
And Neither Could Do Alone...
100 GPU-Hours with an AI Research Partner

HuggingFace recently published a blog post about giving Claude the ability to submit fine-tuning jobs to their cloud infrastructure. It’s a clean implementation: describe what you want, Claude handles the rest, and you get a trained model back.
What caught my attention wasn’t the capability itself—it’s that this is now unremarkable. A year ago, fine-tuning a language model required dedicated ML engineering time. Six months ago, it required knowing the right incantations of LoRA configurations and learning rate schedules. Today, you can describe the outcome you want and an AI handles the implementation details.
I’ve been living in this world for the past three months. Not as a preview user of HuggingFace’s Skills feature—though I’ve used that too—but through something messier and more revealing: 100+ GPU-hours of fine-tuning experiments run in collaboration with Claude on local hardware.
The results aren’t the interesting part. The process is.
The Experiment Log
Here’s what accumulated over October through December:
Medical QA: Started at 70% accuracy on PubMedQA. Eight iterations later, 92.4%. The breakthrough wasn’t a clever technique—it was Claude identifying that we’d been using the wrong training abstraction. A different library function, same underlying math, fourteen percentage points of improvement.
Oncology Specialist: A 27-billion parameter model fine-tuned on domain-specific data. Head-to-head against a general-purpose 120B model, it tied. Same quality answers at one-fourth the parameters, one-quarter the inference cost. We published it to HuggingFace.
Multimodal Pathology: Three models in seven days—a classifier hitting 97% accuracy, a question-answering system, and a regression model that taught us why some architectures can’t learn certain tasks no matter how much data you throw at them.
Self-Play Reasoning: An experiment in having a model generate its own training curriculum. Twenty-two hours of training before we discovered a fundamental bug in how gradients were being computed. Zero improvement, maximum learning.
I documented pieces of this in previous posts, but the synthesis is worth examining.
What Actually Happened
The story isn’t “human directs AI to execute tasks.” It’s closer to “human and AI iterate toward solutions neither could reach alone.”
Consider the medical QA experiments. I knew the goal: improve accuracy on medical questions. Claude knew the implementation landscape: which libraries existed, which configurations worked, which failure modes to watch for. Neither of us knew which specific combination would work until we tried it.
Experiment one: 70% accuracy. We discussed hypotheses. Was it the learning rate? The number of epochs? The way we formatted the training data?
Experiment four: 82% accuracy. Progress, but plateauing. Claude suggested we were overfitting—training loss dropping while validation loss crept up. We adjusted.
Experiment eight: 92.4%. The change that mattered wasn’t hyperparameters. It was switching from one training utility to another that handled our data format more intelligently. Claude had suggested it earlier; I’d dismissed it as equivalent. It wasn’t.
This is the pattern that repeated across all the experiments: hypothesis → implementation → observation → new hypothesis. The loop that defines research, running at a different clock speed.

The Infrastructure Invisible
What makes this work isn’t the AI’s intelligence—it’s the infrastructure that lets intelligence compound.
When a training run fails at 3 AM, the error message is captured. When I return the next morning, Claude can analyze the failure, propose fixes, and we iterate. The context persists. The knowledge accumulates.
When we discovered the GPU inference bug—a hardware-specific issue where evaluation on certain chips produces garbage outputs—Claude helped isolate it, document it, and work around it. That knowledge now lives in our shared context. Every subsequent experiment avoids the trap.
When the self-play experiment ran for twenty-two hours without improvement, Claude helped trace the bug to a subtle issue in how we were computing gradients. The model was “training” but weights weren’t updating. Debugging that required reading PyTorch internals, understanding automatic differentiation, and methodically testing hypotheses. It took hours of collaboration to find a bug that took seconds to fix.
None of this is glamorous. It’s the unglamorous work that makes the glamorous results possible.
The HuggingFace Question
So where does HuggingFace’s Skills feature fit?
It’s the right tool for a different job. When you want to quickly test whether fine-tuning helps at all, when your model fits in their infrastructure constraints, when you want to minimize configuration overhead—use it. We did, for several smaller experiments.
But the experiments that mattered—the 27B oncology model, the multimodal pathology work, the self-play reasoning attempts—required local execution. Not because cloud is bad, but because we needed:
Models too large for standard cloud allocations
Training methods not yet supported by managed services
The ability to debug at 2 AM when something breaks mysteriously
Privacy constraints that kept data on local hardware
The point isn’t that one approach is better. It’s that the same AI collaboration pattern works in both contexts. Claude doesn’t care whether it’s submitting a job to HuggingFace or orchestrating a local training run. The conversation is the same: What are we trying to achieve? What went wrong? What should we try next?
What This Means
For scientists: The barrier to custom model development just dropped by an order of magnitude. Domain expertise matters more than ML engineering knowledge. If you understand what a model should learn, the how is increasingly automatable.
For leaders: The timeline on AI capabilities is compressing. Three months ago, I couldn’t have run these experiments in this timeframe. The compound effect of better tools, better models, and better integration means the gap between “idea” and “trained model” keeps shrinking.
For everyone: This is what research collaboration looks like now. Not human-or-AI, but human-with-AI. Not delegation, but iteration. Not replacement, but amplification.
The medical QA model that went from 70% to 92.4%? I couldn’t have built it alone—I don’t have the ML engineering depth. Claude couldn’t have built it alone—it needed someone to define what “better” meant and to make judgment calls when the path wasn’t clear.
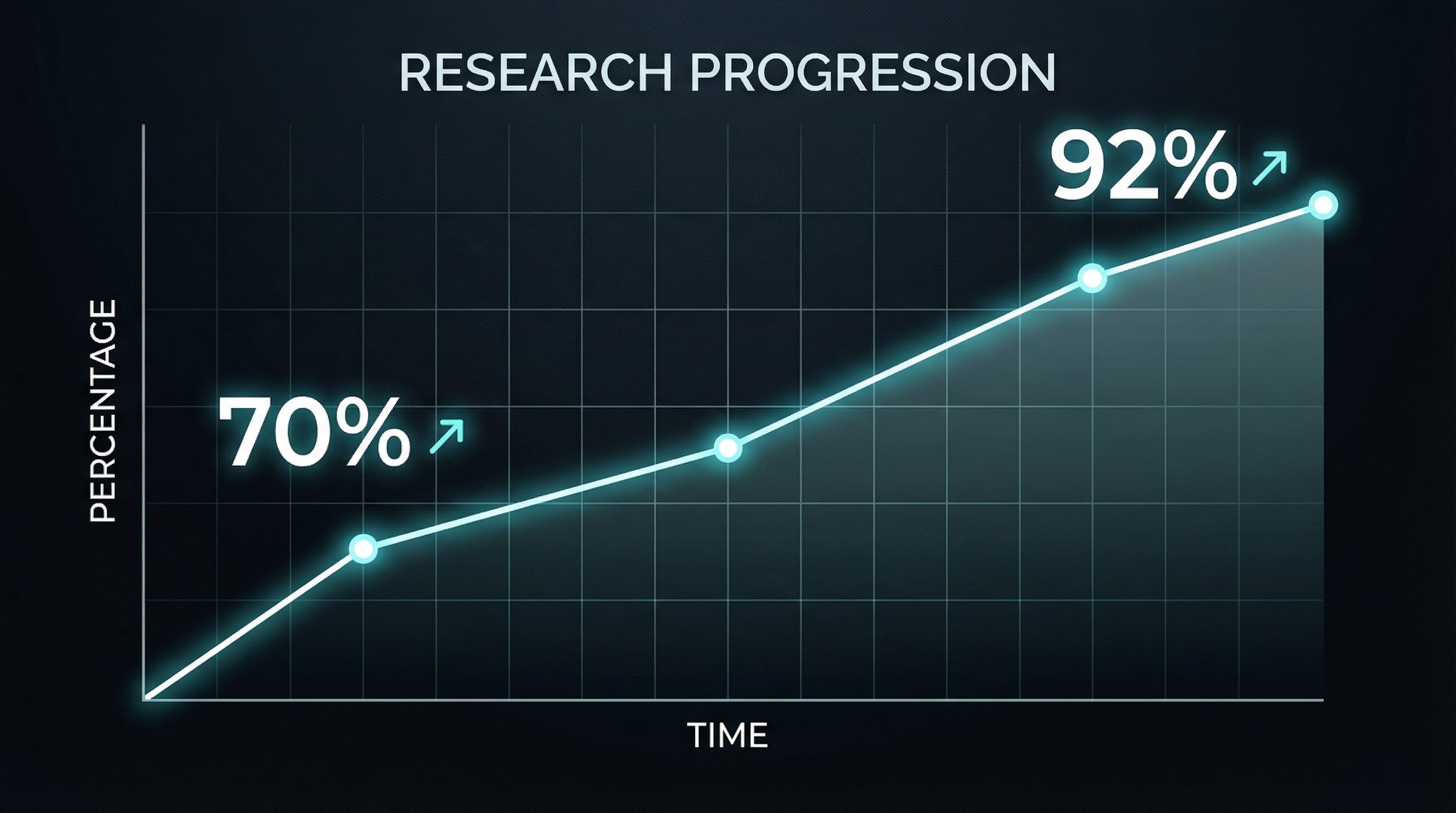
Together, eight experiments in five days. A 22-point improvement. Published to HuggingFace for others to use.
That’s the flywheel. And it’s just starting to spin.
This continues themes from The Quiet Week Claude Became Your Coworker and Compound Velocity: The 20-Hour AI Research Lab. The experiments described were conducted on NVIDIA DGX Spark hardware over October-December 2025.