
Train Once, Inference Forever
I reproduced Cursor's GPU optimization on a model released two days ago, let two AI agents run 52 experiments, and mapped what nobody else has published.


Wednesday evening I read a blog post from Cursor describing something called Warp Decode. A GPU optimization for running AI models faster. No code released. No independent reproductions. Just a claim: 1.84x throughput improvement on their high-end GPUs.
Normal people read something like that and move on. I opened Claude Code, pointed it at my GPU at home, and said: let’s build this.
By Thursday morning I had working code and benchmarks across two models, including Google’s Gemma 4 (released two days before I tested it). I’d run it head-to-head against the most widely-used open-source serving engine and mapped exactly where the optimization helps and where it doesn’t. The finding wasn’t “it’s faster.” It was the map of when it’s faster and when it’s not.
Why inference speed is the thing to watch
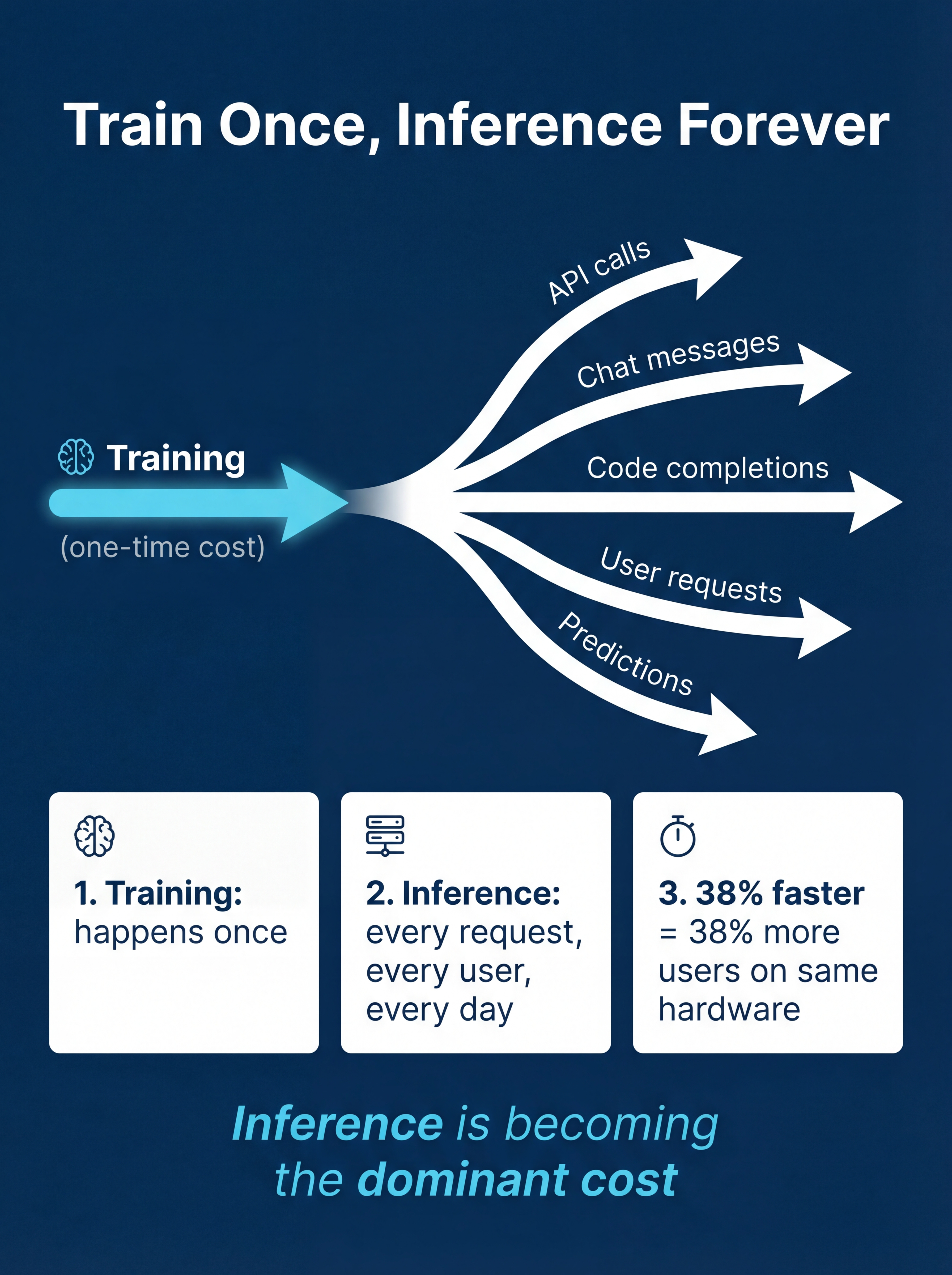
There’s a shift happening that most people in enterprise AI haven’t internalized yet.
Training a model is a one-time cost. You train it, you’re done. But inference, running that model to generate actual output, happens every single time someone asks it a question. Every API call. Every code completion. Every chat message.
Train once, inference forever.
As organizations deploy more AI products to more users, inference becomes the dominant line item. The difference between a viable product and a money pit often comes down to milliseconds per response. Shaving 38% off that number without losing any capability isn’t incremental. It changes what you can afford to build.
Not just which model is best, but how efficiently you can serve it. The infrastructure layer under the AI is becoming as important as the AI itself.
What Warp Decode does (without the jargon)
Modern AI models like Google’s Gemma 4 use something called Mixture of Experts. Think of it like a hospital with 128 specialist doctors. When a patient comes in, a triage nurse routes them to the right 8 specialists. Each specialist examines the patient independently, and their findings get combined into a diagnosis.
The standard approach to running this on a GPU is: collect all the patients for each doctor, send them over in batches, collect the results, reassemble everything. Lots of shuffling paperwork between departments. If you’ve ever been to a hospital, you know how that goes.
Warp Decode flips it. Instead of organizing around the doctors, you organize around the patients. Each patient’s entire journey, visiting all 8 specialists, happens in one place. No paperwork shuffling. No waiting rooms.
Simple concept. Turns out it’s very effective, but only in certain situations.
How I built this in a night
I want to be specific about the process, because it’s part of the point.
I didn’t write custom GPU code from scratch by hand. I described the algorithm to Claude Code, iterated on the implementation, debugged precision issues, and built the testing harness together. The code itself is real, compiled, runs on the GPU. 38 correctness tests, all passing. But the path from “I read a blog post” to “I have verified, publishable results” took an evening, not a month.
You don’t need a dedicated GPU research team. You need a GPU and the right tools.
That speed matters. It means someone running an AI practice at a large company can personally verify claims from the frontier, on their own hardware, on their own schedule.
What the numbers showed
The specialist routing: 4-5x faster
On Gemma 4 (one week old when I tested it), the part of the model that routes work to specialists ran 4.4-4.7x faster with Warp Decode. Real model, real data, 200 measurements.
It was also more predictable. The default approach had wild swings between runs. Warp Decode was steady. If you’re promising response times to users, consistency matters as much as raw speed.
The full model: 38% faster
Swapping in Warp Decode across all 30 specialist layers: 38% faster text generation end-to-end. The routing is roughly a quarter of what the model does on each step, so speeding that up 4.7x translates to 1.38x overall.
38% means you either serve 38% more users on the same hardware, or you cut your GPU bill by a quarter. Pick your framing.
The finding nobody else has published
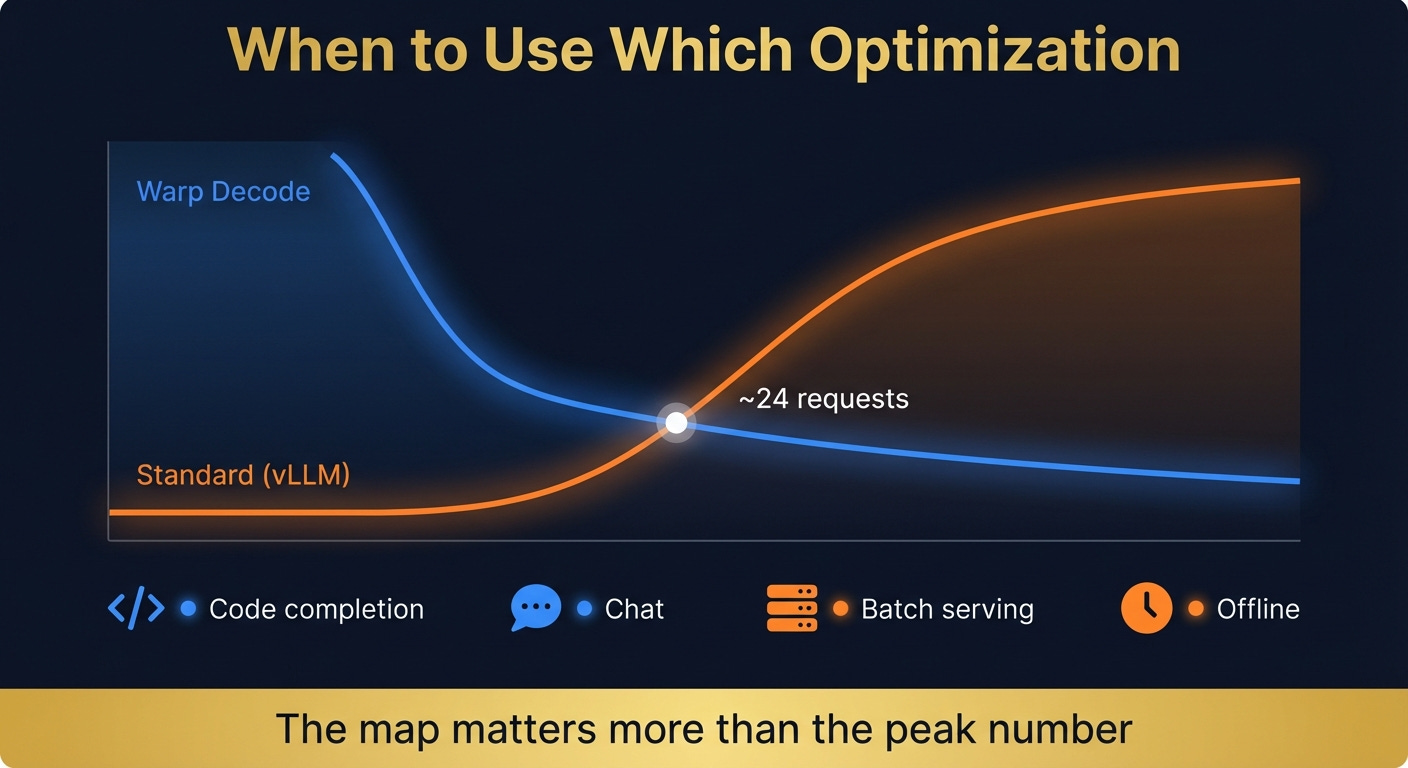
I pulled the actual code from vLLM, the engine most companies use to serve open-source models in production, and ran the two approaches side by side. Same GPU, same conditions.
Warp Decode wins when you’re serving a few users at a time. But once you’re handling 30+ simultaneous requests, vLLM’s approach takes the lead. By 128 concurrent requests, vLLM is 3x faster.
The crossover sits at roughly 24 simultaneous requests per GPU.
That number tells you exactly when to use which approach:
Code completion (Cursor’s use case): a handful of requests, milliseconds matter. Warp Decode was built for this, and it wins.
Interactive chat: moderate traffic, users feel every delay. Warp Decode still wins.
High-volume serving: dozens of concurrent users per GPU. vLLM pulls ahead.
Offline batch jobs: hundreds of requests at once. vLLM wins decisively.
Cursor built Warp Decode for code completion, the most latency-sensitive workload in AI right now. That’s not a coincidence.
What failed (and what it taught me)
Cursor’s blog describes a more aggressive version: instead of storing intermediate results between steps, keep everything in the chip’s fastest memory. Two steps become one. No round-trip.
I tried it. 5-10x slower. On both models. Not 5-10% slower. 5-10x. The kind of result where you triple-check your benchmarking code because surely you messed something up. I hadn’t.
The reason comes down to tools. Think of GPU programming as having two levels. There’s the high-level language (Triton) that’s like Python: productive, fast to write, good enough for most things. And there’s the low-level language (CUDA) that’s like writing assembly: total control, but slow to develop. Cursor used assembly. I used Python-for-GPUs. The specific trick that makes their version work requires a level of control that the higher-level tool can’t express.
This is a real tension. The high-level tool is what let me go from blog post to working code overnight. But there’s a performance ceiling where the only way forward is dropping down a level. I wrote up exactly where that ceiling sits in the AIXplore deep dive.
So I’d hit a wall manually. Which made it a good time to try a different kind of tool.
Letting the agents explore
I set up two autonomous research loops, each running Claude Code on its own. The cycle: read the research plan, look at what’s been tried, pick one thing to test, build it, measure it, write down what it learned. Loop. I’ve written about this pattern before in Running Loops at Midnight, same compound velocity idea: tight iteration cycles where the agent does the mechanical work and the human sets direction.
Two loops ran in parallel for 45 minutes. 52 experiments total. One focused on combining steps, the other on restructuring data access.
For the first few iterations, both did predictable things. Tried different parameter combinations. Rearranged how memory gets accessed. Small gains.
Then around iteration 4, the first loop did something I didn’t expect. It stopped trying to combine steps entirely. It rewrote its own research plan. Its conclusion: the computation isn’t the bottleneck, the data is. The model’s specialist weights are enormous, and every inference step has to load them from memory. Compressing those weights to half their size (a technique called INT8 quantization) gives a clean 2x speedup with essentially no loss in output quality.
It implemented the compression, confirmed 2x, and pivoted to a completely different optimization strategy.
Two iterations later, the other loop independently reached the same conclusion. Different starting point, different path, same insight.
I said “make this faster.” They came back with “the code is fine, the data pipeline is the bottleneck.”
Two autonomous loops, running independently, arrived at the same non-obvious conclusion by trying enough things fast enough to run out of obvious ideas and find the real one underneath.
That’s delegation, not automation. And it changes the math on what one person with a GPU can explore in an afternoon.
Where this is heading
The agents’ insight connects to a bigger pattern. The bottleneck is data moving through the chip, not the computation itself. And the amount of data scales directly with how many specialists each request visits.
I tested on two models to confirm. Gemma 4 routes each request to 8 out of 128 specialists: 4.7x speedup from Warp Decode. Phi-3.5-MoE routes to 2 out of 16: only 1.3x. More routing means more data in motion, which means more to gain from both Warp Decode and the compression trick the agents discovered.
Every major model released in 2026 follows the same architecture: many small specialists, high routing counts. DeepSeek-V3, Gemma 4, Qwen3.5. The trend is moving toward exactly the regime where these optimizations help most.
For anyone building on top of these models, this is the layer worth understanding. Not because you need to write GPU code yourself, but because the teams who understand where inference speed comes from will make better infrastructure decisions, better vendor choices, and better cost projections than the teams who treat it as a black box.
What I took from this
Training costs dominate the AI infrastructure conversation. But for anyone deploying AI products, inference is where the money goes. Every response, every user, every day.
Getting ahead of that curve is what separates teams who can scale AI from teams who find out too late that they can’t afford to.
I didn’t need a research lab or a team of GPU engineers. A GPU, Claude Code, and an evening where I probably should have been watching TV. The full technical deep dive is on AIXplore, 38 tests, code available.
Justin