
Pulling Threads
I dropped my autonomous loop into a blind pharma challenge with zero background in the field. Then I read my own write-up and noticed I kept saying "I".


I keep doing the same thing. I build something for one problem, watch it work, and then go hunting for a different problem to point it at. Sometimes the thing I'm reusing is a script. Sometimes it's an idea. Lately it has been an entire pattern: set up an autonomous loop on a workstation, give it a clean gate, queue some candidates, and check what it found in the morning.
That pattern was not mine originally. In March, Andrej Karpathy released a 630-line script called autoresearch that points an AI agent at a tiny language-model training setup and lets it run experiments overnight, on its own, while you sleep. The first night Shopify's CEO Tobi Lütke pointed it at his company's data, it ran 37 experiments and came back with a 19% improvement. The kind of overnight headline number that, as I'd relearn the hard way a few weeks later, is worth a second look before you believe it. The idea grabbed me. I built a version of it for my own personal coding queue and wrote it up in The Overnight Loop. It was supposed to be a one-off. It refuses to stay one-off.
The pattern wants new domains. So in early May I went looking for one.
I found the OpenADMET PXR Induction blind challenge. Two hundred and eleven teams. Five hundred and thirteen blinded molecules. A live leaderboard. Phase 1 set to close May 25th.
A quick primer: PXR is a sensor inside human cells. When a drug switches it on, the body responds by making more of an enzyme that chews up other drugs that happen to be passing through. If you're an oncology company giving a patient three drugs at once, and one of them switches on PXR, you can lose half the exposure of the other two without realizing it. Combination trials live or die on this. Predicting PXR activation from a molecule's structure, before you spend money making it and testing it in cells, is a real, unsolved problem. ADMET, the broader field this sits in, stands for absorption, distribution, metabolism, excretion, and toxicity. It's the part of drug discovery that asks "will this molecule survive contact with a human body."
The challenge was a clean version of that prediction problem. Public training data. A frozen test set. Score it on a leaderboard. The reason I picked it: I have no background in ADMET. None. I had never trained a molecular property model. I had never heard of Chemprop before April. The challenge was a good fit because it was a fair test of the loop, not a fair test of me. If the system worked in a domain I knew nothing about, that meant the system was the thing carrying the load, not borrowed expertise.
I entered on May 6. I closed the loop on May 11. Final rank settled at ~40 out of 211, in the top 19%. The system worked. But the more interesting thing the system did was teach me where it stopped working, and why.
It was a fair test of the loop, not a fair test of me. If it worked in a domain I knew nothing about, the system was carrying the load.
The Climb and the Wall
The climb took six days, and most of it doesn't matter. I started at the tutorial baseline and ranked 131st. My first real model was worse than the tutorial, which is the part everyone leaves out of the writeup: the organizers built a strong floor on purpose. Adding more chemistry features, every number I could compute about a molecule thrown into one pile, got me partway up. Rank 131 to 112. The obvious lever, pulled.
The obvious lever ran out fast, and the real jump came from changing the kind of model, not feeding it more. I blended in one that reads a molecule by walking its bonds and learning the shape of the chemistry directly, instead of from a pre-computed list. Rank 112 to rank 42. Seventy places on one submission. The new model wasn't smarter than the trees. It made different mistakes, and two models that fail in uncorrelated ways cover for each other. That single idea was most of the climb.
After that it was maneuvering, and the loop was quick enough to make it fun to watch. Stack a model, grid-search the blend weights, keep the new piece only if it cleared a hard bar (it had to improve the honest score by a sliver, or back it went), move to the next. A second bond-walking model trained on extra public data. An automated ensemble riding on the foundation-model embeddings. Each idea tried, weighed, and kept or thrown back in about the time it took to refill coffee, the workstation in the corner grinding through a full experiment in minutes while I read the logs. By the third morning the blend (v43, my 43rd submission) sat at rank ~40 of 211, top 19%, and I knew it was real.
Two models that fail in uncorrelated ways cover for each other. That single idea was most of the climb.
Then the wall arrived, and it was duller than the climb. Over the next several days the loop queued candidate after candidate, each a genuine shot at a new angle, and every one came back ranking the molecules almost the way the leader already did, a correlation above 0.87. Same answer, different clothes. Twenty-seven in a row. That sounds like failure; it is the most useful thing the loop produced, because twenty-seven distinct candidates all converging on one answer is how you prove a ceiling is real instead of guessing at it. The only candidate that looked like a breakthrough, v50, turned out to be cheating itself: it scored well only because a calibration step got to peek at the answers it was being graded on, and the honest version of that check showed almost no gain. The gate caught it. Had I shipped it, I'd have dropped from rank 40 to 87. The model I shipped is fine. The protocol that caught that one is what I'm taking with me.
Twenty-seven distinct candidates converging on one answer is how you prove a ceiling is real, not a hunch.
I kept writing "I"
I just re-read what I have so far. I wrote it the way I write every Run Data Run post. "I built." "I queued." "I caught v50." That pronoun is doing more work than it deserves.
For most of my writing, the "I" is roughly correct. I am at a keyboard, making decisions, calling shots, occasionally pairing with Claude Code to type the code faster. The usual ladder of human-AI collaboration goes human in the loop (steering each step), human on the loop (monitoring with the right to intervene), human out of the loop (reviewing the result after the fact). My day-to-day writing and coding is the first two.
This was the third. For most of a week, I was human out of the loop.
I had no domain opinion to bring. I didn't know what a message-passing function on a molecular graph should look like. I didn't know whether tail-weighted regression losses were a real technique for skewed targets or a thing I had hallucinated from reading too many papers. I didn't know whether to trust an in-sample calibration fit. Every one of those calls was made inside the loop, by Claude, against criteria the loop itself enforced.
For most of a week, every call belonged to Claude. What belonged to me was the thing that decided which calls to trust.
What I actually built was the scaffolding the loop ran inside. That part is mine, and it's the part worth digging into, because it's the difference between this challenge and the version of "AI did it for me" that gets eye-rolls at conference panels.
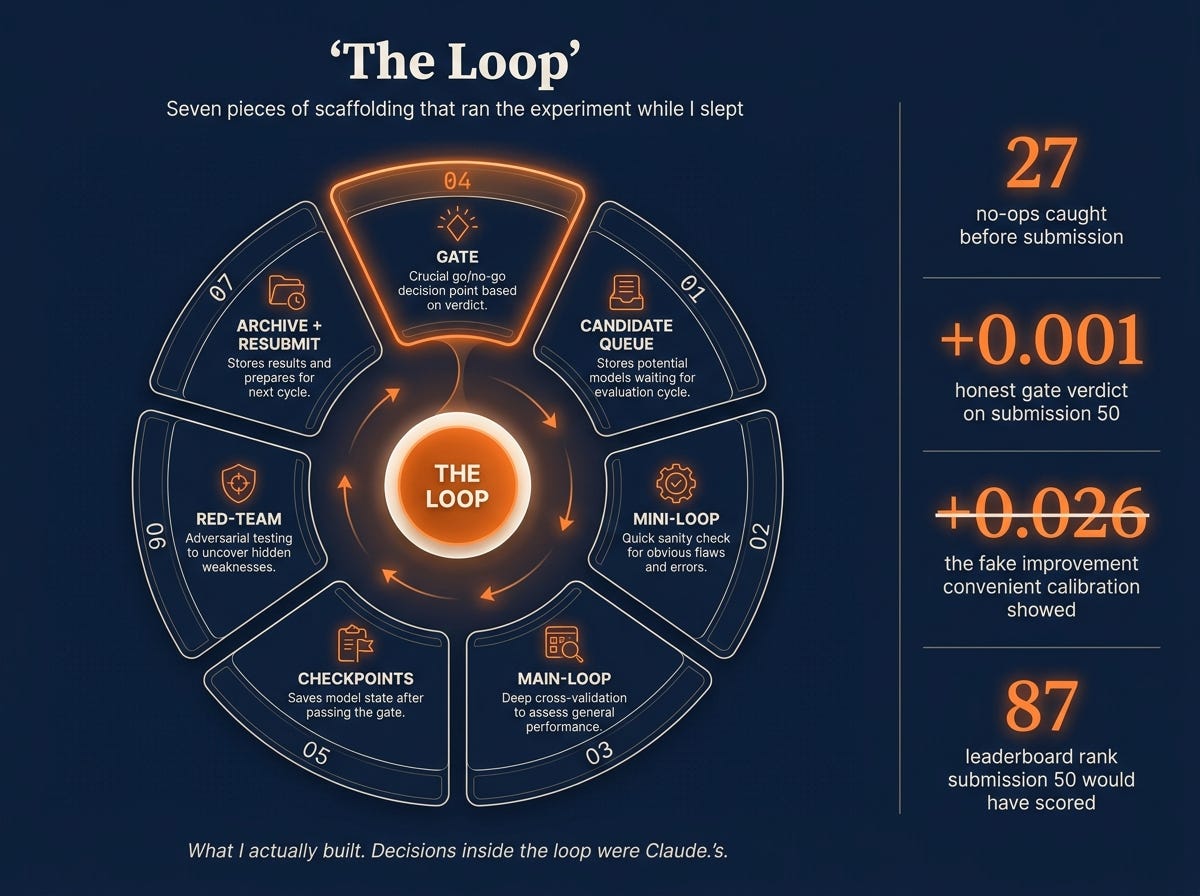
The system had seven pieces:
A candidate queue. A plain text file of model ideas, each with a one-line hypothesis ("this newer architecture should make different mistakes than the current leader") and a link to prior work. Claude pulled from the front of the queue, ran the experiment, wrote the result back into the file, and moved on.
A two-tier loop. A fast pass for cheap sanity checks (does this even train, does the output look sane) and a slow pass for the full evaluation and the honest gate. The fast pass killed the embarrassments before the slow one spent two hours on them.
A single gate function. One function. In: a candidate's predictions. Out: the honest improvement over the leader, and a verdict, PASS only if it cleared a real threshold. That was the entire decision surface. Nothing got submitted that didn't pass.
Checkpoint files. Every time the loop crossed a phase boundary (baseline verified, candidates exhausted, defensive submission filed), it wrote down the exact state at that moment, the way you'd read a flight log. I could open any one and know precisely where things stood, down to a fingerprint of each prediction file.
Red-team reports. At each checkpoint, the loop wrote a short adversarial section: state a claim the system had just made ("v43 is the reproducible baseline"), construct an attack against that claim ("could the test predictions have been silently corrupted between submissions?"), pull the evidence (the file's fingerprint, the timestamp, the server's own echo of the numbers), give a verdict. If the attack landed, the claim was downgraded. If it failed, the claim was kept and the verdict was recorded next to it.
Auto-archival. Anything that failed the honest gate was moved into an
_archive/folder with the gate verdict baked into the directory name. The candidate didn't disappear, it sat in a folder I could re-read later and ask "what did we try, and why didn't it work."Defensive submission. If the loop didn't find a candidate that beat v43 in a 24-hour window, it re-submitted v43 anyway to keep the rate-limit clock alive. I never lost a submission slot. I never thought about it.
What I contributed was not the model decisions. It was the architecture of trust. I decided what the gate would test, how big the threshold had to be, what counted as an adversarial attack worth running, when to archive versus when to keep, and what events promoted a checkpoint. Once those were defined, Claude could run for hours without me, and the artifacts it produced were either things I could trust at a glance or things the system had already flagged.
That is closer to running a small research group than to using a coding assistant. The researchers (various Claude sub-tasks, queued and dispatched by the loop controller) had real autonomy inside a framework I controlled at the level of "what counts as evidence." I was reviewing summaries, not steering decisions.
I'm going to keep saying "I" in the rest of this post, because the alternative gets tedious. But it's worth being explicit, once, about what that pronoun is covering for.
What I'm leaving with, and what I'm leaving on HuggingFace
Everything is on HuggingFace. The full v43 pipeline, all the component model checkpoints, the predictions behind every result, the 513-row final submission, and the methodology report. Apache 2.0 across the board. If you want to reproduce the blend, it's five lines of code after cloning the repo. If you want to try beating v43 with your own candidate, those predictions are right there to test against.
The model is not the deliverable. The deliverable is the system that built it, and the documented map of where the ceiling lives.
A few specific things I am carrying forward:
The auto-loop pattern is now confirmed to work in a domain I have no expertise in. That widens the set of problems it can be pointed at.
The honest calibration gate is non-optional from now on. I'll bake it into the first scaffold of any leaderboard or held-out evaluation problem I touch.
"Stop the loops at saturation" is a real engineering discipline. Once the loop has confirmed that diverse candidates all converge to the same answer, the next ten candidates will too. Every extra run costs money and tells you nothing new.
Two weeks ago I had never heard of Chemprop. Today I have a reproducible ensemble in the top 19% of a real pharma blind challenge, a methodology report I'd defend on a panel, and a sharper sense of what the autonomous loop is for and what it is not. The Saturday morning after I locked the submission, my wife asked what I had been doing all week. I said I had been pulling threads. That is most of what this work is.
The next thread is already on the desk.
Justin Johnson writes Run Data Run. Code, weights, and the full methodology report for the PXR challenge live on HuggingFace.*