
Three Harnesses, Three Characters, One Working Week
Choose your harness every six months. Don't let it choose you.


I’m writing this in Claude Code. That’s not a credibility flex. It’s a working confession before the rest of the piece reads as scoring. For the past year I’ve used all three of the tools I’m about to compare. Claude Code is my daily driver. I call Codex from inside it often, and I keep OpenCode in regular rotation on purpose, as a discipline for staying sharp to the alternatives. Take the rest accordingly.
I don’t want to wake up in two years and discover I let myself get lured into one of them because everyone else did.
The three I’ve used as daily tools for the last year are Codex CLI from OpenAI, Claude Code from Anthropic, and OpenCode, an open-source project from sst.dev. I wrote a version of this comparison earlier; the field has reshaped enough that the old piece reads like a different category of tool. All three shipped meaningful updates in the last 90 days. All three look more alike on a feature checklist than they did three months ago. All three are still, at the architectural level, doing fundamentally different things. The temptation when you stare at the feature list is to call that convergence. The temptation when you sit inside one of them is to call it tribalism. Neither read is right. The field is neither converging nor consolidating.
What I’m not comparing is a much longer list. The harness race has the same shape as the model race: too many credible players for any one person to evaluate fairly, with a new entrant every week. AWS, Google, Moonshot, Alibaba, Mistral, Block, Cognition, Replit, Sourcegraph, the Cline and Continue and Aider open-source lineage, plus a dozen others all shipped serious harnesses in the last year. The full inventory is in the appendix at the end. This piece stays narrow on purpose, on the three I actually run.
This is not a buyer’s guide. I’m not picking a platform for an engineering team. I’m describing how three different tools fit into the long-horizon work of one person who writes books, drafts essays, builds models, cleans data, and ships creative work, sometimes in the same week, often in the same day.
How I actually use them
Most of my work runs through Claude Code. The book, the blog drafts, the long-horizon research, model building, all of it lives in a tool that remembers what I corrected last week and carries voice rules across hundreds of sessions. I call Codex from inside Claude Code when the work shape changes: forty-five minutes on a notebook, a feature pipeline to iterate on, a quick statistical test. Codex is terse and decisive, and the terseness wins on tasks I can name in a sentence and finish in a session. OpenCode sits in regular rotation on lower-stakes work, on purpose. Once a quarter I’ll move a small project entirely into it for a week. The reason is fluency. The risk for anyone with a daily driver is that the daily driver becomes the only thing you can see. Six months from now Claude Code might still be the right answer. It might not. The way I’ll know is by keeping the alternatives warm enough to feel the difference when I switch back.
Choose your tool every six months. Don’t let your tool choose you.
The point isn’t that you need three tools. Each one is shaped for a different work shape, and a long-horizon worker with multiple work shapes ends up running more than one. A team picking a single platform is a different problem with a different answer. This is just how a person who has to ship across a book, a blog, a model, and a creative draft has settled in.
What they share
Six weeks ago you could draw a clean architectural line between these three. Today the line is smudged. All three now have cascading config files (CLAUDE.md, AGENTS.md, both). All three have a marketplace pattern for plugins or skills. All three have multi-agent worktrees, persisted-session primitives, and MCP-or-equivalent routing. Codex shipped its Chrome extension and Claude Code shipped its enterprise MCP OAuth update on the same day this month.
Read only the changelogs and you’d conclude these are turning into the same product. Use them for a week each and you’d conclude something else.
Where they actually differentiate
The differentiation isn’t in the features. It’s in what each one is shaped to do well.
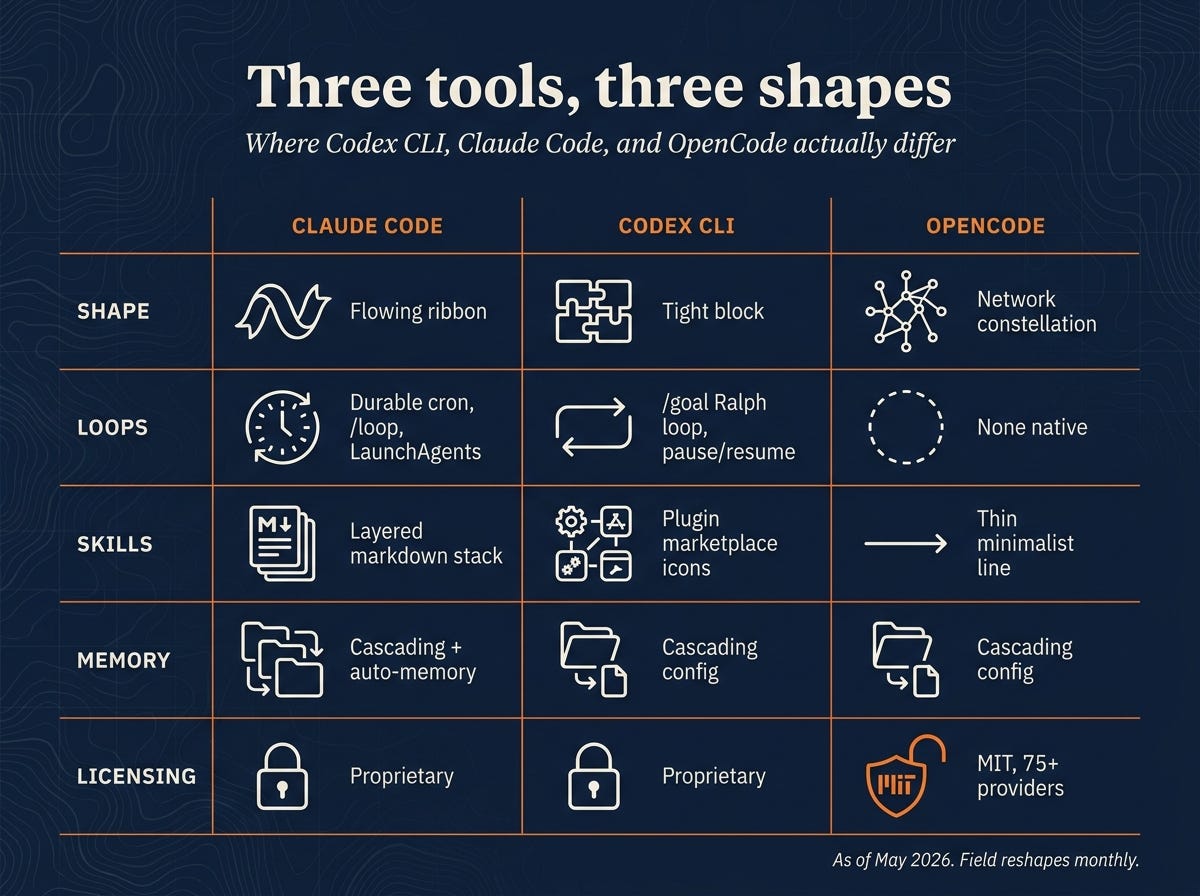
Claude Code is built for long-horizon coherence. The 1M-token context, the skills-plus-auto-memory loop, the durable cron, the cascading config: a stack designed around running unattended for hours or days. Loops persist across machine restarts via LaunchAgents, and a /loop primitive lets a task self-pace its own intervals when you don’t want to pick one upfront. Skills live as versioned markdown files with frontmatter that controls when they auto-trigger and what context they pull in, with a marketplace layered on top of that local model. Memory cascades from user-global rules to machine-specific overrides to project instructions, with an auto-memory layer that captures corrections and surfaces them in future sessions so you don’t re-explain the same preference every Monday. I wrote about the broader version of that memory pattern, vault-as-brain underneath the harness, in From the Vault. The verbosity, the premium pricing, and the heaviness on quick atomic tasks all follow from the same commitment.
Codex CLI is built for per-session bundled productivity. Terse by default, marketplace plugins shaped around tasks you can name in a sentence, optimized for the “forty-five minutes and move on” rhythm. Codex closed part of the gap on long-running work at the end of April with /goal, an OpenAI-endorsed Ralph loop that runs a single objective through plan-act-test-review cycles for hours, with pause/resume/clear from the terminal. It’s a different shape than Claude Code’s durable cron: one objective held until done, not a schedule of recurring jobs. Plugins bundle a named workflow with its prompts and permissions, so the unit of reuse is a task you can describe in a sentence rather than a long-running role. Memory is AGENTS.md-cascading, same shape as the others, but nothing tracks what you corrected last week across sessions. The compactness is the design.
Open, finish, close.
OpenCode is built for substrate freedom. MIT-licensed, 75+ providers natively, dual Build/Plan toggle, no permission required from any single model lab to ship. The provider abstraction is the decision everything else hangs off. Skills and memory are thinner than the other two on purpose, because every commitment to a particular memory shape or skill format becomes a coupling to the model that has to read it. The Build/Plan toggle handles in-session structure: Plan reasons without acting, Build acts within the plan. Durable loops and cross-session memory are left to the operator to wire up. The cost is more glue. The benefit is that no single model lab can deprecate your tool out from under you.
These three commitments don’t reduce to a feature checklist. They show up in the texture of using each one for a week. The feature-by-feature breakdown, with benchmark numbers and the 90-day shipping cadence per harness, lives in the AIXplore companion to this piece.
Economics
Pricing across all three rotates faster than this paragraph will age. ChatGPT Plus rebalanced its Codex allocation in April. Claude Code’s Pro tier may lose access entirely. OpenCode launched a $10/month Go subscription this week. None of these prices will hold for 90 days. What’s stable is the pattern: gateway routing has become a real economic lever. A handful of shell aliases that swap a gateway target before launching the harness can route voice-sensitive drafting to the premium model whose character you want, bulk file scanning to a cheaper open-weight model, and sensitive code to a self-hosted endpoint.
The harness stays constant. The model rotates.
Bills drop 40% to 80% versus running everything against the premium tier. OpenCode does this natively. Claude Code does it through the gateway pattern. Codex does it more by accident than design, but it does it.
The model still matters, for a non-obvious reason
There was an analysis that made the rounds in March, after a leak exposed the source code of one of these tools. The argument was that the system is mostly deterministic software, not AI. Most of the value, the argument went, comes from how the tool routes context, dispatches its sub-tools, and shapes what the model is allowed to see. The model is a small, expensive component nested inside a much larger software system.
That’s true. It’s also incomplete in a way that matters for anyone choosing one of these tools.
What the leak actually showed is that the tool is the lens. It’s a lens shaped around a particular model’s character. Claude Code’s long-horizon coherence depends on a model that holds context coherently over hours. Codex’s atomic-task speed depends on a model that produces short, decisive answers without thinking out loud. OpenCode’s freedom-to-choose story depends on whatever model you point it at being able to follow the tool’s protocols at all.
Each tool is doing the work that lets a particular model character be useful at scale.
Picking one of these is partly picking which model character you trust to run while you’re not watching. The next question is whether you need to be there at all.
Sidebar: autonomous agents are a different category
A separate category is starting to show up at the edges of this conversation, and it’s worth naming because the boundary is blurring. Autonomous frameworks like OpenClaw and Hermes run as fleets of agents without per-session human input, optimized for long-horizon unsupervised execution. The three tools I described above all assume a human is in the loop, ready to interrupt, ready to course-correct. The autonomous category does not. That’s a different reliability problem with a different set of failure modes. A security incident in one of the open-source autonomous frameworks earlier this month is the cautionary tale that makes the distinction visible. Most builder-leaders are currently shipping the supervised category into production and prototyping the autonomous one. A future piece will cover that category specifically.
If you want the deeper technical breakdown of the three supervised tools, with feature-by-feature differences, benchmark numbers, and the architectural detail of where each one is going next, that lives in the AIXplore version of this piece.
Appendix: the rest of the field
I haven’t put serious hands on any of these in the past year, which is why this piece doesn’t compare them. Each one is shipping, has real users, and carries a coherent point of view about what a coding agent should be.
AWS: Kiro, Amazon Q Developer
Google: Jules, Gemini CLI, Antigravity (parallel agents with a built-in browser)
Moonshot: Kimi CLI
Alibaba: Qwen Code
Mistral: Vibe
Cursor and Windsurf: both shipping CLI modes alongside their IDEs
Open-source IDE extensions: Cline, Roo Code, Continue.dev
Aider: longest-running terminal agent, the one most of these others trace back to
Block: Goose
Charm: Crush
Plandex, Replit Agent, Devin (Cognition), Zed AI, Sourcegraph Amp, Augment, Droid, iFlow, Kilo, Warp 2.0, GitHub Copilot CLI
A comparison written without hands-on time is what makes most of these roundups useless. So this piece stayed narrow on purpose. If your daily driver is one of the above, I’d be curious how it compares.