
Delegation, Not Automation: How Human-AI Collaboration Actually Works
Part 1 of 3: Nine Days of Petaflop Delegation


The DGX Spark arrived on October 18th. Desktop workstation with NVIDIA’s Blackwell GB10 GPU. ARM64 architecture. A petaflop of compute sitting on my desk.
Nine days later, I had built and deployed:
Medical AI fine-tuned from 70% to 92.4% accuracy (statistically validated)
RAG research platform operational in 90 minutes
150M parameter language model trained from scratch overnight
Novel Socratic training pipeline prototyped and validated
Total hands-on time: about 20 hours. All evening work. Day job maintained throughout.
The traditional timeline for this scope? Eight to twelve weeks of full-time work.
How is this possible without sacrificing quality?
The answer isn’t automation. It’s delegation.
The Critical Distinction
Automation is when you press a button and AI does everything while you wait for results.
Delegation is when you decide what needs to happen, AI handles implementation details, and you validate at every key decision point.
The difference matters.
Automation fails when requirements are ambiguous, when domain expertise is required, when quality standards vary, or when unexpected problems arise. You end up with a black box that either works or doesn’t, and debugging is painful.
Delegation works because humans provide expertise at decision points while AI handles implementation details. There’s a continuous feedback loop. Quality validation is ongoing. Both sides learn and adapt.
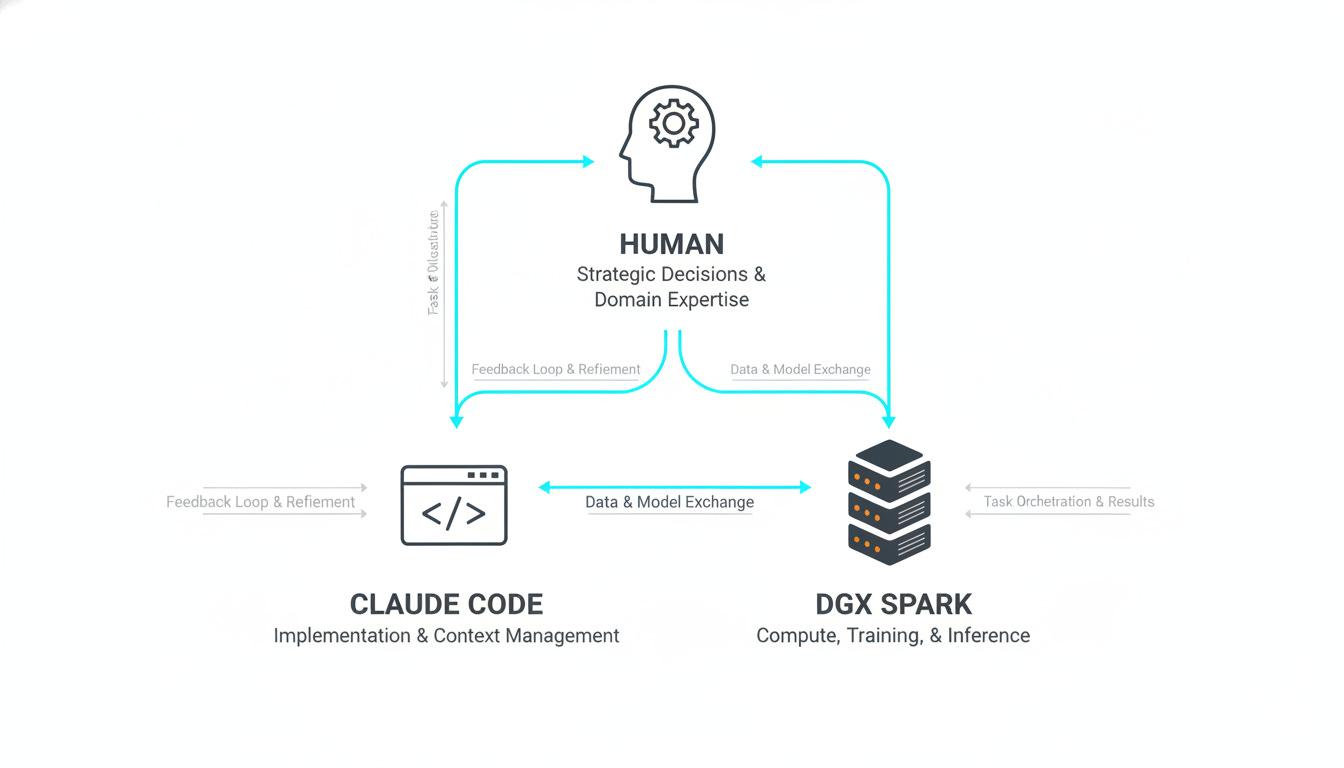
How It Actually Works
I spent nine days working with two cutting-edge tools: the DGX Spark and Claude Code.
My role:
Decide what to build (intelligent gateway, not simple proxy)
Set success criteria (90% accuracy for medical AI)
Make architecture choices (heuristics versus ML for routing)
Provide domain expertise (medical AI needs statistical validation)
Validate quality at every step
Claude’s role:
Generate implementation code
Maintain context across 58 sessions
Spot patterns (”This looks like the Docker issue from Day 2”)
Structure documentation automatically
Handle configuration and boilerplate
DGX Spark’s role:
NVIDIA Blackwell GB10 GPU (80GB HBM3e, 1 petaflop FP8 performance)
ARM64 Grace CPU (72 cores, 480GB system memory)
NVLink-C2C interconnect (900 GB/s GPU-CPU bandwidth)
4TB NVMe storage with hardware RAID
Local inference: 100+ tokens/sec for 70B models
Training capacity: Fine-tune models up to 70B parameters
Power efficiency: 1000W TDP (fraction of cloud equivalent)
The combination is what matters. DGX provides the compute power. Claude handles the implementation velocity. I provide the strategy and domain knowledge.
None of us could achieve this velocity alone.
A Real Example: The Heuristics Pivot
I’ve already written about building the infrastructure and intelligent gateway in the first three days. That post covers the technical details. What I want to focus on here is how we worked together to discover something unexpected.
On night three, we were building a request routing system. The initial plan was to use Arch-Router-1.5B, a machine learning model that classifies requests and routes them to the optimal inference engine.
The ML model worked. It achieved 90% accuracy on our test cases. But it was slow: 950 milliseconds per routing decision. Our target was under 50ms.
Me: “The ML router is too slow. Can we do better?”
Claude: “Let me analyze what patterns the model learned...”
Claude reviewed the test cases and routing decisions. Long prompts went to llama.cpp. Code-related queries went to llama.cpp. Short conversational prompts went to Ollama. These weren’t subtle patterns requiring deep learning. They were extractable rules.
Claude: “These patterns are clear. Want to try rule-based routing?”
Me: “Yes, but we need to maintain the 90% accuracy.”
Claude generated a heuristic router in 45 minutes. Same test cases. Result: 90% accuracy, 0.008 milliseconds routing time.
That’s 95,000 times faster than the ML approach, with identical accuracy.
What happened here:
Claude spotted the patterns in the data and proposed an alternative approach. I set the quality requirement (maintain accuracy) and made the judgment call to ship it. Claude implemented and validated. Together we discovered that well-designed heuristics can match ML accuracy at a tiny fraction of the latency.
This is delegation. I didn’t tell Claude “write heuristics instead of ML.” Claude didn’t just implement blindly without analysis. We collaborated on the insight.
The Morning Warmup
Every morning started the same way:
Me: “Warmup”
Claude: [Reads previous session notes]
[Summarizes what we built yesterday]
[Reviews current system state]
[Proposes next steps from roadmap]
No wasted time re-explaining context. No “where were we?” confusion. Just immediate continuation of work.
This saved 15 to 30 minutes per session. Across 58 sessions, that’s 14 to 29 hours of time that wasn’t spent recreating context.
The DGX’s role here is subtle but crucial. Because all the infrastructure runs locally and stays online 24/7, there’s no “wait for cloud instance to spin up” or “oh, my notebook kernel died overnight.” The system state Claude checks is always current and available.
What Makes DGX Spark Special
Desktop petaflop is a phrase that doesn’t fully capture what this means in practice.
Traditional ML workflow: Submit job to shared cluster. Wait in queue. Hope it doesn’t crash. Check back tomorrow.
With the DGX on my desk: Run experiment now. See results in real-time. Iterate immediately.
The hardware specs matter, but what really matters is what they enable:
Unlimited experimentation. No cloud API costs means trying 100 different hyperparameters doesn’t cost $500. It costs $0. Failed experiments are essentially free. That changes how you think about risk.
Overnight compute. Medical AI experiments ran for 8-12 hours each. I set them up in the evening, went to sleep, and woke up to results. Human time (strategic decisions) is completely decoupled from compute time (training runs).
Real-time feedback. Making a code change and seeing inference results three seconds later instead of three minutes later (cloud API latency) means you stay in flow state. The feedback loop is tight enough to maintain momentum.
Data privacy. Medical Q&A data never leaves my network. For healthcare applications, this isn’t just convenient. It’s often a requirement.
Model flexibility. That 80GB of HBM3e means running 70B parameter models locally. No compression. No quantization unless you want it. Full precision inference and training on models that would cost $3-5 per hour in the cloud.
NVLink bandwidth. The 900 GB/s interconnect between Grace CPU and Blackwell GPU means data movement isn’t a bottleneck. Load gigabytes of training data, preprocess on CPU, train on GPU without waiting.
But here’s the catch: the DGX Spark runs Blackwell GB10 on ARM64. That’s about as bleeding-edge as you can get. NVIDIA’s newest GPU architecture (just released late 2024) on a non-standard processor architecture means you’re in early adopter territory.
Some frameworks don’t support ARM64 yet. Some that do have bugs in the ARM64 builds. GPU inference was unstable throughout the nine days (training worked perfectly, but inference would randomly crash). We worked around it by using CPU inference. Slower, but 100% reliable.
Is this frustrating? Sometimes. Is it fun? Absolutely. You’re at the frontier. You figure things out. You contribute solutions back to the community. And the raw performance when things work is phenomenal.
This is the blessing and curse of cutting-edge hardware. You get access to capabilities that didn’t exist six months ago. But you also become the beta tester. For me, that’s worth it. You learn more, you contribute more, and you’re positioned for when the ecosystem matures.
What AI Is Exceptionally Good At
After nine days and 383 messages, these are the capabilities that stood out:
Context maintenance across weeks. 58 sessions documented. Every decision remembered. Every architecture choice traceable. When I asked “Why did we choose heuristics over ML routing?” on Day 8, Claude could cite the exact performance numbers from Day 3 and explain the reasoning.
Traditional approach: Dig through notes. Try to remember. Maybe find it after 15 minutes. Maybe just forget and redo the analysis.
Our approach: Instant recall with full context.
Implementation speed. Generating a 200-line routing service takes minutes, not hours. Testing 10 different configurations is automated. Boilerplate code appears instantly. This isn’t about typing speed. It’s about maintaining momentum. When you think “what if we tried X?” you can have an answer in minutes, not tomorrow.
Pattern recognition across contexts. When AnythingLLM couldn’t connect to Qdrant on Day 5, Claude immediately said “This looks like the Docker networking issue from phase 1b.” Same root cause, different application. That cross-session pattern matching saved an hour of debugging.
Documentation that stays current. Code and documentation evolved together. Every session got documented as we worked. Not after. Not “we should write this up later.” Concurrent. The result is 58 comprehensive session files that capture every decision, every pivot, every lesson learned.
Tireless iteration. Test 10 hyperparameter combinations? Run 7 experiments over 7 days? Regenerate documentation after each change? These tasks don’t cause Claude fatigue. The 8th experiment gets the same attention as the first. That consistency matters when you’re iterating toward a solution.
What Humans Must Provide
AI doesn’t replace expertise. It amplifies it.
Strategic direction. Claude couldn’t decide whether to build a medical AI system or a climate model or a financial forecasting tool. I chose medical AI because I understand healthcare applications and can evaluate whether 92.4% accuracy is production-worthy.
Domain expertise. When we hit 92.4% accuracy on medical Q&A, Claude ran statistical tests (p-values, effect sizes, confidence intervals). But Claude couldn’t tell me whether p < 0.001 is sufficient for medical applications, or whether we should prioritize recall over precision for this use case. That requires medical domain knowledge.
Quality judgment. At 70% accuracy, I said keep iterating. At 82%, I said validate more thoroughly. At 92.4% with statistical significance, I said ship it. These aren’t algorithmic decisions. They’re judgment calls based on use case requirements, risk tolerance, and resource constraints.
Creative leaps. The Socratic training idea (using progressive hints instead of direct answers to teach small models) didn’t come from any training data. It came from understanding teaching methodologies, seeing analogies across domains, and being willing to try something unconventional. That’s human creativity.
Ethical oversight. Medical AI requires rigorous validation. I enforced statistical testing with adequate sample sizes (500 examples). I insisted on reliability over speed (CPU inference instead of unstable GPU). These standards exist because of the real-world consequences of errors. AI implements standards. Humans set them.
The Synergy Zone
Here’s where it gets interesting: human plus AI plus powerful hardware is greater than the sum of parts.
Day 1: Built basic infrastructure in 3 hours. I decided what we needed (Ollama deployment, GPU monitoring, workspace structure). Claude handled implementation. DGX provided the compute. I validated.
Day 3: Built intelligent gateway in 3 hours. This was only possible because Day 1 infrastructure existed. No starting from scratch. Velocity increasing.
Days 4-10: Ran four major experiments (medical AI, NanoChat training, RAG platform, Socratic training) using all the previous infrastructure. Training ran overnight on the DGX while I slept. Human time focused on strategic decisions. Velocity compounding.
Each day’s work enables next day’s experiments. Infrastructure gets reused. Context persists. Learning accumulates. Velocity compounds exponentially.
And all three parts of the system get better over time. By Day 9, our communication was much more efficient than Day 1. Shared context had built up. We were finishing each other’s thoughts. The DGX’s capabilities became familiar, so I knew exactly what experiments were feasible and what would hit hardware limitations.
The Time Economics
Traditional timeline for this scope:
Infrastructure setup: 2 weeks full-time
RAG platform: 1 week
Fine-tuning pipeline: 3 weeks
From-scratch training: 2 weeks
Total: 8-12 weeks (320-480 hours)
Our timeline:
Infrastructure: 3 evenings (8 hours)
RAG: 1 evening (1.5 hours)
Fine-tuning: 7 evenings (12 hours hands-on)
Training: 1 evening setup (2 hours), 8h overnight
Total: 12 days, about 20 hours hands-on
Acceleration factor: 16-24x faster.
But more important than speed: sustainability.
No all-nighters. No burnout. No technical debt. Day job maintained. Quality never sacrificed. Complete documentation throughout.
The difference? AI handles grunt work (boilerplate, configuration, documentation). DGX provides unlimited compute (overnight training, free experimentation). Human focuses on high-value decisions (strategy, quality, domain expertise).
This isn’t about working harder. It’s about working differently.
What This Enables
For individual researchers: Side projects become feasible. That experiment you’ve been thinking about for months? Try it this weekend. 20 hours to validated prototype.
For small teams: You can compete with larger organizations. Infrastructure setup drops from weeks to days. One researcher can be as productive as three. Experimentation costs approach zero after the initial hardware investment.
For the field: Lower barriers to entry. More people can build AI systems. Faster iteration leads to better science. Knowledge sharing scales because documentation is automatic.
But this only works if you stay engaged. This is delegation, not automation. You need domain expertise to make good decisions. You need strategic thinking to choose what to build. You need quality judgment to know when to ship and when to iterate. You need creativity to try novel approaches.
AI provides velocity. Hardware provides power. Humans provide wisdom. Together: wisdom at velocity.
What Comes Next
In Part 2, I’ll walk through the actual experiments: how we took medical AI from 70% to 92.4% accuracy with statistical validation, trained a 150M parameter language model from scratch overnight, and built what I call a “digital laboratory notebook” that maintained research quality at high velocity.
The numbers are interesting. But what’s really interesting is how we maintained rigor while moving this fast. It involves treating your workspace like a sophisticated lab notebook, where every experiment is documented, every decision is traceable, and reproducibility is built in.
Part 1 showed you how delegation works. Part 2 shows you what becomes possible when experimentation is this cheap and documentation is this automatic.
If you’re wondering whether 92.4% accuracy in 7 days sounds too good to be true, Part 2 will show you the actual timeline, the failures along the way, and the statistical validation that proves it’s production-ready.
Because the goal isn’t to impress you with speed. It’s to show you that sustainable research velocity, with quality maintained, is actually achievable when you combine powerful local compute (DGX Spark) with intelligent delegation (Claude Code) and human expertise.
This is Part 1 of a three-part series on building an AI research lab in nine days. Part 2 covers the experiments and introduces the digital laboratory notebook concept. Part 3 explores what this means for the future of scientific computing.
For the infrastructure setup details (Ollama, llama.cpp, intelligent routing), see Three Days, One Petaflop, and an AI. For the RAG platform deployment, see From Petaflop to Production.