
When Biology Meets Silicon
The Convergence Driving Biological Foundation Models


The sudden convergence of artificial intelligence and biology isn't just another tech trend—it represents a fundamental shift that's reshaping how we approach drug discovery and clinical innovation. After decades of incremental progress, we're witnessing computational breakthroughs, unprecedented data availability, and strategic investments aligning to position biological foundation models at the center of modern medicine.
This convergence raises important questions: Why is this transformation happening now? What makes biological data uniquely challenging for AI systems? How do foundation models address these specific hurdles? And perhaps most importantly, what therapeutic breakthroughs can we realistically expect in the near term?
The Language of Life Meets AI
Biological sequences share surprising similarities with the text that powers large language models. DNA consists of four nucleotide "letters" (A, T, G, C), while proteins are built from 20 amino acid building blocks. These sequences follow patterns, have contextual dependencies, and contain "grammar" rules that determine function—much like human language.
This parallel isn't coincidental. Transformer models, originally designed to process natural language, excel at identifying long-range dependencies and contextual relationships. When applied to biological sequences, these same architectures can learn the intricate patterns that govern protein folding, gene expression, and molecular interactions.
AlphaFold's breakthrough in protein structure prediction perfectly illustrates this capability. By treating amino acid sequences as "sentences" and applying transformer-based attention mechanisms, DeepMind achieved unprecedented accuracy in predicting how proteins fold—a problem that had puzzled scientists for decades.
However, biological sequences operate under different constraints than human text. While language can be ambiguous and metaphorical, biological sequences follow strict physical and chemical laws. A misfolded protein can be toxic; an incorrect genetic variant can cause disease. This precision requirement makes biological AI both more challenging and potentially more impactful than text-based models.
Computing Power Crosses the Threshold
Modern computational capabilities have finally reached the scale needed for sophisticated biological modeling. DeepMind's AlphaFold training used 128 TPUv3 cores over several weeks—modest by today's standards but still requiring tens of petaflops of processing. Current hardware like NVIDIA's H100 GPUs and Google's TPU v4 have significantly raised the computational ceiling.
NVIDIA's Cambridge-1 supercomputer, launched in 2021 with a $100 million investment, delivers over 400 petaflops of AI performance specifically for healthcare research. Pharmaceutical companies have used this system to model representations of 1 billion chemical compounds—a task inconceivable without such computational horsepower.
Cloud providers now offer specialized BioAI-optimized instances. NVIDIA's BioNeMo cloud service lets researchers run generative models for proteins and molecules on-demand, dramatically lowering barriers for academic labs and startups to train large biological models.
Biology's Data Revolution and Unique Challenges
Biological data has reached unprecedented scale, but comes with distinct challenges that set it apart from other AI domains. GenBank now contains over 42 trillion DNA base pairs from 5.56 billion sequence records—up from roughly 100 billion bases in 2010.
Yet biological data fundamentally differs from web text used in language models. Each experiment represents unique conditions—laboratory variations, measurement noise, and systematic biases create consistency challenges that don't exist in text data. A protein's behavior varies dramatically across cellular contexts, and experimental artifacts often correlate with design parameters, potentially misleading AI systems.
DNA sequencing costs have plummeted from $2.7 billion for the first human genome to under $200 per genome today, with some companies promising $100 genomes. This dramatic cost reduction means researchers now have access to genomes from tens of thousands of species and large patient cohorts like the UK Biobank's 500,000 whole-genome sequences.
Early bio-AI efforts frequently failed due to these data quality issues. Models trained on limited datasets couldn't generalize across different experimental conditions or laboratories, highlighting the need for more sophisticated approaches to biological data generation and processing.Reinventing Biological Data Generation
Recognition of these challenges has driven innovations in experimental design. Companies like Recursion Pharmaceuticals operate robotic systems performing thousands of standardized experiments daily, while CRISPR-based screens and synthetic biology approaches enable systematic data generation designed specifically for machine learning.
High-throughput experimental platforms now prioritize data quality and consistency over simple volume, creating controlled datasets that address the fundamental reliability issues that limited previous bio-AI approaches.
Experimental Validation: From Prediction to Practice
Computational predictions from biological foundation models require rigorous wet-lab validation before clinical application. AI-driven experiment design is accelerating this validation by prioritizing the most informative tests. Rather than random validation, machine learning can identify which predictions are most likely to succeed and which experimental conditions provide the strongest validation signals.
Several foundation-model-informed drug candidates are now advancing toward clinical trials. Exscientia achieved the milestone of the first AI-designed small molecule entering Phase I trials with DSP-1181 for obsessive-compulsive disorder, going from target to clinical candidate in approximately 12 months. Insilico Medicine followed with ISM001-055 for idiopathic pulmonary fibrosis, becoming the first AI-designed drug to reach Phase II trials by 2023.
As of 2025, an estimated 15+ AI-designed small molecules have entered Phase I trials across various companies, spanning oncology, immunology, and fibrosis applications.
Benchmarking: Establishing Standards for Biological AI
Beyond wet-lab validation, the field increasingly recognizes the need for standardized benchmarking to evaluate biological foundation models systematically. Recent developments in comprehensive benchmarking frameworks are establishing rigorous evaluation standards that go beyond simple accuracy metrics.
These benchmarking efforts address critical questions about model generalization, robustness across different biological contexts, and performance on clinically relevant tasks. Standardized benchmarks enable fair comparison between different modeling approaches and help identify which architectural innovations actually improve biological prediction tasks.
The benchmarking movement also tackles the reproducibility challenges that have plagued computational biology. By establishing common evaluation protocols and standardized datasets, the field is building the infrastructure needed to validate biological AI claims rigorously and accelerate genuine progress.
Multimodal Foundation Models—The Future of Biological AI
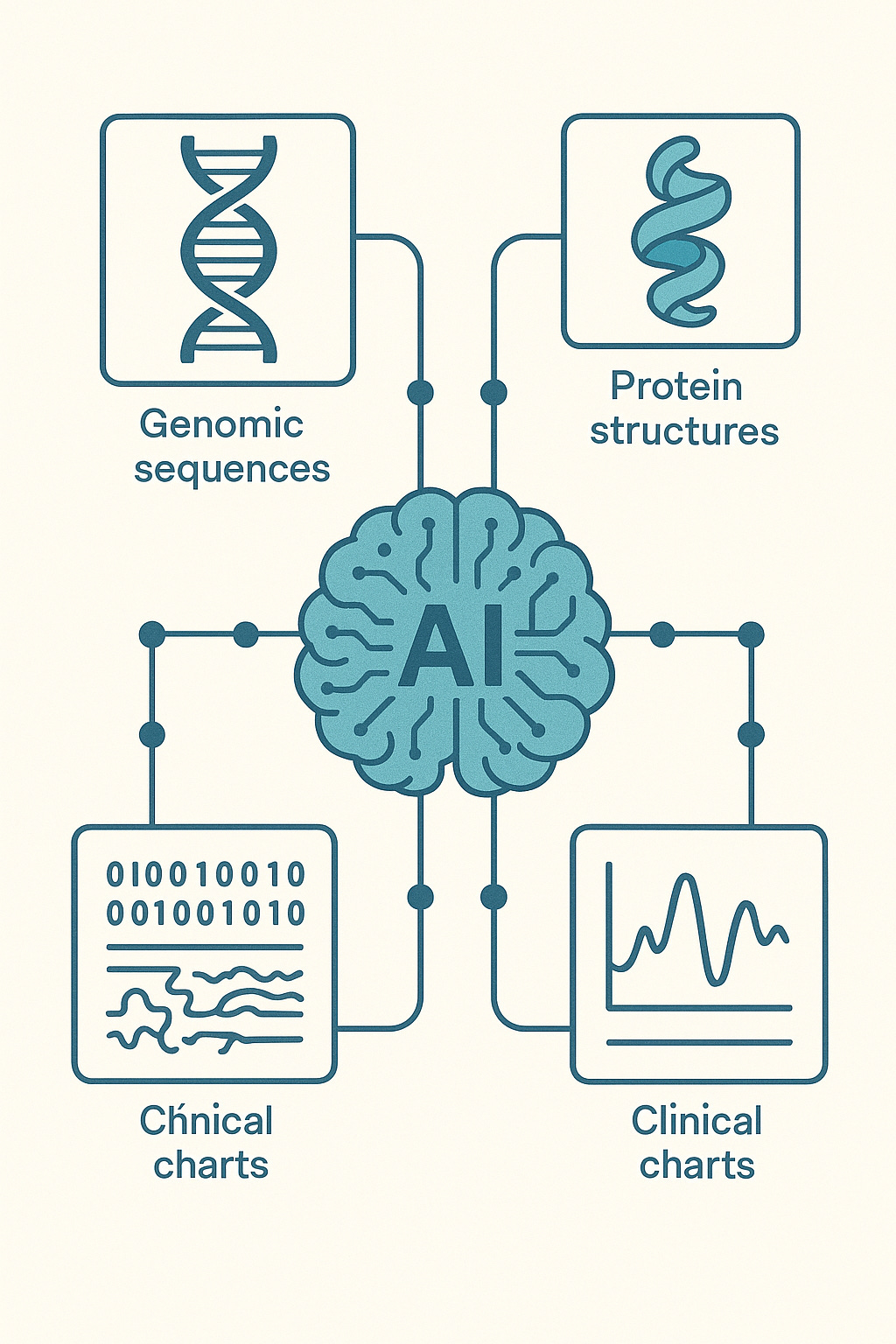
The future of biological AI lies in integrating diverse data types. Biological systems generate genomic sequences, protein structures, cellular images, physiological measurements, and clinical outcomes. Understanding biology requires connecting these different data modalities.
Recent developments show promising progress. Harvard's Mahmood Lab has developed sophisticated multimodal approaches including Titan for integrating pathology images with genomic data, and Kronos for temporal modeling of disease progression. Their THREADS framework demonstrates how transformer architectures can effectively combine histopathology images with molecular data for cancer diagnosis and prognosis.
Commercial efforts are advancing rapidly as well. Companies like Insitro and Generate Biomedicines are developing proprietary multimodal platforms that integrate experimental data with computational predictions, moving beyond simple data concatenation to develop architectures that meaningfully combine genomic sequences, protein structures, cellular phenotypes, and clinical outcomes.
The technical challenge involves reconciling fundamentally different data types—discrete genomic sequences, continuous imaging data, and categorical clinical information—while the conceptual challenge requires understanding which modalities provide complementary information and how to weight different evidence types appropriately.
A Transformative Era for AI-Driven Drug Discovery
The convergence of computational power, data availability, and investment capital has created conditions for biological foundation models to transform drug discovery. Unlike previous AI hype cycles in biology, current capabilities rest on substantial technical foundations.
These foundation models uniquely address longstanding hurdles in biological research. They can process vast datasets to identify subtle patterns, generate testable hypotheses across multiple biological scales, and guide experimental design more efficiently than traditional approaches.
Therapeutic areas with well-characterized biology and available data are positioned for rapid AI-driven innovation. Oncology benefits from extensive genomic datasets and established biomarkers. Rare diseases, paradoxically, may see significant progress because their well-defined genetics make them amenable to computational approaches. Infectious diseases offer opportunities for rapid response using computational design principles.
The most significant opportunities lie at the intersection of computational prediction and experimental validation. Organizations that effectively combine AI capabilities with high-quality experimental platforms are positioned to drive the next wave of therapeutic innovation.
For researchers, investors, and healthcare professionals, this represents more than a technological shift—it's an opportunity to actively shape how AI transforms medicine. Success will require collaboration across computational and experimental disciplines, realistic assessment of capabilities and limitations, and sustained commitment to rigorous validation standards.
The convergence is real, the tools are mature, and the opportunities are substantial. The question isn't whether biological foundation models will transform drug discovery, but how quickly and effectively we can harness their potential while maintaining the scientific rigor that medicine demands.