
Every AI Agent Is Missing Its Dopamine
A weird neuroscience paper from Romania might explain why your AI agent has capability but no judgment.


I was browsing arXiv at midnight, as one does, when I stumbled across a 45-page paper claiming to unify the entire brain into a single operational theory. From a university I’d never heard of. In Romania.
My first reaction was skepticism. My second reaction, about ten pages in, was: wait, this maps onto something I’ve been trying to articulate for months.
The paper is called “The DIME Architecture” (arXiv:2603.12286), and whether or not it’s right about the brain, it gave me the cleanest vocabulary I’ve found for a gap that’s been bothering me since I started building agents seriously. A gap that, once you see it, you notice in every agent framework, every autonomous loop, every production system shipping today.
Three things work. One thing is completely missing.
A Weird Paper from Romania
The paper comes from the University of Craiova. Five authors: an electrical engineer, a robotics researcher, an anatomist, a physiologist, and a clinical psychiatrist. Not the usual suspects for a theory-of-everything paper. No affiliation with DeepMind, no backing from a major research lab, no previous citations I could find.
And yet the framing is genuinely sharp.
Their argument: all cognition, from recognizing a face to planning a vacation to having a moment of creative insight, runs on one four-step cycle. They call it DIME.
StepWhat It DoesBrain System Behind ItDetectMatch incoming signals against known patternsPredictive coding (the brain constantly predicting and catching surprises)IntegrateFold new information into your ongoing mental contextMemory engrams (those cell assemblies Tonegawa won the Nobel Prize for)MarkAssign value, urgency, and importance to everything currently activeNeuromodulation (dopamine, serotonin, noradrenaline, the amygdala)ExecuteAct on whichever threads carry the highest valueMotor output, behavior, internal simulation
The cycle runs continuously. At every scale. The same loop that processes a flash of light in your visual cortex over milliseconds also runs across hours when you’re consolidating a memory during sleep. Different cognitive functions, memory, perception, planning, even consciousness, are just different configurations of the same four-step cycle running on different brain regions.
I want to be clear about something: this paper hasn’t been peer-reviewed. It has zero citations. The math is more sketch than model. The authors acknowledge all of this. The full theory lives in a companion monograph on Zenodo that I haven’t read yet.
But as a lens for organizing what we know about brains and what we’re building in AI, it clicked for me immediately.
Three Out of Four Ain’t Bad. Except It Is.
Here’s the thing that hit me when I mapped DIME onto the agentic AI landscape.
We built three of the four steps. The entire industry built three of the four steps. And then we stopped.
Detect: Done. MCP connects agents to any tool, any API, any data source you can think of. It hit 97 million monthly SDK downloads. Browser agents read web pages. Code agents parse error logs and test output. Event listeners catch webhooks. The problem of “notice that something happened” is solved.
Integrate: Getting there. MemGPT gives agents a dual-tier memory system that works roughly like how your hippocampus talks to your cortex. DeepSeek literally named their sparse memory module “Engram” after the neuroscience concept. RAG systems retrieve relevant context. Agent skills load modular capabilities on demand. Context windows stretch to a million tokens. Not perfect. But real and improving fast.
Execute: Done. Claude Code writes multi-file patches and runs tests autonomously. It scores 79% on SWE-Bench, meaning it can solve four out of five real GitHub issues. Codex runs parallel tasks. Tool calling is standardized. Agents send messages, create pull requests, query databases, browse the web. The “do the thing” problem is solved.
Mark: Nobody built this.

Every agentic framework in production today goes directly from “here’s what I know” to “here’s what I’ll do.” The step that asks “does this matter, and how much, and compared to what?” is either missing or hardcoded by a human.
Let me make this concrete, because “missing value layer” sounds abstract until you see it in practice.
You’re running multiple agents. One monitors your deployment infrastructure. One tracks customer feedback. One watches competitor activity. One manages your calendar and email. They all produce output. Who decides which output deserves your attention right now? Currently, that’s either you (reading everything), a priority system you hand-built (brittle, can’t adapt), or you ask the LLM “is this urgent?” (no persistent state, no memory of what was urgent yesterday, recomputes from scratch every time).
Or think about OpenClaw, which 300,000 people use. Its heartbeat wakes the agent every thirty minutes to check a Markdown checklist. It works. But the checklist is static. A human wrote it. It can’t distinguish between “your production database is unreachable” and “someone posted in a low-priority Slack channel” except through rules someone anticipated in advance. If the situation changes, the rules don’t.
That’s the gap. Not execution capability. Not tool access. Not memory. Judgment. The continuous, adaptive sense of what matters right now, given everything else that’s going on.
What Your Brain Does That Your Agent Doesn’t
The neuroscience here is genuinely interesting, and it got a lot more interesting in 2025.
Dopamine does way more than you think. Most people know dopamine as the “reward chemical.” Feel good, get dopamine. That’s the pop science version, and it’s wrong. Two papers published last year expanded the picture significantly. A Nature paper showed that dopamine in one part of the brain encodes “action prediction errors,” essentially a teaching signal about what actions lead where, completely independent of whether those actions feel good. A Science Advances paper showed dopamine firing for completely neutral, valueless stimuli. Not reward. Not punishment. Just: “this was unexpected, pay attention.”
The marker system in your brain isn’t about pleasure and pain. It’s about what to learn from. What to consolidate. What to amplify and what to let fade.
The consciousness selection problem is still wide open. Nature published a landmark study in 2025: a seven-year adversarial collaboration in which the proponents of the two leading theories of consciousness designed experiments together to test which theory would win. Two hundred fifty-six participants. Three types of brain imaging. Preregistered predictions.
The result? Neither theory fully worked. Both got some things right. Both failed on key predictions. And the piece that neither theory could explain is exactly the piece DIME calls “Mark”: the selection mechanism. How does the brain decide which of the thousands of things it’s processing right now gets promoted to conscious awareness?
Your memories are value-filtered. Tonegawa’s work on memory engrams showed that memories stored in hippocampal cell assemblies can be reactivated by partial cues. But here’s the thing: not all memories survive. The ones that get tagged with emotional weight by the amygdala, the ones encoded during high-dopamine states, those consolidate. The rest decay. Memory isn’t a recording. It’s an editorial process, and the editors are your neuromodulatory systems.
Your brain doesn’t ask “is this important?” after the fact. It runs a continuous, multi-dimensional value signal alongside every computation. Dopamine says “that was surprising, learn from it.” Serotonin says “stay patient, you’re on a good trajectory.” Noradrenaline says “uncertainty is high, widen your search.” The amygdala says “this has emotional weight, consolidate it.” These signals aren’t bolted onto cognition. They shape it in real time.
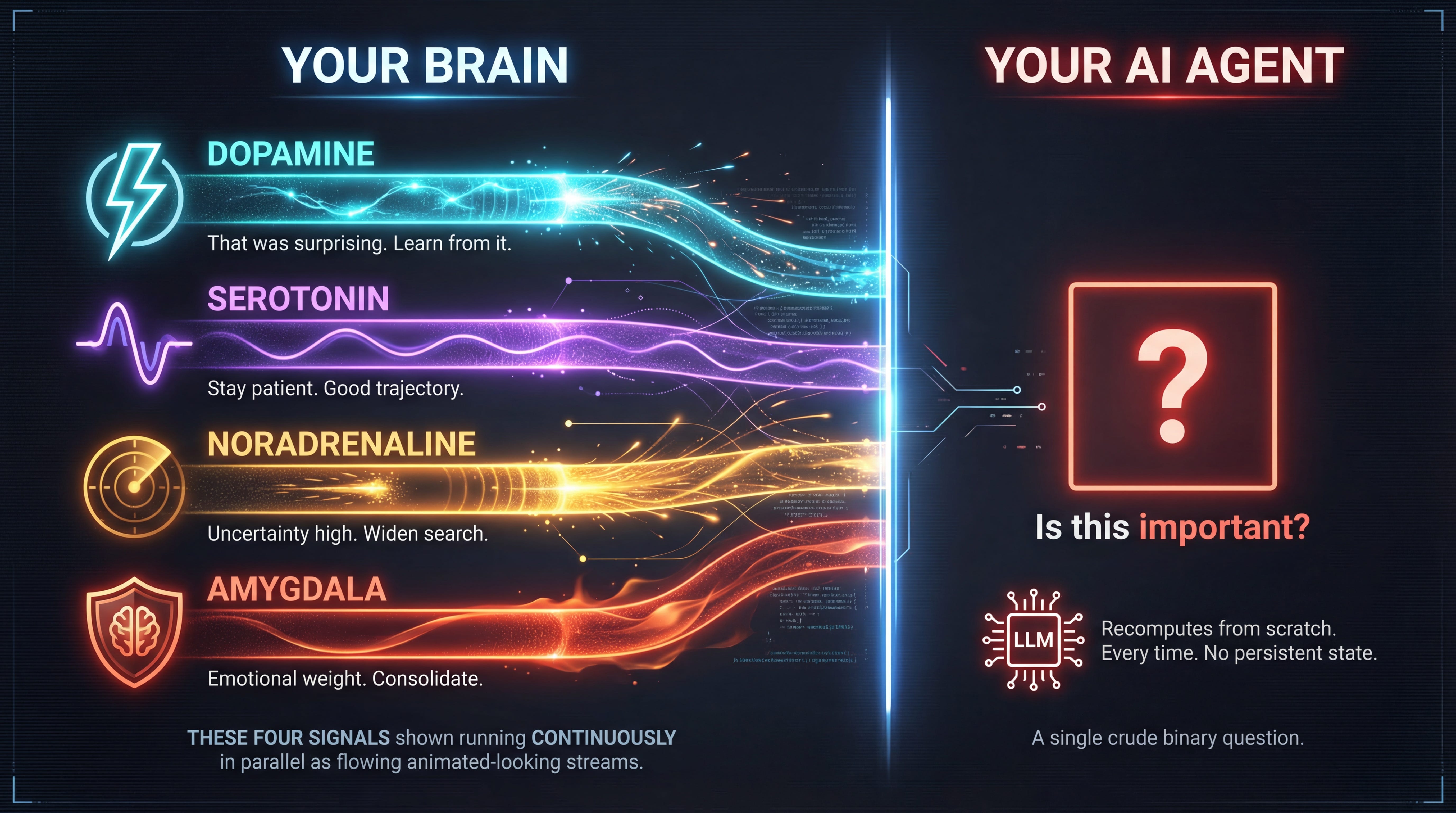
This is what DIME formalizes as the “marker field.” Not a post-processing step. A parallel computational stream that runs alongside everything else, continuously modulating which signals get amplified and which get suppressed. Value as an intrinsic property of every computation, not an external reward you bolt on after the fact.
So I Asked Claude to Build the Experiment
This is the part where things get a little surreal if you haven’t been paying attention to what AI coding tools can do now.
I described the experiment I wanted to run: four specialist AI agents, each optimizing a different aspect of a machine learning problem, with neuromodulatory control signals and a shared global workspace with value-weighted competition. Three experimental conditions. Logging, analysis, visualization.
Claude built the entire thing in ten minutes. Nineteen hundred lines of Python. A MarkerSystem class with four signals (dopamine, serotonin, noradrenaline, amygdala). A GlobalWorkspace class that receives broadcasts from agents, scores them with marker-weighted composites, and promotes the top findings while suppressing noise. Four specialist agents. A configurable CNN for CIFAR-10. An analysis pipeline that generates publication-quality plots. Documentation. A test suite.
Ten minutes. For an experiment that would have taken me a solid week to code by hand.
I’m telling you this not to brag about the tooling (though it is still wild to me), but because it illustrates exactly the point of this article. The Execute step in AI is incredible right now. Building things is fast. But knowing what to build, what to prioritize, which experiment to run next? That’s still on me. The agents that built the code have no opinion about whether this experiment is worth running. They just do what they’re told, perfectly and quickly.
That’s the missing Mark step, showing up in the tools I used to study the missing Mark step.
What the Experiment Tests
The setup is straightforward. Four specialist agents running on a GPU, each responsible for one dimension of a machine learning optimization problem: architecture search, hyperparameter tuning, data augmentation strategy, and regularization.
Three conditions:
Independent. Four agents, each running its own loop. No communication. Best result from any agent wins. This is most agent systems today: capable but isolated.
Naive sharing. All agents share everything with all other agents. Every finding goes into every context. No filtering. This is the “more information is always better” assumption. It’s also how most multi-agent systems actually coordinate: dump everything into a shared state file and hope for the best.
Full DIME. Each agent gets marker signals. Dopamine fires on surprising results, widening the exploration radius. Serotonin rises during improving trends, encouraging the agent to refine rather than restart. Noradrenaline spikes during high uncertainty, pushing the agent to try something fundamentally different. And an amygdala signal fires on breakthroughs, locking in the finding and broadcasting it with high priority.
All four agents share a global workspace. Findings compete for attention based on their value scores. A selector promotes the top three and suppresses the rest. Promoted findings get injected into every agent’s context. Suppressed findings get archived as one-line summaries.
Detect. Integrate. Mark. Execute. Running on a GPU for a few days.
The hypothesis is simple: DIME should beat naive sharing, and naive sharing should beat independence. Because intelligent, value-weighted selection should outperform both flooding agents with everything and giving them nothing.
Why This Matters If You’re Building with AI
I’ve spent the last year writing about the patterns underneath agentic AI. In Running Loops at Midnight, it was the convergence: small, proven components composing into systems that compound. In 1,000 Small Bets, it was the strategy: bottom-up experimentation beating top-down transformation. In Delegation, Not Automation, it was the philosophy: AI as a collaborator, not a replacement.
All of that still holds. But there’s a ceiling, and I think the DIME framework points at it clearly.
Composition got us incredibly far. MCP gave us the USB-C for AI tool connections. Reasoning models gave us agents that can make decisions, not just generate text. Cost compression made it feasible to run loops continuously. Open source made the building blocks available to everyone.
But if you’re building agents for anything more complex than a single-purpose loop, you’ve hit the problem. Your agent can do a hundred things. How does it decide which thing to do right now? Your multi-agent system produces a firehose of output. How do you surface the signal without drowning in noise? Your research agent ran fifty experiments overnight. Which ones deserve a deeper look?
Right now, the answer is: you write rules. Or you add another LLM call. Or you just look at everything yourself.
The neuroscience suggests a different answer. Build a value layer. Not as an afterthought. As a parallel system that runs alongside every computation. Multi-dimensional (not just one metric). Continuous (not checked periodically). Adaptive (learns what matters based on outcomes, not just what you told it to care about).
The next frontier in agentic AI isn’t more tools or faster models. It’s judgment. And a weird paper from Romania gave me a clearer way to think about what that means.
Part 2 of this series will have the experiment results. Did adding synthetic dopamine and serotonin to AI agents change anything? Did the global workspace improve coordination? I genuinely don’t know yet, which is the best kind of experiment.
In the meantime, the DIME paper is at arXiv:2603.12286, and the experiment code will be open-sourced when it’s done.
It is the OODA loop with different labels.