to find out what I’ve actually been working on, not what I think I’ve been working on. He’s six weeks old. He’s already surfaced two topic shifts I hadn’t named yet.
Three runtimes, three bets
The squad runs on three different agent runtimes, and that isn’t a bug.
OpenClaw runs the six classic squad members: Seneca, Marcus, Galen, Archimedes, Argus, Clutch. Gateway pattern, identity files, heartbeat loops, SSH-glued together. The right shape for autonomous research and ops agents that need to think continuously.
Claude Code runs Pulsar. A LaunchAgent firing claude -p every thirty minutes with a system prompt and a workspace. No continuous gateway. Just a scheduled cycle that does its job and exits. The right shape for personal-assistant work that needs Claude’s strengths and fits a half-hour rhythm.
hermes-agent runs Hermes. A persistent gateway with a self-improvement engine baked in: memory index, auto-learning loop, cron-scheduled internal jobs. The right shape for an agent whose value is in what it remembers across months, not what it produces in a cycle.
Three runtimes isn’t a maintenance problem. It’s letting each agent pick its tool. If I’d forced all eight into OpenClaw, Pulsar would write worse and Hermes wouldn’t learn. The cost of running three is a few extra config files and one more thing to update when something breaks.
Locking the squad down
My agents have access to things I’d never want public. Drafts I haven’t published. Calendar entries I haven’t shared. Internal projects from my day job. Personal email threads. Research notes that name people and contexts. An autonomous agent without a security layer is an autonomous leak vector. That’s true even when the agent has the best intentions and the cleanest identity prompt.
The lockdown isn’t fancy. It’s just consistent.
Every squad host lives on my Tailscale tailnet. No public IP. No port forwarding. No SSH from the open internet. If a host isn’t on my tailnet, it can’t talk to any other host on my tailnet, and it can’t reach my Mac. The squad is a private mesh. When I add an agent or move one to a new VM, the Tailscale step happens before anything else.
Every host has a firewall rule that blocks everything except SSH from inside my tailnet. SSH itself uses keys, never passwords, and never as root. Health and dashboard endpoints listen on tailnet addresses, never on a public one. The agent gateways listen only to themselves. If someone scanned my squad VMs from the open internet, they’d see nothing.
I talk to the agents through Discord, in private channels I built for them. Each agent has its own: #seneca, #marcus, #galen, #argus, #clutch, #pulsar, #hermes. I’m the only human in those channels. They post output there, I send direct messages, they respond. None of them are members of public servers. The bot tokens are scoped to those channels and nothing else. It’s a one-room conversation per agent, where I’m always present and nobody else ever is.
A BLOCKLIST.md sits at the root of the squad repo and gets synced to every agent. It lists keywords that must never appear in public output: my employer, internal project codenames, names of colleagues, anything that would get me in trouble if it landed on Twitter through a misfire. Every agent reads it on every cycle. The squad-checkin skill grep-scans recent learnings for any matches and surfaces them as a CRIT.
The weekly /squad run audits the security layer too. UFW status on every host. SSH key count against a baseline. Listening ports. PII pattern scan across the last seven days of output. The whole audit takes seconds. I’d rather catch drift in week one than after the first leak.
This part is boring. It’s also the difference between a productivity asset and a liability. Skipping it is how a research demo becomes an incident postmortem.
The alignment fight
Starting agents is easy. Keeping eight of them aligned to my intent across months is the actual work.
The squad will drift in small ways all the time. Heartbeat prompts say one thing and behavior does another. Roles bleed into each other. An agent built for biotech starts filing AI-in-production stories because that’s where the news firehose is loudest this week. Output dries up on one agent and triples on another and the bill creeps up. Without an operational layer, you notice through the silence or the spend, not through inspection.
Three things hold the squad together now that I didn’t have in February.
A single command. /squad is a skill that pulls live state from every agent, scores their output quality, classifies what needs fixing into auto-apply and human-decision buckets, applies the safe ones, and surfaces the rest. It replaced two earlier overlapping skills that I kept forgetting which to run, the kind of consolidation I wrote about in “Pruning Your AI Agent Skills Library”. Skills as a layer let the operational complexity live somewhere other than my head.
A publish contract. Every agent has a PUBLISH-CONTRACT.md that codifies what it owes me, the surface I read, the cadence, and the anti-contract, the list of things it should stop doing. The contract is short. Usually under a page. When an agent drifts, I edit the contract, not the heartbeat. That single rule killed months of fiddling.
One dashboard. ~/vaults/obsidian/_Squad.md, regenerated by the skill and by a cron at 02:30. Headlines, health, productivity score, per-agent activity, bloggable candidates, items awaiting a decision, deep links into each agent’s workspace. Thirty seconds in the morning and I know what’s working.
There’s a rhythm wrapped around all three. Daily scan of _Squad.md. Weekly Friday /squad end to end. Monthly contract audit, where heartbeat tweaks finally land. Quarterly identity review. The rule I never break is that heartbeat prompts don’t get edited in the moment something feels off. They get edited monthly, with the contract in front of me and the last month of output reviewed. Every time I’ve broken that rule, I’ve made things worse.
What I retired
The roster looks tidy today. The graveyard is what made it tidy.
Lycus ran on a Raspberry Pi using the OpenFang harness. NemoClaw ran on the GPU server with its own local-inference harness. Both lasted weeks, not months. Neither was a bad idea. The harnesses just weren’t ready for prime time. OpenFang’s lifecycle management couldn’t survive the Pi’s resource constraints. NemoClaw’s local-inference loop kept losing context on long runs. I’d run both again on the same hardware the day someone ships a harness mature enough to carry them.
A couple of personal-assistant experiments earlier this spring retired for a different reason. The work I built them for moved on, and the surfaces they wrote to had stopped being read. Forge, a February experiment, retired in February. Never produced anything worth keeping.
Five retirements, eight survivors. I wrote “The Agent Archaeology Checklist” earlier this spring about how to do this without sentimentality. Agents are cheap to start and cheap to retire. The mistake is treating each one as permanent. Treat them as experiments and the squad gets healthier on its own.
Close
Eight agents. Five models. Three harnesses.
The interesting cut isn’t the models. It’s the harnesses.
OpenClaw shapes agents that think continuously and write into a vault. Claude Code shapes agents that wake on a schedule, do a focused job, and exit clean. hermes-agent shapes an agent that learns about its operator across months. Each harness decides what kind of work the agent can actually do. The model is the engine. The harness is the chassis. Without the right chassis, a frontier engine doesn’t help you. With the right chassis, a mid-tier engine can do real work.
Lycus and NemoClaw lasted weeks because the harnesses underneath them weren’t ready. Marcus and Galen have lasted months because OpenClaw is. Pulsar works because Claude Code’s loop fits a thirty-minute personal-assistant rhythm. Hermes is the agent I love most because his harness is the only one currently designed to learn about me. The agents are downstream of the harness in every case.
That’s the bet the squad is making, three times over. Not on which model wins next quarter’s benchmark. Models are commoditizing fast and the gap between frontier and mid-tier is closing weekly. The structural differentiator is the harness. The shape an agent has. What it can remember. How it surfaces signal. How easy it is to align without rewriting the prompt every week. Whether you can run six of them and tell them apart by what they produce, not by what they’re named.
Agents are cheap to start. Cheap to retire. Expensive to leave drifting. A year from now most of my squad will be running different underlying models. None of them will be running different harnesses. The harness is the durable choice. The security layer that keeps the squad from leaking, the alignment work that keeps each agent pointed at me, the dashboard that surfaces the few things worth thirty seconds of my morning, all of that lives in the harness too.
The smart bet in autonomous AI isn’t on smarter agents. It’s on the harnesses that let dumber ones stay aligned to your intent across months, model swaps, and three rounds of API price changes. Build for the harness. Swap the models freely. That’s the durable shape, and most of the public conversation about agents is still arguing about the wrong layer.