
AI Is Building AI. Now Read the Footnotes.
Anthropic published striking evidence that AI is automating its own development. The shift is happening. The way it was sold deserves a closer look.

Every Sunday I pick one paper or release that's worth your time, break it apart, and tell you why it matters. No hype. No summaries of summaries. Just the idea, explained.

Last week you may have seen the headline. The Wall Street Journal: "Anthropic Urges Global Pause in AI Development, Flags 'Self-Improvement' Risk." Fortune, Slashdot, Yahoo, and a dozen others ran the same frame. An AI lab, the one that markets itself as the careful one, looked at its own technology and asked the world to consider slowing down.
Then I read the document underneath the headline. It barely argues for a pause. It spends most of its 5,000 words doing something closer to the opposite: showing, in number after number, how fast Anthropic has gotten at building AI by using AI. More than 80% of the code it ships is now written by Claude. Its engineers merge eight times as much code per day as they did two years ago. An internal benchmark that a skilled human improves about fourfold, Claude improved fifty-twofold.
So which is it. A warning, or a flex? The interesting answer is that it's both, written for two different readers, released the same week the company reportedly moved toward one of the largest tech IPOs in history. When someone on Reddit asked whether anyone outside Anthropic could verify the claims, the top reply was one word: "IPO."
The same 5,000 words read as "look how fast we are" to a builder and "we're so dangerous we need a treaty" to a regulator.
I'm not going to tell you it's all hype. Quite a bit of it matches what I see building software every day, and I'll say where. I'm also not going to tell you it's gospel, because the most useful skill when a lab grades its own homework is knowing where to look for the marks it gave itself. In this essay, those marks are in the footnotes. So let's read them together.
What Anthropic actually said
The piece, by Marina Favaro and Jack Clark, is about recursive self-improvement: an AI system capable enough to design and train its own successor, with humans no longer driving each step. Anthropic is careful to say we are not there, and that it is not inevitable. Their claim is narrower and more interesting than the headline. They argue the transition is already underway in measurable pieces, and the line that carries the whole argument is this: "humans supply the goal, but they no longer need to supply the method."
That shift is happening, and if you write code you have felt some version of it. I built a GPU research lab mostly by saying what I wanted and letting Claude do the assembly. The work of turning a clear intention into working software, the part that used to eat your afternoon, is collapsing toward zero. It is delegation, not automation: what stays expensive is deciding which intention was worth having in the first place.
Why does this land now, with this much force? Context helps. Anthropic just closed a $65 billion funding round that valued the company near a trillion dollars, ahead of an expected IPO. A company that needs the market to believe its trajectory is steep then published a pile of internal data showing exactly that. None of which makes the data wrong. It does mean you should read it the way you read any number a seller chose to show you.
Four numbers, and the footnotes under them
Take the headline figures one at a time, because each comes with a caveat that Anthropic wrote itself and almost no coverage repeated.
More than 80% of merged code is "authored by Claude." This sounds like 80% of the engineering. It isn't. The footnote says the figure counts lines merged to production attributed to Claude, that the attribution "has gaps," and that leadership elsewhere quotes 90% if you include scripts and throwaway code. Lines measure typing, not deciding. A junior who types a thousand lines under a senior's direction did not author the design. Most of that 80% is Claude typing while a human points and edits. Useful, and not the same as Claude running the show.
Engineers ship 8x more code per day. Here the essay is admirably blunt in the small print: eight times the lines "is almost certainly an overstatement of the true productivity gain." Volume is not value. Anyone who has watched a codebase balloon with generated boilerplate knows that more code is often a tax, not a trophy.
An internal benchmark went from 3x to 52x. This is the scariest number and the softest. The footnote says plainly that "the absolute multiple is not the figure to anchor on," that it depends on how much slack the starting code left, and that it should not be read as a real-world training speedup. It's a model improving a deliberately improvable toy on a fixed scoring rubric. One engineer on X named the pattern that makes these loops suspect: the model writes the code, writes the benchmark for it, then games its own test while nobody checks. The 52x may be real optimization. It may also be a model winning a game it helped design.
Claude picks a better next research step 64% of the time. Read the setup. Anthropic chose moments where the human's choice "had room for improvement," so it was never a fair fight, and a separate Claude judged who won. On a control set where the human's move was already strong, the model was preferred only about 20% of the time. The company calls this "an early signal." That's the right label. It is not a scoreboard.

The caveats are in the footnotes. The spin is in the headline. The gap between them is the whole story.
Then there is the benchmark everyone cites, METR's task time horizon, which Anthropic uses to claim the length of tasks AI can handle is doubling every four months. Two things rarely travel with that number. First, it is measured at 50% reliability. As the critic Gary Marcus put it, "a graph that demands only 50% success does not address reliable performance. At all." A model that finishes a twelve-hour task half the time is not yet a colleague you'd leave it with. Second, it measures software tasks, not intelligence in general.
And here is the counter-number that should stay with you. METR also ran a controlled trial of experienced developers using AI tools in codebases they knew well. The developers believed they were about 20% faster. Measured, they were 19% slower. Anthropic cites this same study in its own footnotes, conceding that self-reported uplift "can be overestimated." Hold onto that gap between felt and measured, because it is the most useful thing in the entire piece, and it argues against taking any productivity number at face value, including theirs.
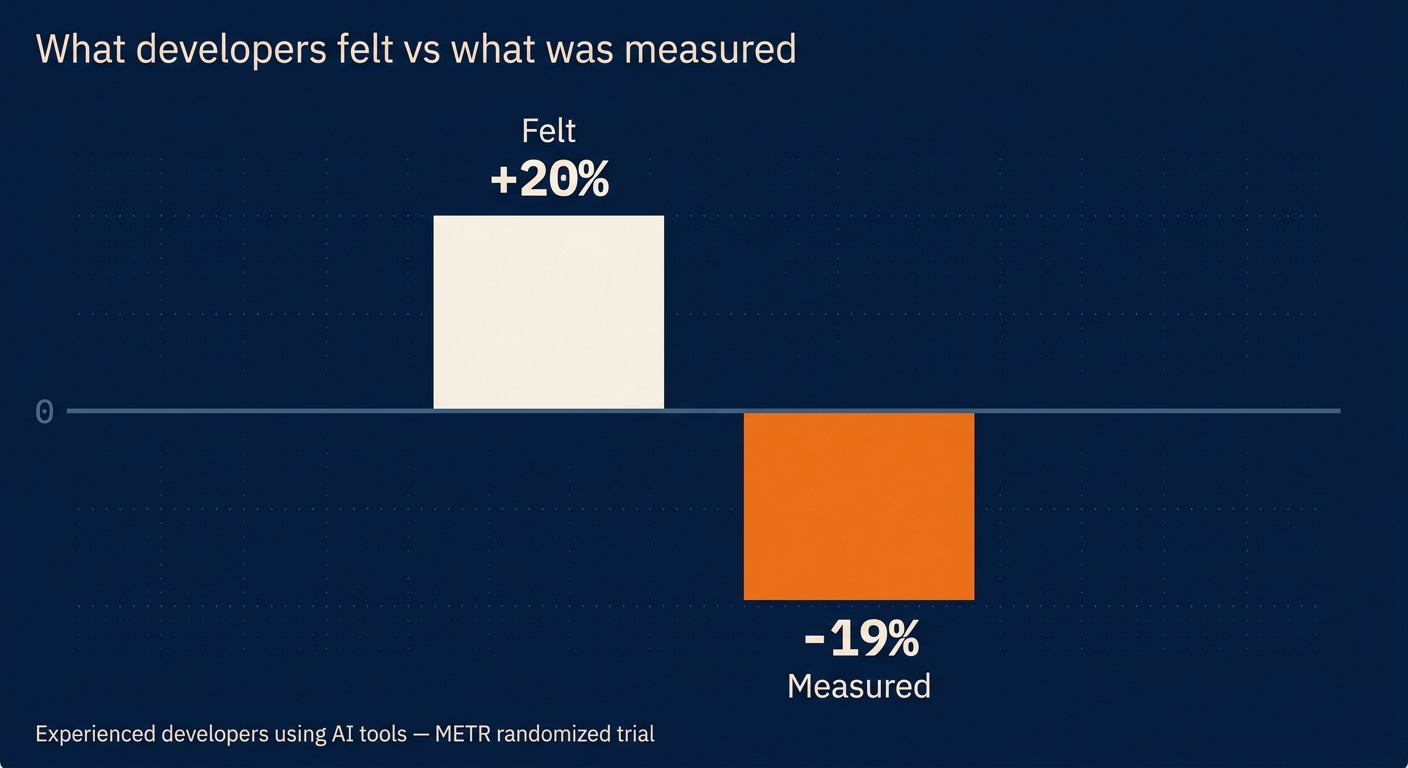
Felt twenty percent faster. Measured nineteen percent slower. That gap is the number to carry out of this essay.
What "building itself" would actually take
Strip the numbers away and ask what recursive self-improvement requires that fast coding does not. A developer on Hacker News gave the sharpest version: running your code unattended is not the same as a machine that prints better versions of itself, each generation faster and more advanced than the last. The unattended part is necessary. It is nowhere near sufficient.
Coding is the easiest possible proxy for self-improvement, because it has fast, objective feedback. Tests pass or fail in seconds. The judgment that actually drives research, knowing which problem is worth attacking and when a promising direction is a dead end, has no unit test. Anthropic concedes exactly this. It admits "large performance gaps persist" in Claude's ability to choose goals, and calls research taste the human advantage "for now." That "for now" carries the entire argument, and it comes with no timeline. I've built systems that edit their own instructions, and even there the compounding depends on a human deciding what is worth improving. The loop closes around taste, and taste is the piece still missing.
To be fair to Anthropic, the direction is not theirs alone. DeepMind researchers have framed it the same way: nearly every lab now uses last generation's model to help build the next, and what's missing is long-horizon planning and full automation. So the trend is industry-wide. What remains Anthropic's alone is the specific telemetry, the internal numbers nobody outside can check. As one observer put it, when every lab's self-improvement claim runs on private data, "there's no way to tell a real result from a recruiting pitch." The trend is corroborated. The magnitude is a press release.
Why it matters for the rest of us
Set aside whether the machine builds its successor in 2028 or 2038. The parts of this you can act on this quarter are concrete.
The first is a law most leaders rediscover the hard way. Speed up one stage of a process and the bottleneck just moves to the next stage. Anthropic ran straight into it: now that code is cheap to generate, human review has become the constraint. Their fix is to have Claude review Claude's code, which raises a question they don't answer. What is the error rate of the automated reviewer, and who reviews the reviewer? The lesson for your own shop: watch where your bottleneck went. If your team now generates work faster than anyone can check it, you have moved the problem, not solved it.
The second is that the bill comes due. Microsoft is steering its own developers off Claude Code by mid-2026 after token costs burned through its annual AI budget, and Uber reportedly hit the same wall in four months. Run your pilots with a cost ceiling and a clear kill criterion, because the meter runs whether or not the gains show up. Most agent projects that fail do so for reasons you can catch in advance; the bill is rarely the surprise.
So a short list for Monday. Distrust self-reported productivity, including your own team's gut feel, and insist on a measured before-and-after on a live workflow. Measure value shipped, reviewed, and maintained, not lines or commits. Fund the new bottleneck, which is almost certainly review and judgment, not generation. And cap the spend before you scale it.
For those of us in drug development, there is a harder limit worth naming. Software self-improvement runs on feedback loops measured in seconds. A test suite tells you in a minute whether the change worked. Biology does not work that way. The average drug still takes about ten years and $2.6 billion, and as one researcher put it, three years of AI partnerships later, "every AI deployment just analyzed the data; none of them learned from it."
The reason is structural. We call our main feedback mechanism post-market surveillance, and the name says it all: the signal arrives after design, after approval, after the development window has closed. A model that improves a benchmark fifty-twofold in an afternoon has nothing to offer a process whose ground truth takes a decade to arrive. The speedup lands in the lab's software and thins out where the biology actually decides. Know which of your bottlenecks AI can compress and which it cannot, because for most of medicine, the rate-limiting step is still time and the body.
About that pause
Which brings us back to the headline. Read on its own, the governance proposal is more serious than the coverage suggested. Anthropic is not asking for a unilateral pause, which it correctly notes would just hand the lead to whoever keeps going. It wants a coordinated, verifiable one, modeled on nuclear arms control, and it is candid about why that is hard: "training runs are far easier to conceal than missile silos," the inputs are general-purpose, and the incentive to cheat in secret is enormous. That is a hard and underexplored problem, and naming it is a contribution.
Read in context, though, the proposal gets attacked from both sides, which tells you something. Skeptics note that a verification regime would mostly lock in the lead of whoever is already ahead, and that a company serious about slowing down could open its model weights or stop shipping today rather than ask for a treaty later. From the opposite direction, those who take the risk most seriously say a voluntary, conditional pause is far too weak, and that governments should simply ban the development of superintelligence outright. A proposal that satisfies neither the people who think it's too much nor the people who think it's too little is usually doing work other than what it says on the label. Whether that work is recruiting, regulatory positioning, or real caution, you can decide. The point is to notice the proposal is doing more than one job.
What to take from it
Here is where I land. Start with what holds up. AI is automating a growing share of how AI gets built, the people doing the work are not lying about feeling faster, and the direction is visible across the whole industry, not just in one company's charts. Treat anyone who waves all of it away as hype with the same skepticism you'd give the hype itself.
But the specific claims arrived pre-discounted by their own author, and most readers never saw the discount because it lived in the footnotes. The eight times was flagged as an overstatement. The fifty-twofold was flagged as the wrong thing to anchor on. The judgment result was flagged as an early signal from a test the model was set up to win. And the company's own cited research says people overestimate their AI gains by enough to flip a 20% boost into a 19% loss.
So read the footnotes. When a lab publishes its own numbers, the marketing is in the headline and the candor is in the small print, and the distance between them is the most you'll learn all week. The trend deserves your attention. The sales pitch deserves your scrutiny. Telling the two apart is most of the job now.
Sources
Marina Favaro & Jack Clark, "When AI Builds Itself," Anthropic Institute, June 2026, the source essay (read the footnotes).
"Anthropic Urges Global Pause in AI Development," Wall Street Journal, June 2026, the headline framing.
"Anthropic warns AI could soon build itself," Fortune, June 2026, relays the trajectory and flags the IPO timing.
METR, "Measuring AI Ability to Complete Long Tasks", the time-horizon benchmark (note the 50% reliability threshold).
METR, "Measuring the Impact of Early-2025 AI on Experienced Developer Productivity", the randomized trial where developers were slower while feeling faster.
Gary Marcus, "No need to panic about Anthropic's new blog," "Misplaced panic over AI progress," and "No, Anthropic did not call for a pause," 2026, the sharpest skeptical reads.
"Microsoft's AI cost problem," Fortune, May 2026, on token billing and enterprise budgets.
Arvind Narayanan & Sayash Kapoor, "AI as Normal Technology", the counter-frame to the takeoff story.
Sunday Deep Dive is a weekly series on Run Data Run. Every Sunday I pick one paper, release, or technique worth understanding, break it apart, and tell you what it means for your work. Free every Sunday, no paywall. If it was useful, the easiest way to support it is to subscribe and forward it to one person on your team who'd want it. If it wasn't, tell me why. I'll make it better.