
Claude Science and the boring 80 percent
Anthropic shipped a workbench, not a miracle. The model is the commodity layer. The harness around it is the moat.


Anthropic shipped Claude Science today, an AI workbench for scientists. The launch page leads with proteins and genomics and a reviewer agent that checks your citations. That is the surface. The interesting part is what they chose to build it on, and what they chose not to promise.
A workbench is a boring word on purpose. It is the thing the interesting work happens on top of. Anthropic picked that word over "discovery engine" or "research copilot," and the choice tells you where they think the advantage sits.
What actually shipped
Claude Science is a local-first app that runs on your laptop, your Linux box, or your HPC login node. A generalist agent coordinates sixty-plus skills and connectors pre-wired for genomics, single-cell, proteomics, structural biology, and cheminformatics. It renders 3D protein structures and genome-browser tracks and chemical structures inline, next to the code that made them.
Three design decisions are worth pausing on, because they are not how most "AI for science" products are built.
Every figure ships with its own recipe. When Claude Science generates a plot, it bundles the exact code and environment that produced it, a plain-language description, and the full message history. Six months later you can reopen it and see what was actually run. This is the reproducibility crisis spoken to directly, not as a slogan but as a file format. Every artifact is auditable by construction.
The output is not the figure. The output is the figure plus the complete record of how it was made.
Compute is a thing the agent manages, not a thing you schedule. Folding a protein or running a genomics pipeline across a huge dataset usually means stopping your work to write a job script, submit it to the cluster, wait, check whether it failed, pull the results back. Claude Science drafts the plan, asks before it spends new resources, and lets you revoke any decision before it writes and submits the job to the infrastructure you already use. Your HPC cluster over SSH. Your Modal account for compute on demand. One GPU to hundreds.
The detail that does the work: datasets load once into a running session and stay in memory. Large or sensitive data never has to leave the systems it already lives on. Only the slice of context a given step needs goes to the model.
The tooling layer is not theirs. This is the move most people will miss. Claude Science does not ship its own protein-folding model. It talks to NVIDIA's BioNeMo natively, which means Evo 2, Boltz-2, OpenFold3 are one call away. Anthropic orchestrates. The scientific models belong to the tooling layer.
The layer cake
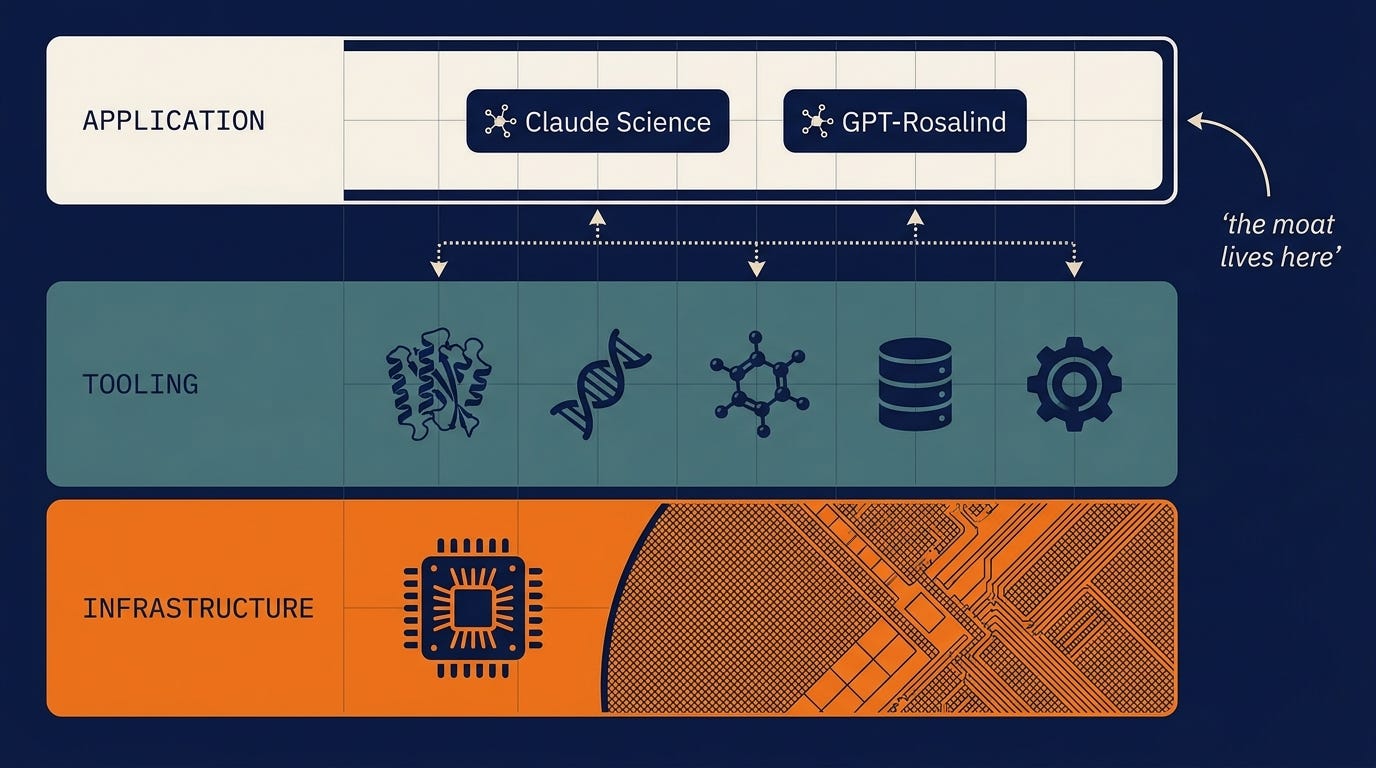
The shape of the market is already clear. AI-for-science is stratifying into three layers, and it rhymes with the stack we already know.
The application layer is the orchestration surface, the thing the scientist talks to. Anthropic and OpenAI's GPT-Rosalind compete here. The tooling layer is the scientific models and databases, BioNeMo and Boltz and AlphaFold. The infrastructure layer is the silicon. Each layer is a real business. The tooling and silicon layers are where the heavy capital and the specialized models live, and the companies there, NVIDIA especially, keep doing the hard work that everyone in the application layer stands on.
Anthropic's bet is narrower and smarter than "best model." The model is becoming the commodity layer. The harness around it is where the moat gets built.
The whole launch is a platform play, not a model play. John Jumper, the Nobel laureate behind AlphaFold, announced he was leaving Google DeepMind for Anthropic eleven days before this launch. The Coefficient Bio acquisition bought target-discovery talent. The partnerships with the Allen Institute, the Broad, Schrödinger, Sanofi, and HHMI are integration deals. The moat being built is workflow integration, not raw model capability.
We have been here
I have been arguing this for a while. The model is the commodity layer. The harness, the system of skills and memory and agents and hooks and connectors that sits around the model and makes it useful, is the moat. I wrote a whole Run Data Run essay on it, and a book chapter. The argument was built on watching what happened when you swapped the model out from under a working agent system and the system barely blinked, because the intelligence lived in the scaffolding.
Claude Science is that argument, built into a product, for science.
The clearest version I have seen up close is a research flywheel we run in my group. It is an autonomous agent that runs continuously, generating and refining research ideas at the intersection of AI and biotechnology, promoting the promising ones to execution on a GPU box, critiquing its own results, and self-healing when a run corrupts. Over an eighteen-week deployment across seven instances it ran 5,196 consecutive commits without a human touching it, with a 97.8 percent autonomous resumption rate. The expensive, interesting part is not any one model call. It is the loop: the weighted idea pool, the adversarial critique, the self-heal, the provenance on every artifact. Swap the underlying model and the loop keeps turning. The loop is the asset.
That is the same shape Claude Science is reaching for, at platform scale. The sixty pre-wired skills. The reviewer agent that checks citations and calculations as the pipeline runs. The session that holds context in memory and forks to compare two approaches. Every one of those is a harness component. None of them is a model.
The model is the part you can rent. The harness is the part you build. Claude Science just shipped sixty reasons to build it for science.
Two reviews worth reading
Two of the beta stories in the launch tell you what this is actually good at, because neither is a discovery claim.
Jérôme Lecoq, a neuroscientist at the Allen Institute, used Claude Science to build a roughly twenty-skill pipeline that writes long-form computational reviews. Sub-agents read thousands of papers, pull the central claim and the key number, and store them in an evidence database. Then a pipeline builds a narrative arc, delegates each section to a specialist, and dedicated agents generate cross-study figures straight from the evidence. The core trick is actor-critic pairs: one agent writes, a separate reviewer agent checks it for accuracy and citation fidelity.
Before Claude Science, that kind of review took his team up to two years. He now has about ten of them, many over a hundred pages, with citations the reviewer agents vetted.
Two years collapsed to weeks, on the part of science that is reading and synthesizing and checking, not on the part that is having the idea.
Stephen Francis, an epidemiologist at the UCSF Brain Tumor Center, used it for germline workups on glioma susceptibility. His lab had done this work before. Claude Science compressed the analysis to roughly a tenth of the time, and his group independently validated the results.
Neither man claims a discovery. Both claim compression of the tedious majority of the work. That distinction is the whole product.
What it does not do
Here is what Claude Science is not, and what the launch page does not claim it is.
It is not a drug-discovery engine. Zero AI-discovered drugs have FDA approval. The ninety-percent clinical failure rate has not moved. The biomolecular models in the tooling layer underneath it work well for structure prediction and initial screening, and they are getting better fast. They are not yet where you want them for the decision that gates a program. A careful recent evaluation (Wan and Coveney, UCL) of one of those models on thirty-eight thousand compounds found strong performance on structure but weaker correlation with physics-based binding free energies at the candidate end, where a medicinal chemist actually bets. That is not a knock on the model. It is where the whole field sits in 2026, and the field knows it.
The pattern is one the coding world already learned. The benchmark looks good. The transfer to the real decision is the harder, slower climb. The structure-and-screening work compresses. The lead-identification work does not, yet.
AI compresses the eighty percent of science that was already tractable. The twenty percent that kills programs stays expensive.
The framing Brendan Frey, the Deep Genomics CEO, gave Drug Target Review is the one to hold onto: "AI has really let us all down in the last decade when it comes to drug discovery. We've just seen failure after failure." Anthropic's head of life-sciences partnerships, Jonah Cool, has been consistent that the target is the tedious intermediate work, data analysis and annotation and coordination. The launch page repeats that framing almost verbatim. A company sitting on a $965 billion valuation, under pressure to grow, chose to launch a workbench and not a miracle.
Why a builder should care
If you lead a data or AI team in the sciences, three things are now true and worth acting on.
The first is that the integration layer is where the money and the moat are going. The specialized models, the folding and docking and single-cell tools, are commoditizing fast as the tooling layer matures. Your durable advantage is not which model you run. It is how well you connect the models to your proprietary data, your lab's instruments, your validated pipelines. Claude Science lets you save any pipeline as a reusable skill and inherit it in future sessions. That is the shape of the advantage. Build the connective tissue, not the model.
The second is that the reproducibility-by-construction pattern is going to spread. Every figure carrying its full provenance, the code and the environment and the message history, is the answer to a problem every R&D leader has been screaming about for a decade. If you are building internal tooling, steal the pattern wholesale. The artifact is not the output. The artifact is the output plus the audit trail.
The third is the scope limit. Claude Science will accelerate the boring eighty percent of your scientists' work, the literature synthesis and the pipeline glue and the figure iteration, and it will do it well. It will not pick your drug target. It will not replace your physics-based validation on the decisions that gate a program. Plan for the compression. Do not budget for the cure.
What I'd watch
The beta is open today for Pro, Max, Team, and Enterprise on macOS and Linux. There is a discounted Team plan for academic labs and nonprofits, and Anthropic is funding up to fifty AI-for-Science projects with up to $30,000 in credits (Modal adds $2,000 of compute). Applications close July 15.
The thing to watch is not the launch. Launches are easy. Watch whether the reviewer agent actually catches the citation and calculation errors six months in, when the novelty has worn off and the session histories are long. Watch whether scientists trust it enough to save their hard-won pipelines as skills and let the next session inherit them. That trust, not the protein renderer, is what earns the workbench a permanent place on the bench.
Launches are easy. Trust earned over long session histories is the hard part.
Anthropic shipped a workbench. They named it for what it is. The science was always eighty percent grinding and twenty percent insight, and the insight was never the part that took the time.
The papers
Claude Science, an AI workbench for scientists, is now available. Anthropic, Jun 30 2026. The launch.
NVIDIA launches BioNeMo Agent Toolkit. The tooling layer Claude Science orchestrates over.
Modal integration brings scalable compute to Claude Science. The on-demand compute leg.
On the Reliability of AI Methods in Drug Discovery: Evaluation of Boltz-2. Wan and Coveney, UCL. The reality check on binding affinity prediction.
Get started with Claude Science. The product.
This is a Run Data Run essay. If it was useful, the easiest way to support it is to subscribe and forward it to one person on your team who'd want it. If it wasn't, tell me why.