
The Data Paradox
What if the decade we spent cleaning data was the last decade it mattered?


I’m going to challenge something I’ve spent a career building. Data quality programs, FAIR frameworks, governance models, the entire machinery of making data clean and trustworthy before anyone touches it. I’ve led these efforts. I’ve championed them. I believe in them.
And I think we need to question all of it.
Not because it was wrong. But because everyone keeps saying AI is changing the world around us, and if our thinking doesn’t change with it, we risk being the ones who end up on the wrong side of this. The people who clung to assumptions that made perfect sense for a decade and then quietly stopped being true.
So here’s the honest version of a conversation happening in every large organization that has spent serious money on data quality:
“We spent ten years making our data FAIR. Findable, Accessible, Interoperable, Reusable. We built governance frameworks, hired data stewards, created ontologies, mapped lineage, enforced schemas. We did all of this so our data could be trusted, reused, and composed across contexts it was never originally designed for.”
“And now you’re telling me the AI just... figures it out?”
Yes. Sort of. And that “sort of” is where things get interesting.
Act I: The Decade of Clean
If you worked in life sciences, healthcare, or any data-heavy regulated industry between 2015 and 2025, you lived through the FAIR data era. The premise was sound: data created for one purpose (a clinical trial, a lab experiment, a patient registry) needed to be reusable for purposes nobody anticipated when it was first collected.
The problem was real. Clinical trial databases were built to answer regulatory questions, not research ones. Lab systems captured results in formats that made sense to the instrument vendor, not to the scientist three buildings over trying to correlate findings across studies. Patient data lived in silos that couldn’t talk to each other because nobody agreed on what “response” meant, let alone how to encode it.
So we standardized. CDISC for clinical data. OMOP for real-world evidence. FHIR for health records. We built data catalogues, metadata registries, master data management platforms. We hired armies of data engineers whose entire job was transformation: take messy source data, apply business rules, output clean, governed, trustworthy datasets.
This wasn’t wasted effort. I want to be clear about that. The FAIR movement produced genuine value. Organizations that invested in data quality can now run analyses in hours that used to take months. They can combine datasets across trials, across therapeutic areas, across geographies, in ways that would have been impossible with the raw source data.
But the FAIR era also produced something else: a deeply held assumption that clean data is a prerequisite for insight.
That assumption is now being tested.
Act II: The Machines Don’t Care
Here’s what changed. Large language models and multimodal foundation models can ingest data that would make a data steward weep. Inconsistent column names. Mixed units. Free-text fields full of abbreviations, typos, and shorthand that only made sense to the person who entered it. PDFs. Scanned images. Handwritten notes.
And they can still extract signal.
Not perfectly. Not reliably enough for regulatory submissions. But well enough to generate hypotheses, surface patterns, and accelerate the early stages of analysis that used to require weeks of data cleaning before anyone could even look at the data.
This is playing out across organizations. A team spends three months harmonizing adverse event data across four clinical trials. Different coding dictionaries, different severity scales, different reporting conventions. Classical data engineering. When they’re done, the analysis takes two days.
A separate team takes the same raw, unharmonized data, drops it into a frontier model with a well-crafted prompt, and gets directionally identical findings in an afternoon. Not publication-ready findings. Not regulatory-grade findings. But “should we look deeper at this signal” findings, which is what the first team was actually trying to answer.
Three months of data engineering versus one afternoon of prompting. For the same directional answer.
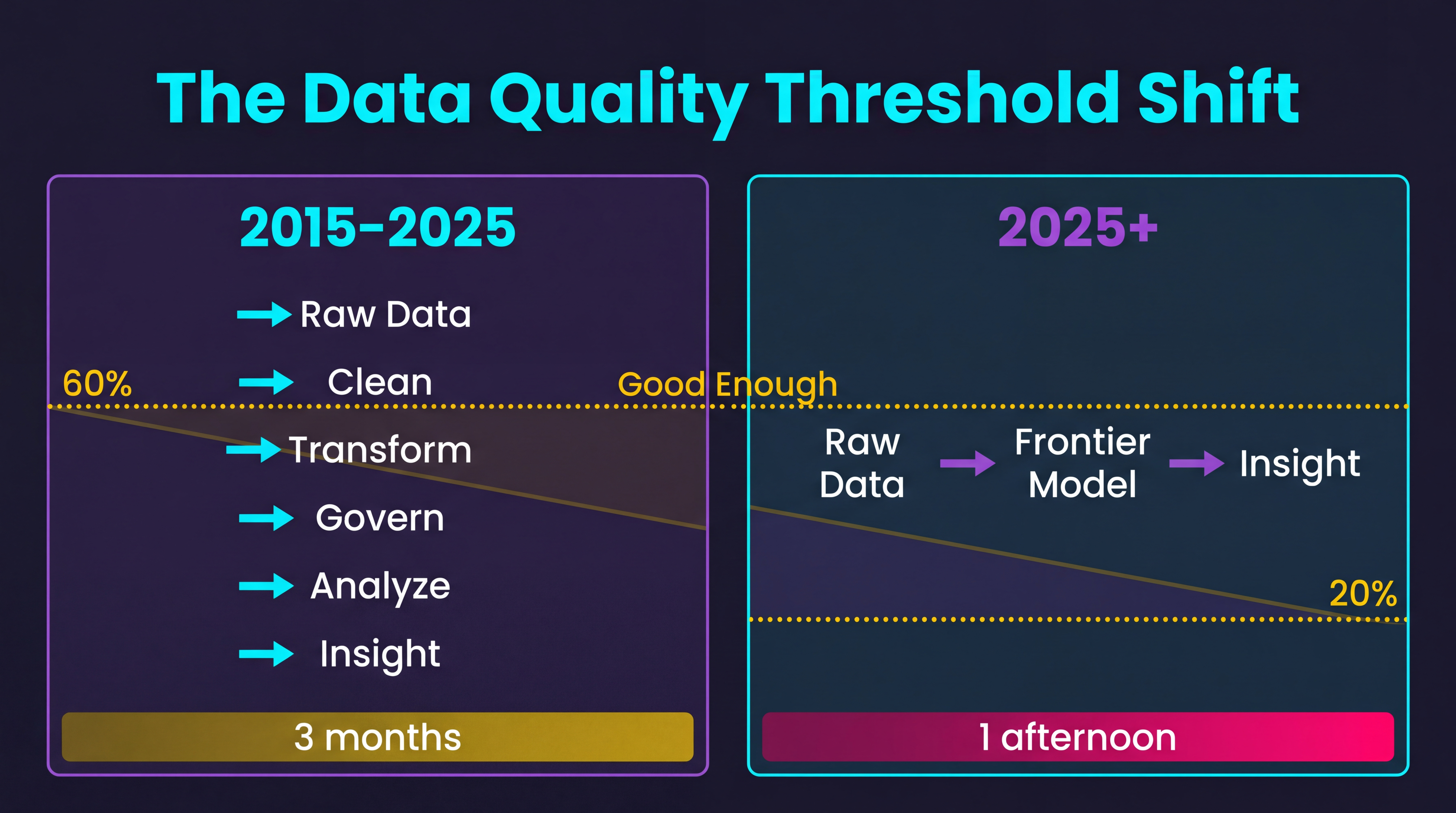
This doesn’t mean data quality is dead. It means the threshold for “good enough” has shifted. For exploratory analysis, hypothesis generation, literature synthesis, and early signal detection, the old standard of “clean it first, analyze it second” is being replaced by “analyze it now, clean what matters later.”
The implications for how organizations allocate data engineering resources are significant. If 60% of your data engineering effort goes into cleaning data for exploratory use cases, and AI can handle those use cases with raw data, you’ve just freed up a lot of expensive talent for the 40% of work where data quality genuinely matters: regulatory submissions, safety reporting, manufacturing quality control.
Act III: The Existential Question
But here’s where the conversation gets uncomfortable. Really uncomfortable.
Assume frontier models keep improving at roughly the current rate. By 2028, 2029, 2030, these models will have been trained on the vast majority of published biomedical literature, clinical trial results, real-world evidence, genomic databases, imaging archives, and structured datasets that have ever been made available.
They will have seen patterns across millions of patients, thousands of trials, hundreds of therapeutic areas. They will have internalized the statistical relationships between biomarkers and outcomes, between molecular structures and binding affinities, between patient demographics and treatment responses.
Now ask yourself: what does your proprietary data add?
Your Phase II trial with 200 patients in a specific tumor type. Your real-world evidence dataset covering 50,000 patients at your partner health system. Your internal biomarker panel that you spent three years validating.
Against a model that has absorbed the aggregate knowledge of every published trial, every public dataset, every textbook, every conference presentation, and every preprint ever posted to bioRxiv or medRxiv.
What does your small, proprietary dataset tell the model that it can’t already infer?
This is the data paradox. The more capable the models become, the less incremental value any single organization’s data provides. Not zero value. But diminishing value. And the rate at which that value diminishes is accelerating.
The Three Responses
Organizations tend to fall into one of three camps when they hit this realization.
Camp 1: “Our data is unique and irreplaceable.” This is the most common response, and it’s partially right. Proprietary longitudinal data on specific patient populations does contain signal that public models can’t replicate. But “unique” and “valuable” aren’t synonyms. Your data might be unique in the same way your company’s internal email archive is unique: technically one-of-a-kind, practically uninformative to anyone else.
Camp 2: “We need to move faster.” This camp reasons that if the window of data advantage is closing, the play is to extract value from proprietary data now, before the models catch up. Fine-tune on your data today. Build specialized models that encode your institutional knowledge. Create moats while moats are still possible. There’s merit here, but the timeline pressure is real. If a model trained in 2028 can infer what your fine-tuned model learned from proprietary data in 2026, your moat evaporated in 24 months.
Camp 3: “The data isn’t the asset anymore. The questions are.” This is where I land. If models can absorb most available knowledge, the competitive advantage shifts from having data to knowing what to ask. Understanding which hypotheses to test. Knowing which combination of signals to look for. Having the domain expertise to evaluate model outputs and know when they’re wrong.
The FAIR era was about making data machine-readable. The next era is about making questions machine-answerable.
That’s a fundamentally different skill set, and most organizations haven’t started building it.
What This Means in Practice
If you lead a data organization, here’s what I’d think about.
Stop treating data cleaning as the default first step. Ask whether the use case actually requires clean data or whether a frontier model can work with what you have. Reserve your data engineering capacity for the cases where quality is non-negotiable.
Invest in question formulation, not just data infrastructure. The bottleneck is shifting from “we can’t access the data” to “we don’t know what to ask.” Hire people who understand the domain deeply enough to ask questions that models can’t generate on their own.
Think about data as a validation asset, not a training asset. Your proprietary data may be less valuable for teaching models new things and more valuable for confirming or refuting what models already believe. That’s a different value proposition, and it requires different infrastructure.
Accept that data advantages are becoming time-limited. Whatever edge your data gives you today will be smaller in 18 months. Extract value now, but don’t build your entire strategy around a depreciating asset.
Build AI-native analysts, not just AI tools. This is the part most organizations are getting wrong. They’re buying platforms and building chatbots when the real shift is a domain expert with a frontier model as an exoskeleton. I’ve written about this framing before: AI isn’t your coworker, it’s your exoskeleton. It amplifies what you already know how to do.
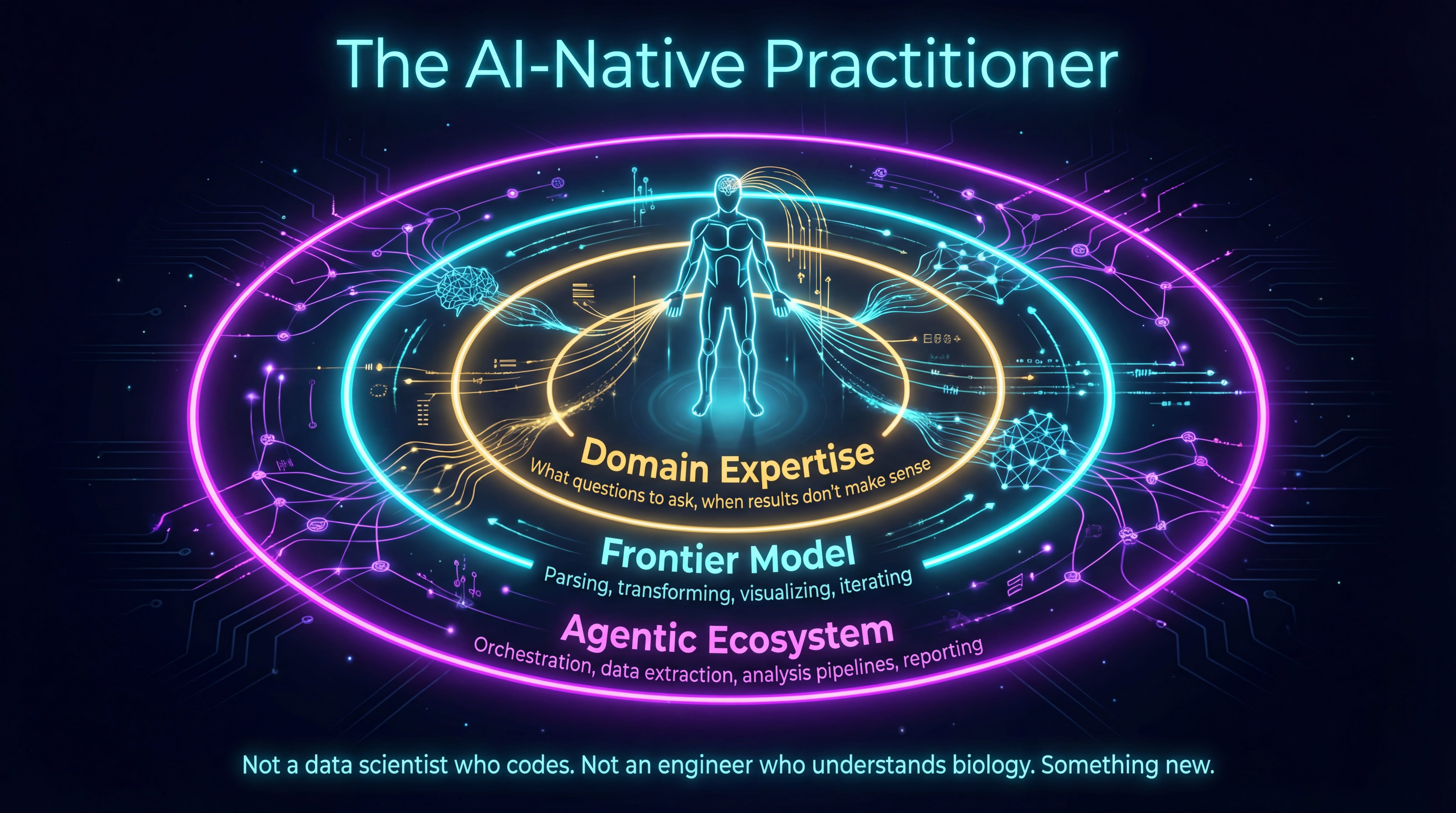
A clinical pharmacologist with an agentic coding environment pointed at raw trial data can do in hours what used to take a cross-functional team weeks. Not because the model replaces the pharmacologist’s judgment, but because it handles the mechanical work (parsing, transforming, visualizing, iterating) while the expert focuses on what they’re actually good at: knowing which questions matter, recognizing when results don’t make sense, and deciding what to do next.
Couple that domain expert with an agentic ecosystem, orchestration tools that let them string together data extraction, analysis, and reporting into flows they control, and you’ve got something genuinely new. Not a data scientist who codes. Not an engineer who understands biology. An AI-native practitioner who uses frontier models the way a previous generation used spreadsheets: as a thinking tool, not a product someone else built for them.
The investment case here isn’t “buy an AI platform.” It’s “upskill your domain experts to actually use frontier models in agentic workflows.” Teach your scientists to orchestrate. Give your clinical teams tools that let them go from raw data to insight without a three-month detour through data engineering. The organizations that do this will compress timelines from months to hours. The ones that don’t will keep filing tickets with the data team and waiting.
Rethink your data teams accordingly. The ratio of data engineers to data scientists to AI engineers needs to shift. Fewer people cleaning and transforming. More people formulating hypotheses and evaluating outputs. But the bigger shift is this: some of the most valuable “data people” in your organization won’t come from your data team at all. They’ll be the domain experts who learned to wield these tools themselves.
The Uncomfortable Truth
Here’s what I keep coming back to. We didn’t waste the last decade on FAIR data. Those investments were necessary, and they continue to matter for regulatory and operational use cases. But we did build an organizational muscle memory around a specific workflow: clean the data, then analyze it. And that workflow is becoming optional for a growing number of use cases.
The data paradox isn’t that clean data is worthless. It’s that the threshold for “clean enough” keeps dropping, while the unique value of any single dataset keeps shrinking against models that have seen everything.
The organizations that navigate this well will be the ones that can hold two ideas simultaneously: data quality still matters for some things, and data quality is becoming irrelevant for others. The ones that struggle will be the ones that can’t let go of a decade of institutional commitment to a paradigm that’s shifting under their feet.
The question isn’t whether your data is clean. The question is whether your data tells the model something it doesn’t already know. And that question gets harder to answer every six months.
I’ve been saying this for years and most FAIR enthusiasts believe I don’t care about data quality. Im all for enhancing the quality of datasets but “perfect cannot be the enemy of good”. Agree that the new battleground will be asking the right questions AND acting on those insights turning them into critical decisions faster than others. We live in a world where it’s unlikely to have perfect data to make key decisions in medicine. So, we should get comfortable using these new tools to accelerate insights at unimaginable speed from just a few years ago.
What questions (closely tied to what is your hypothesis) to ask has always been the most important factor. Given our data coverage and quality we ended up asking questions that we could answers. Now as you described things have changed and we can afford to ask the real hard questions.
But how do we validate the answer? I think the paradigm shift is working on generating (cleaning) data sets and experimental capabilities to quickly turn around the answer validation.
Good write up!