
Neural Networks Don't Think in Straight Lines
Goodfire's new work suggests most of our tools for understanding AI are pointed at the wrong shape.


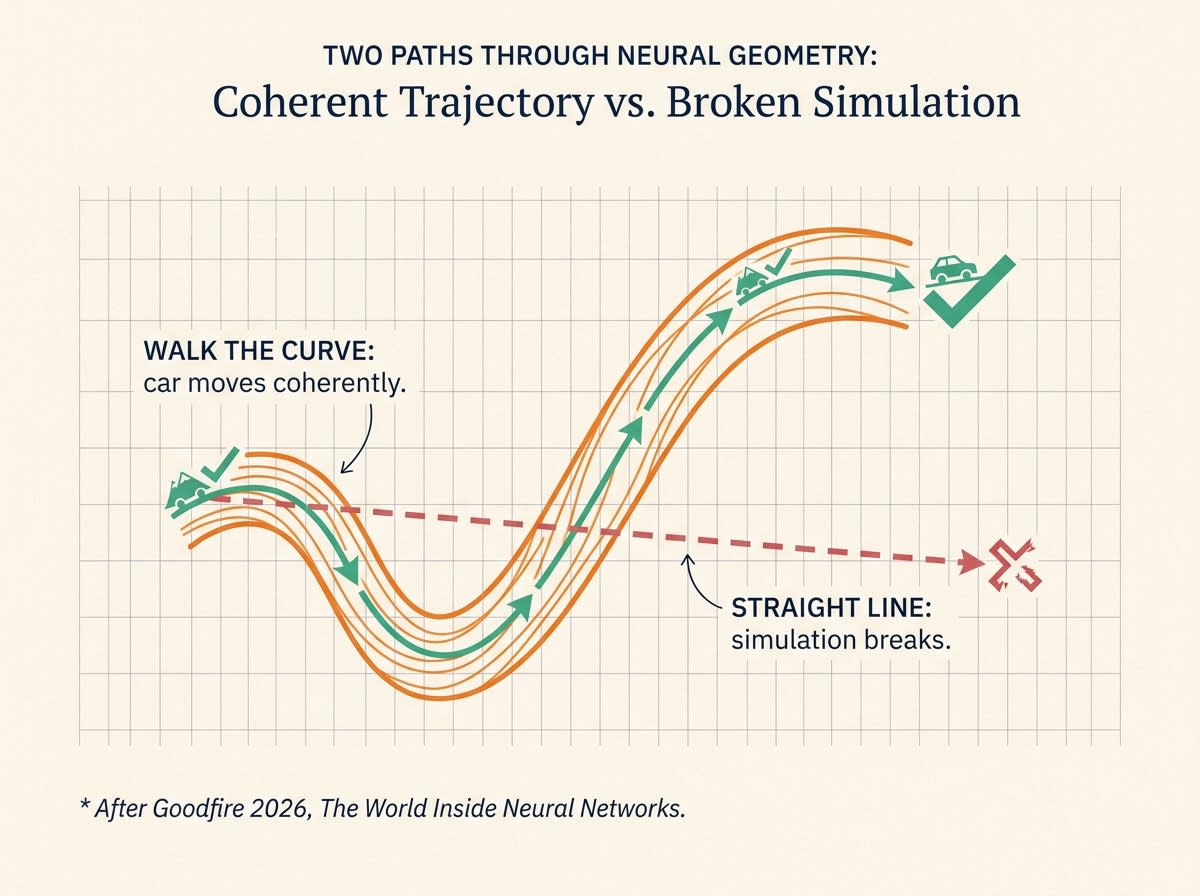
A research team at Goodfire trained a tiny neural network to drive a virtual car up a hill. Then they looked inside the network to see how it represented the car’s position.
The answer was not where anyone expected.
Position didn’t live as a clean direction in the network’s internal space. It lived as a curve, threaded through the network’s neurons like a string. Every point on the string corresponded to a real-world position of the car.
When the team nudged the network along that curve, the car moved coherently. When they nudged it in a straight line across the curve, the way almost every modern interpretability tool does, the predictions broke. The car teleported. The simulation produced nonsense. The straight line wandered through regions of the network’s space that the model had never learned to handle.
Their new paper, “The World Inside Neural Networks”, argues this isn’t a quirk of one toy model. It’s how networks actually represent things.
The shape of the problem
Most of what we do to understand or steer large AI models assumes representations are straight. There’s a name for this assumption in the field, the linear representation hypothesis: concepts inside a model live as directions in the network’s internal space, and you can adjust the model’s behavior by moving along those directions.
You see this assumption everywhere. It’s how Anthropic built “Golden Gate Claude”, the version of its model that couldn’t stop talking about a bridge. It’s how researchers find “refusal directions” and “honesty vectors.” It’s how sparse autoencoders (SAEs), the dominant tool for naming what’s inside a model, try to break activity into a clean list of concepts.
Add. Subtract. All of it assumes flat geometry.
If the real structure is curved, every straight-line move is just an approximation along a tangent, and the further you push, the worse the approximation gets.
That would explain a lot of unsolved noise in the field. Why steering tricks work in narrow zones and fall apart at the edges. Why killing one “feature” inside a model often breaks something unrelated. Why so many “we found the X concept” papers don’t reproduce cleanly when somebody else tries.
The field has been working with the wrong shape and getting partial credit for the effort.
What they actually showed
The Mountain Car experiment is the centerpiece. It’s small, but the intervention proved the geometry: walk along the curve, the model behaves; cut across it, the model breaks. That’s the difference between geometry as decoration and geometry as cause.
The same lens shows up in their other work. Months and days form circles inside language models. Colors organize by hue and brightness. I walked through one of Goodfire’s biology pipelines a few weeks back, where the same techniques surface features in a DNA model that look like splice sites and regulatory regions. The curved-geometry view is becoming their signature.
The harder claim, and the more important one, is what they say about sparse autoencoders. SAEs are the bet Anthropic, OpenAI, and DeepMind have all made on how to read large models. Goodfire argues SAEs break continuous structure into disconnected pieces. Their example: words ending in “-ore” form one smooth curve in the model’s internal space, and SAEs shatter that curve into a handful of unrelated features. The unity disappears.
If that critique holds for big models, a meaningful slice of current AI safety research is studying artifacts of its own tools, not the model.
What’s oversold
The framing, “the world inside neural networks,” does more work than the evidence supports. The paper smuggles in a big claim, that models contain a faithful map of reality, which is hard to disprove because nobody knows what would count against it.
What Goodfire actually showed is narrower and more useful. Representations are curved. The curves are causal. Tools that assume straightness are leaving capability on the table. That’s enough. The cosmic framing is marketing.
Two real gaps the paper doesn’t address:
Does it scale? They show the geometry is causal for one toy model. Does the same picture hold for a 70-billion-parameter language model? Open question.
Is it the same picture across models? If different models trained on the same data find the same curves, the geometry is approximating something real about the world. If not, the curves are model artifacts and the philosophy crumbles.
Both questions are answerable. Neither is in the paper.
Why this is worth watching anyway
Two reasons.
One, it reframes the tooling debate. The interpretability community has been arguing about which kind of feature dictionary to build. Goodfire is asking whether a dictionary is even the right object. A map of curves wants different math, different methods, different papers.
Two, the parallel with biology is getting hard to dismiss. Grid cells, place cells, and head-direction cells in mammalian brains encode space as exactly the kind of curved structure Goodfire is finding inside artificial networks. That work won the 2014 Nobel Prize in Physiology. When evolved biology and trained silicon land on the same shape, the convergence is worth taking seriously.
A year ago I wrote that interpretability was the race we couldn’t afford to lose. Goodfire’s work is what running that race looks like when it goes well.
This is an important direction, half-marketed, and the next year of interpretability research will tell us whether the curved-geometry view replaces the feature-dictionary view or merges with it.
Watch the scaling question. Watch whether somebody bigger than Goodfire bets on this lens.
If they’re right, a lot of recent activation-steering work is about to age badly.
Around the Corner: short reviews of ideas worth watching. Opt-in section, not part of the weekly Run Data Run email. Subscribe to the main list for longer essays.