A new paper asks a question that sounds simple and turns out to have teeth. When a frontier model fails at “reasoning,” what is it failing at?
Their answer is a number. They call it Relational Complexity, and it predicts model failure better than anything else they measured.
The paper, “Evaluating Relational Reasoning in LLMs with REL” from Fesser, Ektefaie, Fang, Kakade, and Zitnik, borrows a construct from cognitive science. Relational Complexity (RC) is the minimum number of entities a system has to hold in mind and bind together at once to take a single reasoning step. “A is taller than B” is RC=2. “A is between B and C” is RC=3. The number climbs as the relations get wider.
The finding is clean and a little grim. As RC goes up, accuracy falls off a cliff, and nothing the authors tried pulled it back.
What they measured
The clever part is the benchmark itself. REL is a generative framework, not a fixed test set. It produces as many problems as you want at any RC level, across three domains the authors deliberately picked to look nothing alike: pattern-completion puzzles (Raven’s matrices), phylogenetic trees in biology, and molecular isomers in chemistry.
Why three unrelated domains? Because that lets them hold everything else constant. Same vocabulary, same input length, same task format, only the RC dial moving. Most reasoning benchmarks can’t separate “the task is harder” from “the task has more words” or “the task is in an unfamiliar domain.” REL can.
Hold vocabulary, length, and format fixed, move only the relational complexity, and watch the accuracy curve bend. That is the whole experiment, and it is enough.
They ran it against Claude Opus 4.5, Gemini 3 Pro, and GPT 5.2.
The numbers
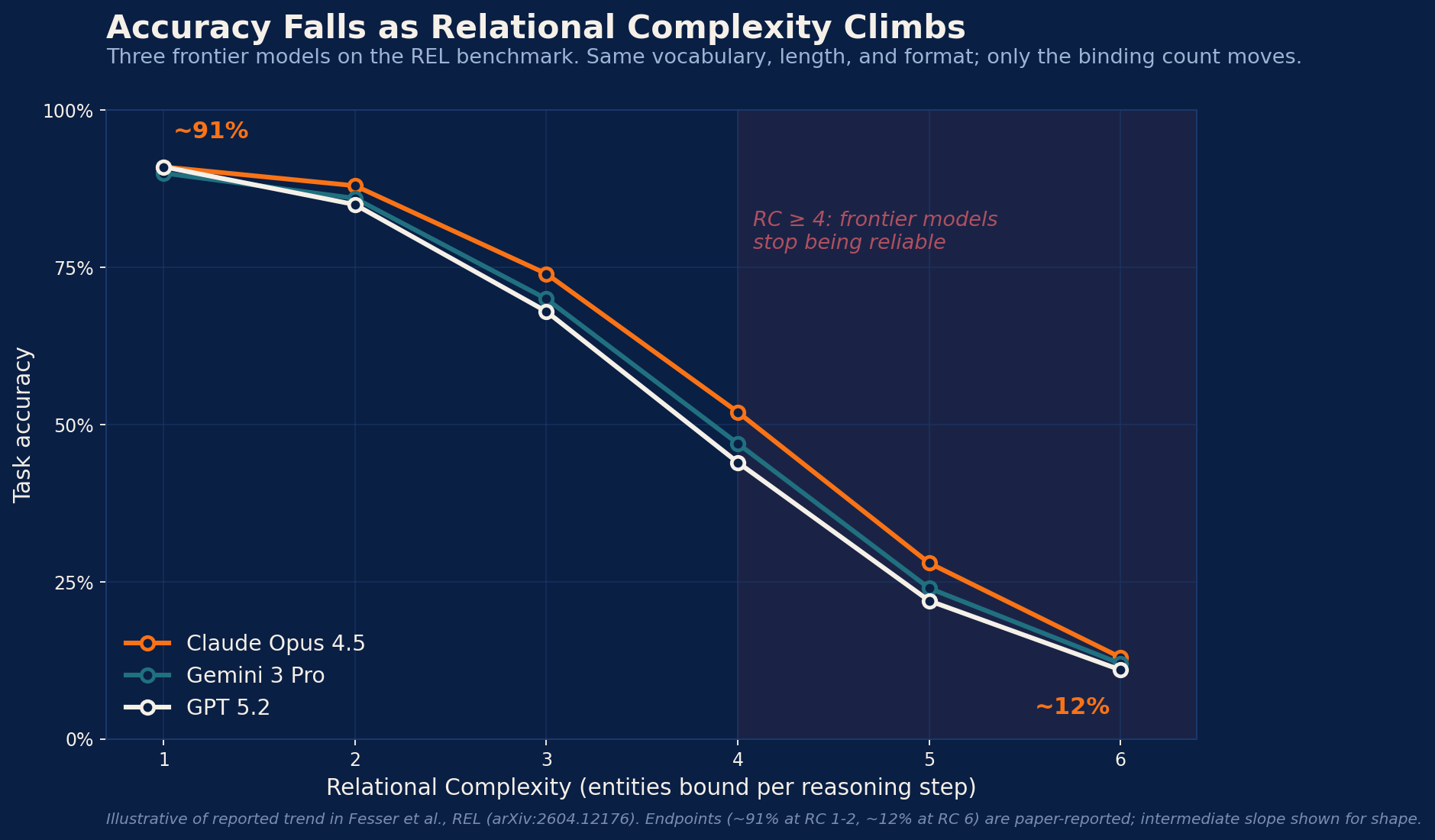
At low complexity, the models look great. The pattern puzzles at RC=1-2 land around 91% accuracy across all three models.
Then it collapses. Scale the matrices up, push RC to 6, and Claude and Gemini drop to roughly 12%. The biology task tells the same story: phylogenetic homoplasy detection runs at 35% with four taxa and falls to 1% at twenty-five taxa.
The authors then did the thing most benchmark papers skip. They ran a regression to check whether RC was actually the driver or just correlated with something else. With collinearity controls in place, RC explained 24 to 44% of the explainable variance. The next-strongest factor topped out at 17%.
It is not input length. It is not domain. It is the binding count
.
And the interventions did almost nothing. Extra test-time compute bought 2 to 3%. In-context examples bought 3 to 6%. Tool use, handing the chemistry model RDKit so it could compute instead of reason, produced a mean recall of 0.094 that got worse as the problem grew.
The gap is structural. You don’t prompt your way out of it.
Think about what your agent does when it stalls on something that “should” be easy. A cross-document join where it has to reconcile three sources at once. A planning task with four interacting constraints. A loop where it has to hold the output of step two while reasoning about step five. Those are not long tasks or unfamiliar tasks. They are high-RC tasks. The model has to bind several interdependent things simultaneously, and that is the regime where frontier accuracy falls to a coin flip or worse.
When a task needs three or more interdependent variables held in mind at the same time, the failure is not a smarter-model problem. It is a binding problem, and more compute does not fix it.
This reframes the diagnostic. The next time an agent breaks on a task you expected it to handle, the useful question is not “is the model good enough yet.” It is “how many things does this step force the model to bind at once.” If the answer is four or more, you have your explanation, and the fix is architectural, decompose the binding into smaller steps with explicit intermediate state, rather than waiting for a better model.
What I’d hold back on
Two honest caveats, both the authors more or less own.
The tasks are stylized. Raven’s matrices and phylogenetic trees are clean lab instruments, and the jump from “RC in a synthetic tree” to “RC in your production workflow” is assumed, not proven. I would love to see RC mapped onto a naturalistic agent benchmark before treating the number as a planning constant.
And there is no human baseline. Every result frames frontier models as failing, but without a human RC-versus-accuracy curve we cannot tell whether people plateau at RC=5 or sail past it. That would settle whether this is “LLMs are uniquely bad at binding” or “binding is hard for everyone and LLMs are a bit worse.” Different stories, different implications.
The contribution here is not the scary 12%. It is the ruler.
For two years “complex reasoning” has been the phrase practitioners reach for when a model fails and they cannot say why. RC turns that shrug into a measurement.
The generative code is open on GitHub, so you can instantiate REL-style probes against your own agent tasks instead of guessing.
Watch for the human baseline and the naturalistic mapping. If those land, RC stops being a benchmark curiosity and becomes a number you check before you ship an agent into a high-binding workflow.
The models are not getting dumber. We are just learning to name the shape of where they break.
Around the Corner: short reviews of ideas worth watching. Opt-in section, not part of the weekly Run Data Run email. Subscribe to the main list for longer essays.