
From Petaflop to Production: Building a RAG Research Platform on the DGX in One Afternoon


Last week, I wrote about getting my NVIDIA DGX Spark up and running in three days. The hardware was humming, the GPUs were ready, and I had a petaflop of compute at my fingertips.
The natural next question: Now what do I actually build with this thing?
I didn’t want another demo. I wanted infrastructure that would make my research work fundamentally better. Something that could understand my documents, search the web for current information, and combine both into intelligent answers. A research copilot that actually knows my work.
So I built one. In 45 minutes.
Here’s how it happened, what I learned, and why it matters for anyone working with proprietary documents and AI.
The 45-Minute Deploy: Working with Claude Code
I had a clear goal: production-grade RAG (Retrieval Augmented Generation) infrastructure. Not a quick prototype, but something I could rely on daily for research.
The requirements:
Vector database for semantic search
Document management interface
Integration with my existing Ollama setup
Proper Docker networking
Full documentation
Time budget: Maybe two hours if things went smoothly.
Actual time: 45 minutes.
The difference? I worked with Claude Code as my DevOps partner.
The Partnership Model
Here’s what I didn’t do:
Open 15 browser tabs of documentation
Trial-and-error with Docker networking
Debug port conflicts manually
Write deployment scripts from scratch
Here’s what I did:
Described what I wanted
Reviewed architecture proposals
Made strategic decisions
Let Claude handle implementation details
This isn’t about being lazy. It’s about focusing energy where it matters most: architectural decisions, not configuration syntax.
The Three-Phase Workflow
Phase 1: Planning (5 minutes)
I told Claude: “I want to add RAG capabilities. I’m thinking Qdrant for vectors and AnythingLLM for the UI.”
Claude analyzed my existing setup, identified integration points, and proposed an architecture. I reviewed:
Vector database choice (Qdrant vs. alternatives)
How AnythingLLM would integrate with Ollama
Docker network strategy
Port assignments
My role was to make the call. I chose Qdrant because it’s lightweight and has excellent Python bindings. I approved the networking plan.
Time saved: 20-30 minutes of research I would have done myself.
Phase 2: Implementation (30 minutes)
Claude created docker-compose configurations, set up persistent volumes, configured network bridges, wrote deployment scripts, and generated documentation.
My role was to review each configuration before deployment, test services as they came online, validate integration points, and make adjustments.
The rhythm looked like this:
Claude: “Here’s the Qdrant configuration...”
Me: [Reviews] “Good, but check if 6333 is already used”
Claude: [Checks] “Port 6333 is in use. Switching to 6334”
Me: “Deploy it”
Claude: [Deploys, tests, confirms]This iterative review-and-deploy pattern kept me in control while letting Claude handle the details.
Phase 3: Validation (10 minutes)
Claude generated architecture diagrams, service inventory, integration patterns, access URLs, and health check commands.
I tested the Qdrant API, accessed the AnythingLLM web interface, verified all services were running, and confirmed networking between components.
Done.
The Key Insight
AI assistance scales with context quality. The better Claude understood my existing setup, the better the integration. I delegated execution, not judgment. I stayed engaged through iterative review, not hands-off automation.
The result? Not just faster deployment, but better quality. Proper Docker networking from the start. Complete documentation generated automatically. Systematic port conflict resolution. Comprehensive integration testing.
AI assistance doesn’t skip the “boring” parts like documentation. That’s the leverage.
What I Actually Built
The stack running on my DGX:
Qdrant - Vector database storing embeddings of all my documents. Fast semantic search in milliseconds. Persistent storage, no cloud dependencies. Running in Docker on port 6333.
AnythingLLM - RAG platform with document upload, workspace organization, AI agents with tool access (web search, calculators), and multi-user support. Web interface on port 3001.
Ollama - Serves local models (Gemma-2-9b for chat). No API costs, no rate limits. Runs entirely on local GPU.
nomic-embed-text - Converts text to 1024-dimension vectors. Specialized for semantic similarity. 137M parameters, tiny but powerful. Fast on DGX ARM64 GPU.
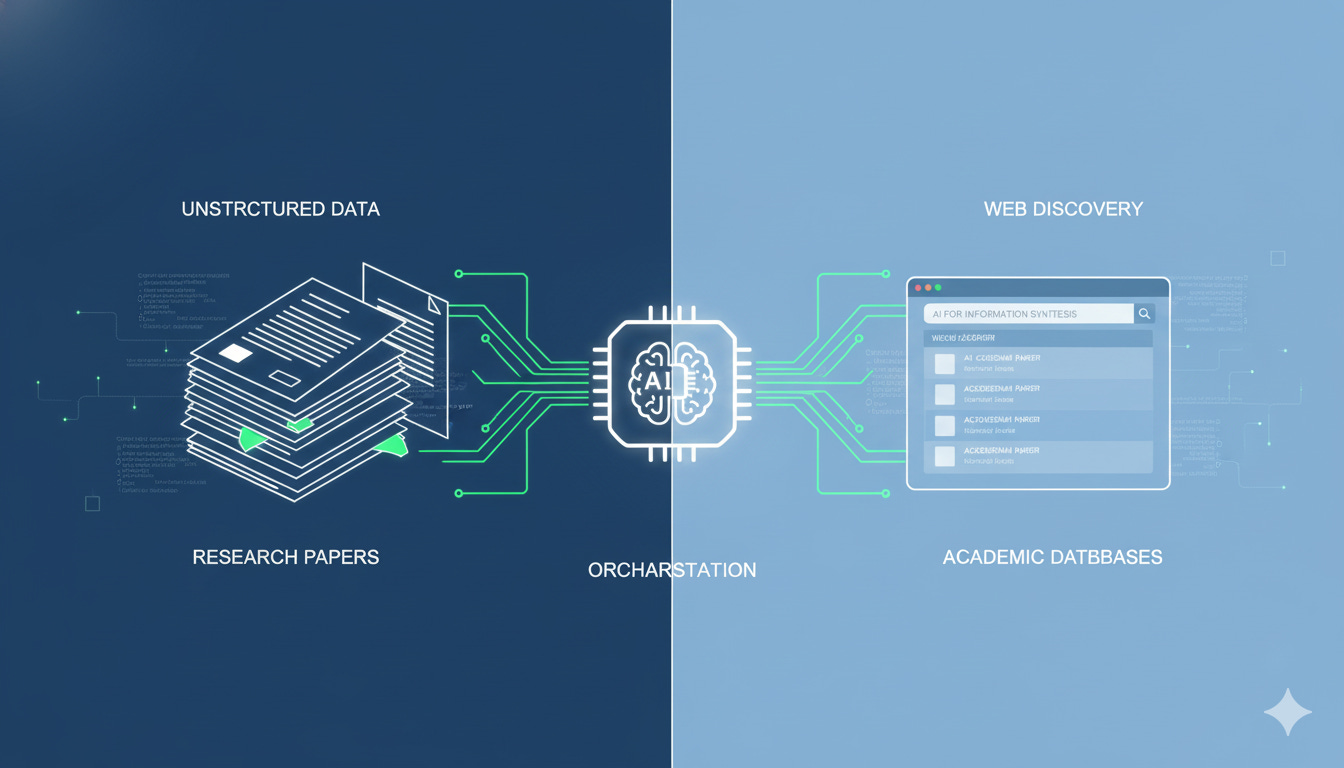
How It All Connects
User Question
↓
AnythingLLM Agent
↓
[Decision: What do I need?]
↓
├─→ Qdrant Vector Search ──→ [Your Documents]
├─→ Web Search Tool ──────→ [Current Research]
└─→ Calculator/Code ───────→ [Computations]
↓
Combine Results
↓
GPT-Quality Answer (Running Locally!)
The agent can search my documents via Qdrant vector similarity, search the web for current information, combine both into coherent cited responses, and execute code or calculations if needed.
All running on my DGX. No cloud APIs. No data leaving the building.
Why This Combination Matters
Privacy: Everything on-premises. My research documents never leave my network.
Cost: $0 per query vs. $0.06-0.13 with cloud APIs. At 1,000 queries/month, that’s $60-130 saved. At heavy usage (100k+ queries/month), this saves $3,000-5,000/month.
Speed: 2-3 second responses. No API latency, no rate limits.
Control: Want to fine-tune on domain-specific terminology? I can. Want to experiment with different prompting strategies? No API costs per test. Want to embed and search 10,000 documents? No per-token fees.
Putting It to Work: Real Research Use Cases
Theory is nice. Here’s what I actually use this for.
Scenario 1: Strategic Planning with Memory
Question: “Based on our past collaborations and current trends in AI research, what should our next project focus on?”
What the agent does:
Searches my documents and finds past collaboration plans, outcomes, and lessons learned
Searches the web and gets current AI research trends, funding priorities, and recent breakthroughs
Synthesizes and recommends focus areas based on my history plus the current landscape
Result: Strategic advice grounded in both my experience and current reality.
This isn’t a chatbot regurgitating training data. It’s an assistant that knows my work and can contextualize it against what’s happening now.
Scenario 2: Literature Review Without Redundancy
Question: “What’s the current state of RAG optimization techniques, and how do they relate to the approaches we tried in our Q3 experiments?”
What the agent does:
Web search finds latest papers on RAG optimization (2024-2025)
Document search retrieves my Q3 experiment notes and results
Analysis compares published techniques with what I already tried
Output: “Here’s what’s new since your experiments, and here’s what you already validated”
Result: I don’t waste time rediscovering what I already know, and I don’t miss new developments.
For researchers, this is gold. How many times have you read a paper only to realize you tried that approach six months ago? The agent remembers.
Scenario 3: Document Drafting with Citations
Question: “Draft a 2-page overview of our ML infrastructure, citing both our setup and industry best practices.”
What the agent does:
Document search pulls my infrastructure docs, configuration notes, and lessons learned
Web search finds industry best practices, benchmarks, and architecture patterns
Draft combines my actual setup with citations to relevant industry patterns
Cites sources with links to both my docs and external references
Result: Professional document that’s both accurate to my setup and credible with external validation.
Current Usage Stats
20+ research documents embedded in Qdrant
Instant semantic search across all content
Cross-document question answering
Pattern identification across my work
Gap analysis between my research and current trends
The Three Discoveries That Made It Work
Getting here wasn’t entirely smooth. Here’s what I learned along the way.
Discovery #1: Model Size ≠ Model Appropriateness
The Issue: Initial configuration used a 110-billion parameter model (GLM-Air-4.5, 72 GB) for document chat. Responses took minutes.
The Insight: For RAG workloads, the retrieval step provides the context. The LLM just needs to use that context to answer. You don’t need world-class reasoning when the answer is already in the retrieved text.
The Fix: Switched to Gemma-2-9b (9B parameters, 5.4 GB). That’s 12x smaller and perfect for the task.
Response Time:
Before: 120+ seconds (minutes)
After: 2-3 seconds ✅
Lesson: Match your model to the workload. Bigger ≠ better for everything.
This was a humbling reminder. I had access to massive models and assumed I should use them. But RAG changes the game. The heavy lifting happens in retrieval. The LLM is just synthesizing pre-fetched context.
Discovery #2: LLMs Are Not Embedding Models
The Issue: The same 110B model was being used for embeddings (converting text to vectors).
The Reality: General LLMs are trained for text generation. Embedding models are trained for semantic similarity. They’re fundamentally different tasks.
The Fix: Switched to nomic-embed-text, a specialized embedding model.
Size Comparison:
General LLM: 110B parameters
Specialized embedding model: 137M parameters
Difference: 800x smaller, and better at embeddings
Lesson: Use specialized tools for specialized jobs. Don’t use a Swiss Army knife when you need a precision instrument.
This discovery cut my embedding time by 95% and improved retrieval quality. Specialized models exist for a reason.
Discovery #3: The Hidden Metadata Tax
The Issue: Document upload failed with “input length exceeds context length” even though chunks were 8,192 tokens and the model supports 8,192 tokens.
The Reality: AnythingLLM adds metadata headers to each chunk:
<document_metadata>
sourceDocument: filename.md
...
</document_metadata>
[your chunk here]
So 8,192 tokens + metadata = overflow.
The Fix: Reduced chunk size to 1,000 tokens, leaving 7,000+ tokens of headroom.
Bonus: Smaller chunks = more precise retrieval anyway.
Lesson: Theoretical limits ≠ practical limits. Account for overhead in production systems.
This is the kind of thing you only learn by building. Documentation tells you the model supports 8K tokens. Reality tells you to leave room for the system’s own needs.
The Economics and Privacy Angle
Let’s talk numbers.
Cloud API Costs:
GPT-4: ~$30-60 per 1M tokens
Claude Opus: ~$15-75 per 1M tokens
Embeddings (OpenAI): ~$0.13 per 1M tokens
My Setup:
Hardware: One-time cost (already have the DGX)
Electricity: ~$50/month (GPU + server)
API costs: $0
For heavy usage (100k+ queries/month), this saves $3,000-5,000/month compared to cloud APIs.
But the bigger win? Privacy and control.
Data Privacy
My research documents never leave my network:
Strategic planning docs
Experimental results
Collaboration agreements
Proprietary analysis
With cloud APIs, every query is potentially training data. With local RAG, everything stays on-premises.
For anyone in pharma, biotech, or competitive research, this matters. Your competitive advantage shouldn’t be training someone else’s model.
No Rate Limits
Cloud APIs have rate limits. My local setup? Limited only by GPU capacity.
Cloud: 100 requests/minute, 10,000/day (typical limits)
Local: Process documents 24/7 if needed
Model Control
Want to fine-tune on domain-specific terminology? With local models, I can.
Want to experiment with different prompting strategies? No API costs per test.
Want to embed and search 10,000 documents? No per-token fees.
Lessons and Next Steps
What Worked
AI-assisted deployment - Claude Code as a DevOps partner provided leverage, not replacement. I made architectural decisions, Claude handled execution.
Incremental testing and validation - Deploy one service, test it, then deploy the next. Faster debugging, clearer failure points.
Documentation as you go - Claude generated docs automatically. Future me (and future Claude) will make better decisions with this context.
Strategic delegation - I delegated configuration file creation, port conflict checking, Docker networking setup, and documentation generation. I kept control of technology selection, architecture decisions, final approval, and testing strategy.
What I’d Do Differently
Performance benchmarking - Should have asked Claude to generate performance tests from the start.
Backup strategy - Didn’t discuss backup/recovery until after deployment. Should have been part of the initial plan.
Monitoring setup - Could have added Prometheus metrics from the beginning instead of retrofitting later.
Even with great AI assistance, you’ll always think of improvements afterward. That’s fine. Ship first, iterate second.
What’s Next
Phase 1 (Complete): Basic RAG with document chat ✅
Phase 2 (Current): AI agents with web search and tools
Phase 3 (Planned):
Multi-agent workflows (research agent + writing agent + analysis agent)
Automated literature monitoring (daily arXiv checks, auto-embed relevant papers)
Integration with experiment tracking
Code generation and execution for data analysis
Phase 4 (Future):
Fine-tuned models on domain-specific terminology
Custom tools for specialized workflows
Multi-modal RAG (images, PDFs, videos)
Infrastructure That Knows Your Work
This isn’t about deploying the latest model. It’s about building infrastructure that:
Knows your context - Documents embedded, instantly searchable
Stays current - Web search for latest information
Combines intelligently - Agent orchestrates multiple sources
Runs privately - No data leaves your network
Costs nothing - After initial hardware investment
For my LinkedIn network of scientists, business folks, and technical professionals, here’s what this means:
For Scientists: Private analysis of proprietary data. Your experimental results, collaboration plans, and research notes stay on your infrastructure while still benefiting from AI assistance.
For Business Folks: Strategic insights without cloud costs or data exposure. Your competitive intelligence, market analysis, and planning documents remain confidential while AI helps you find patterns and opportunities.
For Technical Folks: A reusable pattern for local AI infrastructure. The docker-compose files, configuration patterns, and lessons learned transfer to other projects.
The Bigger Picture
From petaflop hardware to practical research tool in one afternoon. That’s the story.
But the real story is about leverage. AI assistance as a force multiplier, not a replacement. Building tools that work for you, not the other way around.
Cloud APIs are convenient. But local AI infrastructure gives you control, privacy, economics, and speed that cloud services can’t match.
For research-heavy workflows with proprietary documents, this is a game-changer.
Tech Stack Summary:
Hardware: NVIDIA DGX Spark (ARM64 + Blackwell GPU)
Vector DB: Qdrant (semantic search)
LLM: Ollama (Gemma-2-9b, local inference)
Embeddings: nomic-embed-text (specialized model)
Platform: AnythingLLM (RAG + agents)
Cost: $0/month (hardware already owned)
Result: Production-ready AI research platform in 45 minutes.
This is a follow-up to my previous post: Three Days, One Petaflop, and an AI Research Lab. For the detailed technical implementation, see the companion article on my Obsidian Publish site.
Questions or comments? I’d love to hear about your own experiments with local AI infrastructure.
thank you justin for taking the time to share your insights and how tos.
by reading your posts here and on obsidian, i//ve been able to get the RAG production system up and running on the dgx spark founder/s edition.
i am now working on Phase II: Agents
just getting started with data science on the dgx spark.
thanks to jj/s generous postings here and on obsidian, i/ve got a RAG system up and running.
i/m struggling a bit with agents though.
i/m wondering if mdflow might be a possibility for implementing agents. (see deepwiki.com; search for mdflow; there a github repo documentation has been summarized for query).
thank you jj.