
From the Vault, Literally

Every Sunday I pick one paper or release that’s worth your time, break it apart, and tell you why it matters. No hype. No summaries of summaries. Just the idea, explained.

VentureBeat ran the headline this past weekend: “The RAG era is ending for agentic AI.” Pinecone, the company that ran the original RAG playbook, announced Nexus a few days earlier and called it a “knowledge engine.” The framing is that retrieval-augmented generation is finished and a new compilation-stage layer is what comes next.
That headline is the lazy frame.
The version actually shipping in production tells a different story. Naive RAG is dead. Sophisticated RAG is thriving. The pattern that keeps catching headline writers off guard is hybrid retrieval plus reranking on top of curated assets, not vector dumps fed by raw web crawls. That isn’t an ending. It’s the boring version that keeps working.
I had a small personal version of the same shape over the past week. I patched my Obsidian vault’s retrieval layer with Anthropic’s contextual-retrieval technique, ran the harness across the whole vault overnight, and watched the recall numbers move by less than a tenth of a point. A weekend of compute, a hundred dollars of API spend, zero lift. Then I hardened the eval set, swapped the embedder underneath, ran it again, and watched recall jump more than eighteen points for zero dollars. Fourteen months earlier, I had shipped a markdown RAG that didn’t even use vector embeddings.
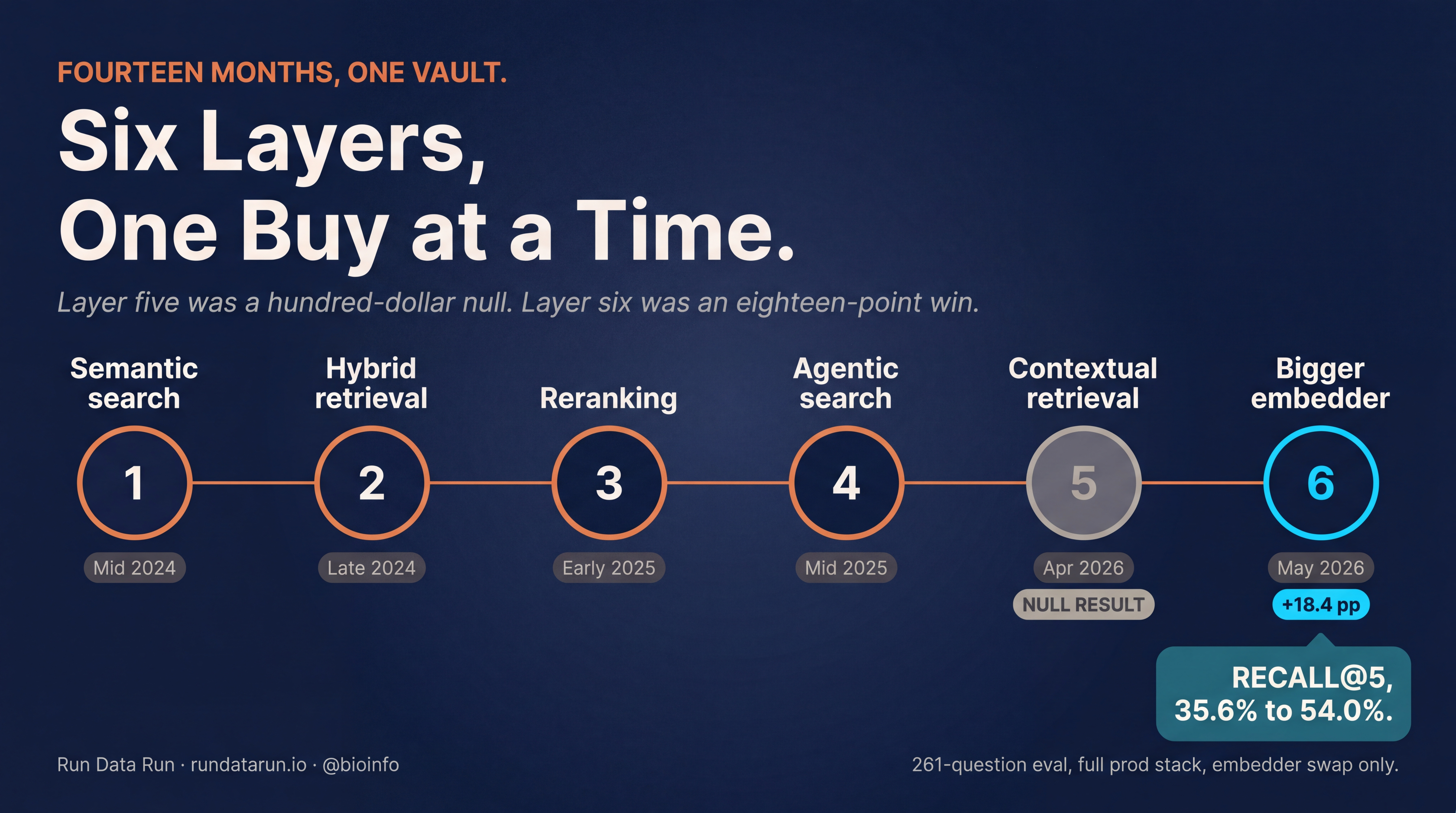
One vault. Six exposure layers in fourteen months. Same data underneath. Each layer bought something the last one missed. The fifth layer didn’t help, and that’s how I knew where the sixth one had to go. None of them touched the asset.
The vault is the brain. The retrieval layer is how the brain talks to the rest of the work. The exposure layer kept changing because the world kept giving it better ways to listen. The brain itself didn’t move.
That’s the post.
Where I started, March 2024
In March 2024 I published a piece on AIXplore called Building a Markdown RAG System. The opening framing tells you everything about the era:
“avoiding the complexity of vector databases while maintaining high-quality responses.”
That was the pitch. Fuzzy keyword search over five hundred markdown files, in-memory cache, reprocess once an hour. It worked at that scale. For the size of the brain I had, it was the right shape.
The 500 files lived in Obsidian. They still do. The vault is now at 28,264 notes.
What Obsidian gives you on top of plain markdown is a development environment for the brain. Backlinks, queryable frontmatter, a graph view that maps how concepts connect, more than fourteen hundred plugins. A few of those plugins I wrote myself by asking Claude Code for them. The harness compounds through the platform. I find a workflow gap, ask Claude Code for the plugin that closes it, and the vault has a new affordance overnight. The asset gets denser. The retrieval has more to work with.
The thing I had right at the start was the asset itself. Markdown files, structured folders, frontmatter I could trust, source citations baked into every answer the system returned. The retrieval layer was simple because the underlying data was already disciplined. The thing I had wrong was assuming keyword search would scale with me.
It didn’t. By a few thousand notes the search started missing the queries I cared about. Concept queries returned reasonable results. Specific facts came back attached to the wrong note. Orphan queries, the ones where the search words never appear in the target document, just failed.
The asset had compounded. The exposure layer needed to catch up.
Six layers, one buy at a time
Six steps over fourteen months. The first five were different ways for the brain to be heard. The sixth was a better way to listen.
Step one. Semantic search. I replaced keyword search with embeddings. The system stopped looking for matching words and started looking for matching meaning. Notes that talked around a concept without using the literal search words finally surfaced. The tradeoff: notes the old keyword search would have caught (exact phrases, file paths, anything where the literal word was the point) sometimes slipped. Net positive on breadth. Net negative on precision.
Step two. Hybrid retrieval. I kept the new semantic search and put the old keyword search back beside it. Both ran on every query, and the system blended their scores into a single ranking. Specific facts came home. Concept queries kept their breadth. This is what “modern RAG” actually means in production in 2026, even though most demos still ship the simpler version and call it good enough.
Step three. Reranking. I added a second pass. The first pass picks twenty candidate notes. The second pass is a small model that reads the query and each candidate together, side by side, instead of comparing them as separate fingerprints. It reorders them based on how well they actually answer the question. The note I wanted started showing up at rank one instead of rank seventeen.
Step four. Agentic search. For multi-hop questions the system started decomposing the query into pieces, retrieving for each piece, and assembling the result. What was the throughput of the model I ran in March on a four-GPU node? That sentence has three sub-questions inside it. The agentic layer made the vault feel less like a search box and more like a colleague who could chase a thread.
Step five. Contextual retrieval. This past weekend. Anthropic’s technique, published in September 2024. Before any chunk of a note gets indexed, a small model writes one sentence describing what the chunk is about given the whole parent document, and that sentence gets prepended to the chunk. The orphan chunk inherits its parent’s context (project name, date, participants, topic) before it ever hits the index. It stops being an orphan.
I ran it on Gemini Flash Lite, prompt caching turned on, full reindex of the 28,264-note vault in one overnight pass. Total cost: under twenty dollars. The technique itself is eighteen months old. The economics that make it trivially affordable are about twelve months old. Most enterprise teams are still using a 2024 cost model to evaluate a 2026 technique.
Step six. A bigger embedder. This past Tuesday, after layer five came back with nothing. Swap nomic-embed-text-v1.5 (137M parameters, 768 dimensions, the workhorse for the past year) for Qwen3-Embedding-8B (8B parameters, 4096 dimensions, currently near the top of the MTEB retrieval leaderboard), running locally on a DGX Spark via LiteLLM and Ollama. Asymmetric usage convention: an instruct prefix on every query, no prefix on the indexed documents. Three and a half hours of GPU time to reindex the vault. Zero dollars of API spend.
The first five layers were better ways for the brain to be heard. The sixth was a better representation of the brain itself.
The numbers
The benchmark is 115 questions across the full 28,264-note vault. Specific-fact, concept, and orphan queries. The orphan slice is where the literal search words don’t appear in the answer document, and it’s the one most enterprise RAG demos skip.
I ran the contextualized index against the 115-question set overnight. Then I ran the un-contextualized index, the old prod stack untouched, against the same 115 questions. I expected a clean before-and-after with the contextualization doing visible work.
The two collections scored identically.
The contextualized index hit 67.9% recall@5, 75.9% recall@20, 0.613 MRR, 37.5% on the orphan slice. The un-contextualized old prod stack hit 67.9%, 75.9%, 0.612, 37.5%. A weekend of contextualization, every chunk in the vault rewritten with parent context, and the recall numbers moved by less than a tenth of a point. Inside the noise floor.
That was not the post I sat down to write.
The first instinct was that I’d broken the eval. I checked. The numbers were right. The second instinct was that contextualization just doesn’t work, which is wrong. It works on the corpora it was designed for. The third instinct was the right one: my corpus wasn’t one of those.
Why it didn’t move
The technique works by teaching a chunk where it lives. Strip a paragraph out of a fifty-page legal filing and it reads as an orphan. The contextual prepend is a one-sentence breadcrumb that tells the indexer “this chunk is from the Phoenix project status note, July 2025, written after the model swap.” Without the breadcrumb the embedder has to guess. With it, the embedder gets the parent’s context for free.
That’s the gap the technique closes. My problem was that I had already closed it.
Four reasons it didn’t move, all of them obvious in retrospect.
The headline number isn’t measured against a system like mine. Anthropic’s 49% and 67% failure-reduction figures are measured against the simplest possible baseline. Their own ablation, the part of the paper where they isolate exactly what contextualization adds on top of a hybrid plus reranker stack like the one I was already running, lands at one to three percentage points. Twenty-six points was never on the table. What I saw, zero, is inside the noise floor.
My chunks already carried the context the technique tries to inject. Old prod ships every chunk with the file path, the title, and a type tag. The reranker reads those before it scores anything. It already knew “decided to ship Tuesday” came from a Phoenix project note. Anthropic tested on long financial filings and code repos where chunks are floating fragments without that scaffolding. Six years of curated markdown gave my index everything contextualization was trying to add.
The reranker is doing more work than the technique it was trying to help. The reranker is a small model that reads each candidate chunk and the question side by side and reorders them by how well they actually answer. Recent benchmarks put it at seventeen percentage points of lift on its own. By the time it runs on my vault, the contextual prepend has nothing left to add.
My vault is the inverse of every axis where contextualization lifts. Long fragmented documents, high vocabulary overlap between chunks, no metadata in the payload, no hybrid plus reranker baseline, dense code repositories. My vault: the opposite on every row.

Zero for five. The technique was designed for everything my vault isn’t.
This is the lesson worth carrying out of the post, and it gets sharper the moment a leader starts pairing a knowledge base with autonomous agents.
The problem I described at the top of this piece, where keyword search worked at five hundred notes and started missing queries by a few thousand, is the same shape every team hits when they put an agent on top of their data. The vault compounds. The agent reads from it constantly, not occasionally. Every gap in the retrieval layer becomes a gap the agent acts on. The retrieval problem doesn’t go away when you add an agent. It gets bigger and faster.
Whether a celebrated upgrade helps your system depends entirely on what shape your asset is in. The same technique can be an eighteen-point lift or a hundred-dollar null result. Read your own corpus before you read the leaderboard. That’s true when a human is the reader. It’s more true when an agent is.
I should have read the field before I ran the spend. Anthropic’s appendix is forty pages of benchmarks broken out by exactly the axes above. The signal was all there. Lesson, expensively learned: read the ablations before you read the headline.
Then I ran the bigger embedder
The contextualization null was the diagnostic. My chunks already carried context. My reranker was already extracting it. The technique had nothing left to add. That left exactly one place the bottleneck could be: the embedder itself.
The embedder is the part of the stack that turns a note into a fingerprint of its meaning. Two notes with similar fingerprints get retrieved together. A small embedder makes a coarser fingerprint. A bigger embedder makes a finer one. Same chunk, smarter reader.
I swapped a 137-million-parameter workhorse (the model that had been running production for the past year) for an 8-billion-parameter model (currently near the top of the public retrieval leaderboard), running locally on a DGX Spark. Same chunks. Same reranker. Different reader. Three and a half hours of GPU time on hardware I already had. Zero dollars of API spend.
While I was wiring the swap up, I also hardened the eval. The old 115-question benchmark was easy: production scored 67.9% against it, which made every change look small. I rebuilt it at 261 questions, deliberately overweighting the queries that broke production most often. Orphan queries where the search words don’t appear in the answer document. Multi-hop queries that need to chase three facts in sequence. Adversarial wording. Against the harder set, production rebaselined at 35.6%. A benchmark you can’t lose against isn’t a benchmark.
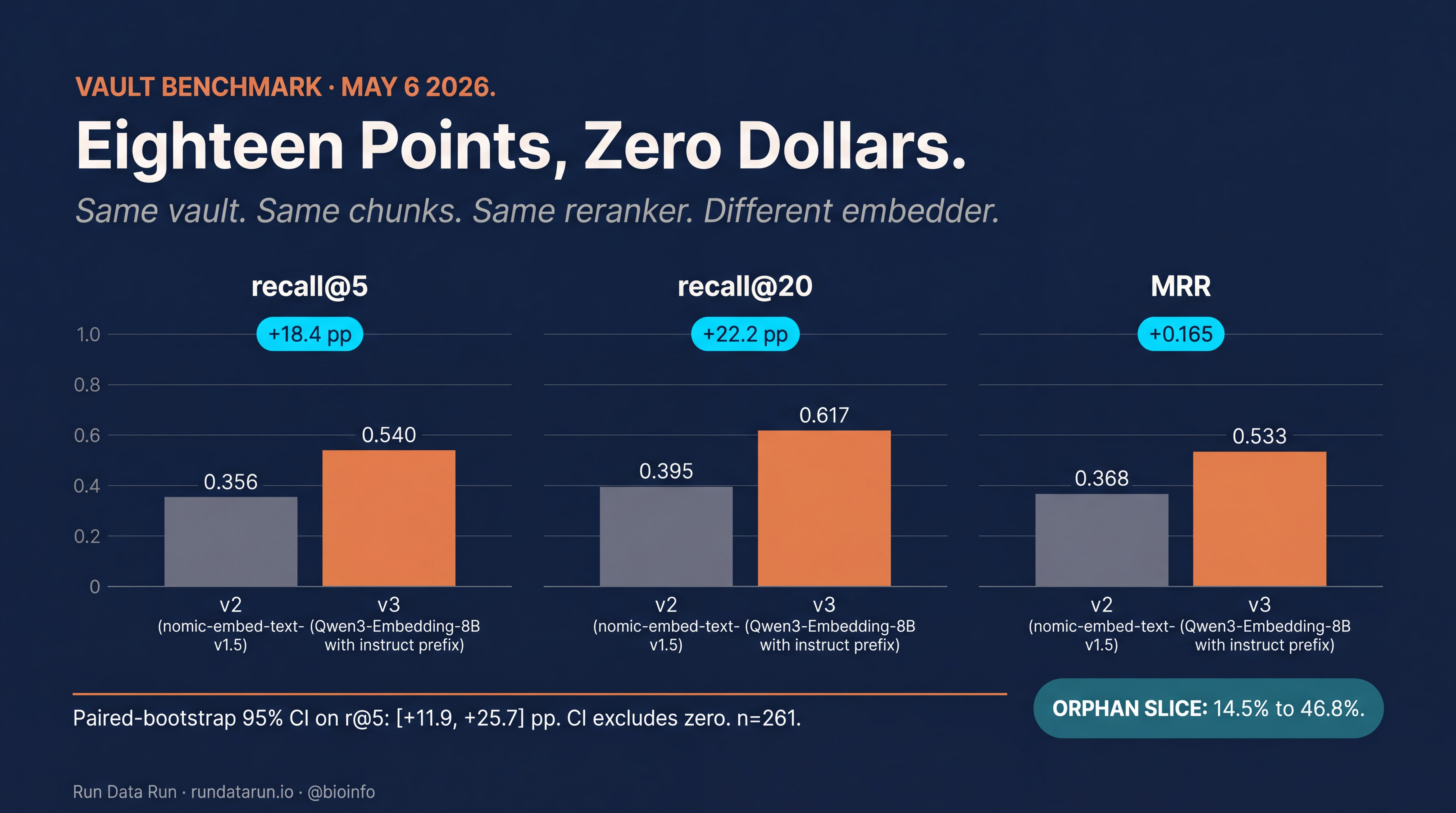
Eighteen points on recall@5. Twenty-two on recall@20. The orphan slice, the bucket contextualization couldn’t move, climbed from 14.5% to 46.8%. That number is where the why lives: orphan queries are exactly the questions that need a finer fingerprint, because by definition they don’t share literal words with the right answer. The bigger embedder catches them on meaning. The smaller one couldn’t.
Multi-hop barely moved (+3 points), which is the right answer. That bucket doesn’t need a smarter reader. It needs a planner in front of the retriever, which is a different upgrade.
Same vault. Same chunks. Same reranker. Different embedder. Eighteen points.
This is the part of the problem that keeps growing. The vault got bigger. The questions got harder. The orphan bucket, the queries where the literal words never appear in the answer, is the slice that most reveals whether the system understands meaning at all. A finer fingerprint moved that slice from 14% to 47%. Nothing about the data changed. The system got better at listening.
The pattern matters because of what comes next. Most enterprise teams aren’t going to stop at retrieval for human queries. They’re going to put autonomous agents in front of the same knowledge base. An agent reading your vault is a reader who never gets tired and never reformulates. It pulls what the retriever returns and acts on it. Every percentage point of recall the system leaves on the table becomes an action the agent took on the wrong note.
The exposure layer has to keep getting more sophisticated for the same reason it always has. The asset compounded. The number of readers compounded faster.
The data is the asset
Pinecone calls it Nexus. Karpathy called it LLM Knowledge Bases a month ago. The category-shift camp calls it a compilation-stage knowledge layer. I call it my vault.
Three names, one shape. The story this past month isn’t “RAG is ending.” It’s the same line the practitioner camp has been holding for a year:
Naive RAG is dead. Sophisticated RAG is thriving.
The pattern of chunk documents, embed, cosine similarity, stuff into prompt was always a prototype. The pattern of curated data plus hybrid retrieval plus rerank is the production system most teams are already running. My null result is direct evidence of how strong that stack already is. The reranker was extracting almost everything contextualization tries to add, before the field’s most-celebrated upgrade got near it.
Two claims I’d put in front of any enterprise team running production RAG.
The asset survives the exposure layer. Cosine to hybrid to rerank to agentic to contextual. Every layer change forced a reindex. The vault itself never moved. Six years of curated markdown, schema files at the root of every project folder, frontmatter the retriever could trust. The retrieval layer will keep evolving. This past weekend it evolved into a place that didn’t help me, and the asset still held. That’s the version of the thesis I’d skip past in a vendor deck.
Governance becomes tractable when the artifact is the unit. A compiled knowledge artifact is reviewable, signable, versionable, diffable, revocable. A vector index is none of those. The teams that get AI governance right next year will have artifacts under their retrievers. Pharma, finance, and legal procurement will reward that more than anything else.
The teams that win this wave already have curated knowledge bases. Ontologies, knowledge graphs, study reports, structured Confluence spaces, controlled vocabularies, validated dictionaries. They’ve been apologizing for them in front of IT steering committees for a decade. The companies that ride this wave aren’t the ones who buy a new platform. They’re the ones who realize they already have the asset and stop apologizing for it.
What the hundred dollars bought
The contextualization run cost me a little over a hundred dollars across two days, counting the original pass plus a one-off pipeline mistake I cleaned up the next morning. The whole point of running it was the recall lift that didn’t show up. By any normal accounting, I lit the money on fire.
By every other accounting I can think of, I’d run the experiment again.
Empirical confirmation that my corpus doesn’t need this technique. Most teams haven’t run the experiment. They installed the upgrade because the headline was big and the indexer was easy to wire up. I now have benchmark numbers that tell me to stop. Most teams don’t.
A working contextualization pipeline. Reusable on a corpus where it actually helps. Long PDFs, legal filings, code repositories. The integration work is done.
The benchmark itself. Now sized at 261 questions across the buckets that break production retrieval most often. Every retrieval change from here forward gets A/B’d through it in under thirty seconds. Worth more than the hundred dollars by itself.
The diagnostic that pointed at the embedder. The four reasons contextualization didn’t move my recall all said the same thing: my chunks weren’t the bottleneck, the reranker was already doing the chunk-level work. That left exactly one place the lift could come from. The hundred dollars I lit on fire on Friday is the reason I bet on Qwen3 on Tuesday and got eighteen points back. A failed experiment isn’t sunk cost when it tells you where the next experiment has to go.
What’s next
Three changes already queued, then the habit that keeps me from torching another hundred dollars on the wrong upgrade.
The v4 sprint. Three pieces bundled. A real keyword-side search (the current setup approximates it at query time; the upgrade does it for real). A small planner in front of the retriever that breaks multi-hop questions into sub-questions before retrieving, which is the bucket no embedder swap will fix. And a newer reranker with measurably better numbers on the public benchmarks. Build, A/B against the v3 baseline, promote only if the lift is large enough to clear the noise floor. Expected to push recall@5 from 54% into the high sixties.
The do-your-homework habit. Before any new technique gets indexer time, a five-minute sanity check. Compare my corpus to what the technique was designed for. Read the part of the paper where they isolate what the upgrade adds on top of a system like mine. Predict the magnitude of the lift. Most of what I needed last weekend was sitting in the appendix of the paper I cited as motivation. I should have read it first.
The same discipline scales. The retrieval layer in front of a curated knowledge base will keep getting better, and it will have to. The asset compounds. The agents that read it compound faster. Most of the upgrades will be free on the data you already have. A few will be expensive null results. The five-minute read of the ablation table is the cheapest insurance you can buy.
Knocked down on Friday. Got back up Tuesday morning with eighteen points of recall.
What the book is about
I’m writing a book about the operating model this kind of work makes possible. The shorthand is “builder-leader.” The person who doesn’t choose between leading and shipping, but builds the leverage that lets them do both. The vault is the brain. Claude Code, the skills, the agents, the harness around them are the body. Without the asset the body has nothing to move on.
Sophisticated retrieval on top of a curated asset is the unlock. Most teams have neither. A few have one. Almost nobody has both. The retrieval layer will be different again next year. Six years of careful note-keeping won’t be.
More at builder-leader.com.
Sunday Deep Dive is a weekly series on Run Data Run. I pick one paper or release worth your time, break it apart, and tell you why it matters. If this was useful, the easiest way to support it is to forward it to one person on your team.
Sources
Building a Markdown RAG System, AIXplore, March 2024. ai.rundatarun.io
Anthropic, Introducing Contextual Retrieval, September 2024. anthropic.com/news/contextual-retrieval
Andrej Karpathy, LLM Knowledge Bases thread, X, April 3 2026. x.com/karpathy/status/2039805659525644595
VentureBeat, The RAG era is ending for agentic AI, May 4 2026. venturebeat.com
Pinecone, Nexus: The Knowledge Engine for Agents, May 2026. pinecone.io/blog/knowledge-infrastructure-for-agents/
From BM25 to Corrective RAG: Benchmarking Retrieval Strategies for Text-and-Table Documents, arXiv 2604.01733, 2026. arxiv.org/html/2604.01733v1
DEV Community, RAG Is Not Dead: Advanced Retrieval Patterns That Actually Work in 2026.
Lushbinary, RAG Production Guide 2026.
Nomic AI, nomic-embed-text-v1.5. huggingface.co/nomic-ai/nomic-embed-text-v1.5
Alibaba/Qwen, Qwen3-Embedding-8B. huggingface.co/Qwen/Qwen3-Embedding-8B
MTEB: Massive Text Embedding Benchmark leaderboard. huggingface.co/spaces/mteb/leaderboard
Jina AI, jina-reranker-v3. huggingface.co/jinaai/jina-reranker-v3
BerriAI, LiteLLM. github.com/BerriAI/litellm
Ollama. ollama.com