
The Overnight Loop
An AI agent ran 151 experiments while I slept. The biggest discovery wasn't about AI.

I said in The Convergence that Karpathy’s AutoResearch was “630 lines and a five-minute loop.” The concept was elegant. An AI agent modifies a training script, trains for five minutes, checks a metric, keeps or discards the change. Repeat. You go to sleep, and by morning it’s run a hundred experiments.
I said this pattern would matter. Then I did what I always do. I ran it.

What Happened Overnight
The setup was simple. My DGX Spark, a Blackwell GB10 GPU with 128 GB of memory, sitting on my desk. Claude Sonnet 4.5 running Karpathy’s code with two small modifications: Flash Attention 3 swapped for PyTorch SDPA (Blackwell doesn’t support FA3 yet), and the FLOPS constant corrected from the H100’s 990 to the GB10’s measured 213. That’s it. Two lines changed.
I started a two-hour session in the afternoon. Eighteen experiments. The agent immediately started shrinking things. Smaller batches. Shallower models. By the time I checked, it had already improved the baseline by 20%.
So I let it run overnight.
Sixteen hours later: 151 completed experiments. Twenty-six improvements kept. 122 ideas discarded. Three crashes. And a final result that cut the validation metric by 22.5%.
But the number isn’t the story. The discovery is.
The agent had 128 GB of GPU memory available. It chose to use 6.1 GB. Not because it couldn’t use more. Because using more made things worse.
The conventional wisdom in GPU computing is straightforward: bigger GPU, bigger models, more data per step. That logic works on high-end hardware pushing 990 TFLOPS. The GB10 pushes 213. In a five-minute training window, that difference changes everything.
With the H100’s recommended configuration, the GB10 could only run 93 training steps. Not enough to learn anything useful. So the agent adapted. It cut the model in half. Shrank the batch size by 8x. Each reduction freed compute for more training steps. The final configuration ran about 1,300 steps in five minutes. Fourteen times more learning iterations.
The agent didn’t need my expertise to figure this out. It just needed the loop and five minutes at a time.
Three independent groups ran AutoResearch on the GB10. Nobody coordinated. All three found the same thing: smaller models, more steps, less memory. The physics forced convergence.
Hardware determines optimal architecture. You can’t copy someone else’s GPU configuration and expect the same results. Each platform has its own sweet spot, and the only way to find it is to run the loop.
I wrote the full technical deep-dive on my tech blog, with all the benchmarks, phase analysis, and code details. The full code, all 151 experiment logs, and configuration files are on GitHub. What I want to talk about here is the pattern.
The Pattern That Works on Everything
Try, measure, learn, repeat. No human in the loop. Time-boxed cycles. A scalar metric to optimize. An editable asset to modify.
That pattern doesn’t require a GPU. It doesn’t require machine learning. It requires three things: something you can change, a number that tells you if the change was good, and a clock.
People are already running this loop on things that have nothing to do with model training.
GPU kernel optimization. AutoKernel applies the same pattern to performance-critical code. Given a model, the agent profiles for bottlenecks, extracts each kernel, then runs the loop: edit, benchmark, keep or revert. It uses Amdahl’s law to prioritize by impact, so a 1.5x speedup on the code that runs 60% of the time beats a 3x speedup on code that runs 5%.
Frontend performance. pi-autoresearch runs the loop on Lighthouse scores, bundle size, and build times. Point it at a JavaScript project and it starts optimizing. It includes correctness checks after every pass to prevent “optimizations” that break things.
Marketing. Eric Siu, founder of Single Grain, applied the pattern to landing pages and cold emails. The agent modifies variables (subject line, CTA, headline), measures positive reply rate, keeps or discards. His argument: most marketing teams run about 30 experiments per year. An overnight loop runs hundreds.
Algorithm discovery. Google DeepMind’s AlphaEvolve pairs Gemini with automated evaluators and evolutionary selection. It discovered a matrix multiplication algorithm that improved on Strassen’s 1969 result. It found better data center scheduling that recovered 0.7% of global compute. Same loop. Code, evaluate, select, repeat.
Scientific discovery. Self-driving labs in chemistry and materials science are running autonomous experiment loops where the “code” being edited is the experimental protocol. A robotic system proposes an experiment, executes it, analyzes results, and updates its hypothesis. SAGA goes further: the outer loop formulates new objectives while the inner loop optimizes under the current one. The agent itself designs the scoring function. NC State researchers recently demonstrated this for materials discovery, calling it “fast forward” for the field.
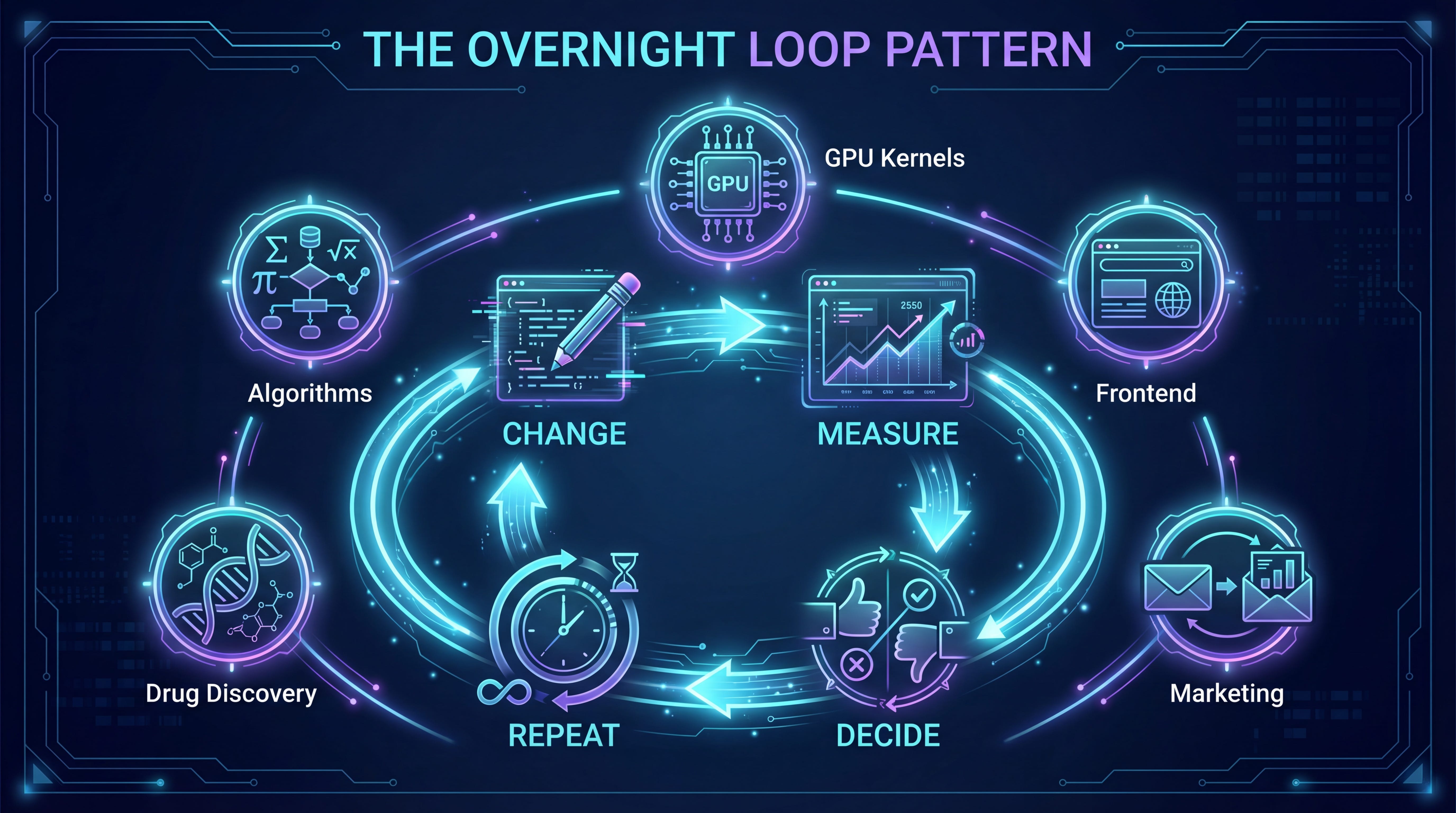
The pattern is always the same. An editable asset, a scalar metric, and a time-boxed cycle. Change something. Measure it. Keep or discard. Repeat until the clock runs out.
Karpathy framed AutoResearch as ML research automation. But the community has already generalized it. The training script is just the first asset people thought to optimize. The loop works on anything with a feedback signal.
Why Now
This pattern isn’t new. Reinforcement learning has been doing try-measure-learn for decades. Control theory before that. What changed is that the “decide what to do next” step is now handled by language models that are good enough, cheap enough, and fast enough to make the loop practical for everyday problems.
Six months ago, the pieces existed independently. Better reasoning models. Cheaper inference. Tool use through protocols like MCP. Each one generated its own hype cycle. What AutoResearch and its variants show is what happens when you stop admiring the pieces and start composing them.
A training script plus an LLM loop equals a research assistant that runs 151 experiments overnight. A landing page plus a metric plus Claude equals a marketing team that tests more variants in one night than most teams test in a year. The composition is the breakthrough, not any individual component.
In Your AI Strategy Should Be 1,000 Small Bets, I wrote that bottom-up experimentation beats top-down transformation. That when you remove friction and let people experiment, the results surprise you. AutoResearch is that thesis running autonomously. The agent makes small bets. Hundreds of them. Most fail. The ones that work compound.
What the Agent Can’t Tell You
151 experiments against the same validation metric. The community has raised valid concerns about overfitting to quirks in the data, and they’re right to ask.
The mitigations are real but incomplete. Five-minute training budget limits the search space. The changes are architectural, not per-sample. 22.5% is too large to be pure noise. Three independent groups converging on the same strategies adds external validation. But would the gains transfer to an unseen test set? To a different dataset entirely? Nobody running AutoResearch right now can answer that definitively.
The hardware insight, though, is physics. 213 TFLOPS is 213 TFLOPS regardless of your validation set. The discovery that hardware constraints determine optimal architecture isn’t an artifact of overfitting. It’s an artifact of running the experiment on actual hardware.
The Loop as Infrastructure
Six months ago, in Compound Velocity, I wrote about small experiments compounding into something larger than any individual result. AutoResearch is that pattern, automated.
If every new GPU architecture needs its own optimization, and if autonomous agents can discover those optimizations overnight, then the loop itself becomes infrastructure. Not the results of any particular run. The capability of running the loop at all.
GPU manufacturers ship hardware. The community runs loops. Optimal configurations emerge. This already happened three times independently for the GB10 alone. Three groups found the same fundamental pattern (smaller, shallower, more steps) without coordinating. The full code and all 151 experiment logs are on GitHub. Anyone with a GPU can clone, reproduce, and compare.
Karpathy has talked about wanting “massively asynchronous collaborative AI agents” for research, something like SETI@home for ML optimization. We’re not there yet. But the pieces exist. The loop runs. The results converge.
OpenAI published a self-evolving agents cookbook describing the same core pattern for production systems: automated retraining loops with LLM-as-judge evaluation. Their use case was pharmaceutical regulatory documents, not GPU training. Same loop. Different asset.
This is where it connects to the broader shift I’ve been writing about. In Delegation, Not Automation, I argued that the future of AI isn’t replacing humans. It’s giving humans the ability to delegate work that was previously too tedious, too slow, or too repetitive to bother with. Nobody was going to manually run 151 training experiments overnight. The work just wouldn’t get done. The agent doesn’t replace an engineer. It runs the experiments no engineer would have time for.
The pharma angle is obvious. Drug discovery is already moving toward autonomous experiment loops. Self-driving labs propose hypotheses, run assays, analyze results, and iterate. The overnight loop is the software equivalent. And in an industry where a single clinical trial costs $50 million and takes years, the ability to run hundreds of cheap experiments overnight to narrow the search space before committing resources changes the economics of R&D.
The future of hardware optimization isn’t a paper. It’s a cron job. Ship a new GPU, run the loop overnight, publish the results by morning.
The Tight Loop
In The Convergence, I ended with a line about small bets compounding quietly. I wrote that the pattern is always the same: try, measure, learn, repeat. Shared generously.
Then I went to bed and let an agent prove it. 151 times.
The overnight loop isn’t a breakthrough in machine learning. It’s a proof that the pattern works. On GPUs, on kernels, on landing pages, on molecular design. Anywhere you have something to change, a number to check, and the patience to let the clock run.
The agent didn’t need my expertise to discover that the GB10 is step-limited. It didn’t need my intuition about batch sizes or model depth. It just needed the loop and five minutes at a time.
That’s what makes this moment different from every other AI hype cycle. Not the models. Not the benchmarks. The loops. Small, patient, autonomous loops running while the rest of us sleep.