
The AND we have to hold
One week of AI-in-medicine headlines, two opposite directions, and three questions to keep asking in this week's Sunday Deep Dive

Every Sunday, I pick one (or more) papers or releases worth your time, break them down, and tell you why they matter. No hype. No summaries of summaries. Just the idea, explained.

This week, two stories about AI in medicine sat next to each other in my feed.
One was a paper in Science. Researchers ran OpenAI’s o1 against hundreds of physicians on a stack of validated clinical reasoning tests, then dropped the model into a prospective study of real emergency-room patients at a major academic medical center. On the ER cases at triage, the model placed the correct diagnosis at the top of its differential 67.1 percent of the time. The two attending physicians it was tested against landed at 55.3 percent and 50.0 percent. Raters identified AI versus human correctly between 3 and 15 percent of the time, which is to say the blinding worked. The paper’s own abstract closes with the line that “LLMs have eclipsed most benchmarks of clinical reasoning, motivating the urgent need for prospective trials.”
The other was a special report from Ontario’s Auditor General. Across twenty AI medical-scribe systems approved for use by roughly five thousand Ontario physicians, evaluators found that nine of twenty fabricated information that wasn’t in the recording, twelve of twenty captured a different drug than the doctor prescribed, and seventeen of twenty missed key details about patients’ mental health. The fabrications included notes stating “no masses found” and “presence of anxiety in the patient” when neither was discussed. The auditor issued ten recommendations. The program is still running.
Same field. Same week. Both verified. Both shipping in production right now.
The instinct to pick
You can feel the pull. Pick one story and the post writes itself. AI is ready, physicians should be paying attention. Or, AI is unsafe in clinical settings, we need to slow down. Each version has a constituency, a publication ladder, a Twitter audience already in formation. The opposite story is the noise around the signal you’ve decided to amplify.
The both-true version is harder to write and harder to read. The first comment under it is going to be “but which one is it, really.” The second is going to be “this is just hedging.” So you don’t write that version. You collapse to one. The field collapses to one. The discourse collapses to one. Every week we do this with a new story and a new opposite.
This isn’t a contrarian frame, by the way. It’s how the people doing the work talk about the work, when they’re not in a press cycle. Hold that thought for section seven.
The power
The Science paper, by Brodeur and colleagues, is among the most carefully designed evaluations of a medical LLM I have seen this year. The headline result has been around for two weeks. The methodology is what makes the result hard to dismiss.
Six experiments, plus the ER arm. The six were probes of different reasoning capacities, scored on validated qualitative scales developed for evaluating physicians, not on automated metrics. Diagnostic reasoning measured by R-IDEA, a ten-point scale used in medical education. Management reasoning scored on cases that were never publicly released, specifically to prevent training-data memorization. Probabilistic reasoning against a baseline of 553 practitioners. The model’s advantage was largest on the experiments where rubrics rewarded comprehensive coverage and smaller or absent where they measured focused clinical judgment.
The ER arm is the closest thing the field has produced to a prospective evaluation. Seventy-six randomly selected emergency-department patients at a tertiary academic center. The model and two attending physicians each generated a differential at three touchpoints in the patient’s evaluation: triage, after the initial physician encounter, and at admission. An independent rater, blinded to whether each note came from a human or the model, scored them on a scale validated for clinical reasoning quality. Mixed-effects regression to handle case-clustering. The 67-versus-55-percent gap at triage is the headline, but the whole apparatus around it is what makes the headline land where prior work didn’t.
The authors’ own framing in the closing paragraph is precise: the benchmarks have been eclipsed, and the next thing the field needs is prospective trials, not more benchmarks. It is a careful sentence in a careful paper. The press has been less careful.
The shadow on the power
Here is the part of the same paper that didn’t trend.
The ER study tested the same patients, the same model, and the same two physicians at three points in the workup. The only thing that changed across the three points was how much clinical information was available. At triage, the model led by 12 to 17 percentage points. By admission, the model’s accuracy was 81.6 percent. One of the two physicians had reached 78.9 percent. That difference was no longer statistically significant.
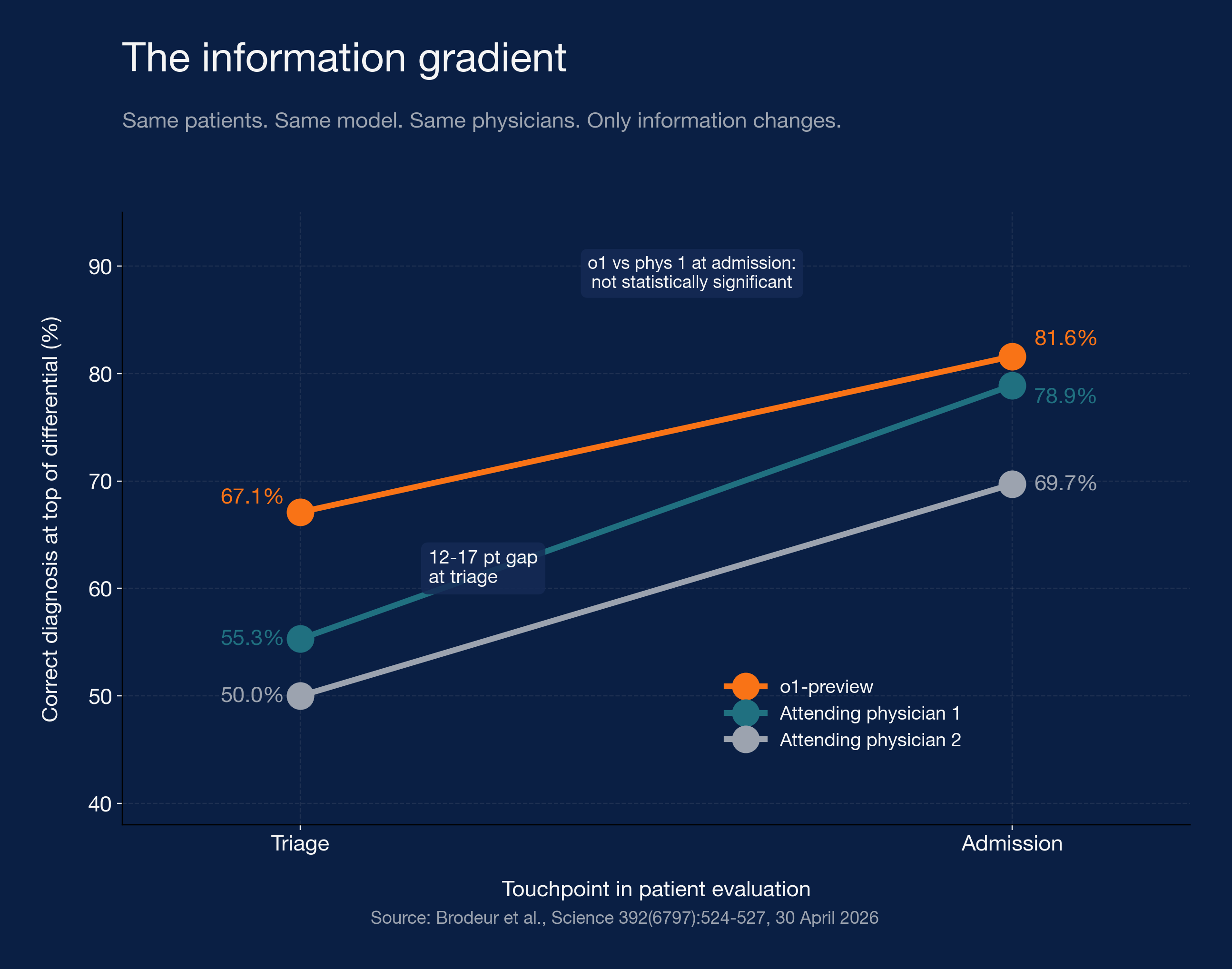
Same study. Same patients. The advantage concentrates where information is sparse and erodes as information accumulates. In real emergency-department practice, no clinical decision turns on the triage differential alone. The next steps, the orders and the exam and the response to therapy, are exactly the points where the model’s edge dissolved in the paper’s own data. The headline is true at one touchpoint and not at the others, and the touchpoint where it’s true is the touchpoint where the decision hasn’t been made yet.
A second piece of work points the same direction. Rao and colleagues, in JAMA Network Open last month, evaluated twenty-one large language models on twenty-nine clinical reasoning tasks. The best of the 21 models reached 91 percent accuracy on final diagnosis. All of them failed more than 80 percent of the time when asked to generate a differential. They collapsed prematurely onto a single answer, then defended it. “AI is good at clinical reasoning” is a claim that doesn’t survive the task being specified. The model is good at picking from a constrained menu of correct answers. It collapses on the open problem.
The argument against the dismissal of these results is the same as the argument against overclaiming them. Magnitude claims should match the strongest version of the evidence. The strongest version, on contemporaneous head-to-head data, holds up and is narrower than the press version.
The danger
Now the other story.
Ontario’s special report runs fifty pages on AI use in government. Section 4.3 is the part about medical scribes. The evaluator findings are concrete in a way the discourse rarely is. Nine of twenty systems hallucinated, which the report defines as fabricating clinical information including referrals and tests that hadn’t been ordered. Twelve of twenty captured the wrong drug. Seventeen of twenty missed details about patients’ mental health, in at least one of two simulated recordings. Six of twenty missed those details in both. The specific examples in the text include a system producing a note stating “no masses found” when the recording contained no such discussion, and another asserting that a patient had anxiety when no such symptom was mentioned.
The technology failed. That is half the story.
The other half is in the procurement document. Supply Ontario’s vendor scoring assigned weightings across ten criteria, out of 530 total possible points. Domestic presence in Ontario was weighted at 30 percent. Data privacy and legal controls were at 23 percent. System security controls totaled 11 percent. Accuracy of medical notes generated, the criterion that addresses what those nine systems were doing wrong, was weighted at 4 percent. Bias controls were at 2 percent. There were no minimum passing scores on any criterion in the second stage. A vendor could score zero on accuracy, zero on security, and zero on bias and still meet the aggregate threshold to become an approved Vendor of Record.
The UK’s NHS, by comparison, requires AI scribes to be assessed for safety and compliance as Class I medical devices through the Medicines and Healthcare products Regulatory Agency. Ontario has no equivalent gate. OntarioMD did issue guidelines for manual review of system-generated notes, but doctors weren’t required to attest that they had reviewed them. The guideline was a guideline.
When a procurement process weights accuracy at 4 percent and security at 11 percent and bias at 2 percent, the result is not a surprise. It’s the system asking for what it got.
The technology made fabrications. The procurement let the fabrications through.
The report contains one precedent worth naming. In December 2024, before the Vendor of Record arrangement existed, an Ontario hospital reported a privacy breach to the Information and Privacy Commissioner. A former staff member had used an unapproved AI transcription tool that recorded a meeting and then automatically distributed the transcribed notes to current and former staff. The tool was not malicious. It was doing what it was built to do. Nobody had asked whether the building was the right thing to be doing.
The shadow on the danger
A study published earlier this year in JAMA Network Open, led by Kristine Olson at Yale and run across six US health systems, followed 263 ambulatory clinicians for 30 days while they used an ambient AI scribe. The product was Abridge, the same kind of tool that lives on the approved-vendor list in Ontario. Burnout in the cohort dropped from 51.9 percent to 38.8 percent, an adjusted odds ratio of 0.26, with a 95 percent confidence interval running from 0.13 to 0.54. Severe burnout dropped from 18.4 percent to 12.2 percent. The authors named their own limitations, all of them real, none of them enough to wave away an effect size of that magnitude.
The numbers are not a contradiction of the Ontario report. They are a different deployment context. Kaiser Permanente reports analogous figures across roughly ten thousand of its physicians using the same vendor, with documentation-related burnout dropping by close to 80 percent and note quality scored at 4.35 out of 5 by the clinicians themselves. The numbers will get audited, refined, and possibly trimmed. They will not get to zero.
The same three-word phrase, “AI medical scribe,” covers the nine-of-twenty-hallucinated systems audited by Ontario and the one-product, six-health-system study that halved burnout. The variance across deployments is itself the finding. What the technology does depends on which technology, which procurement process approved it, which workflow it landed in, which clinician is using it, and which oversight is wrapped around it. None of those variables are properties of “AI.”
A vocabulary clinicians use for what the tool returns is “pajama time.” It is the documentation they do at home after the kids are asleep. A scribe that works, in the deployment context it was built for, returns pajama time. A scribe that fails, in a deployment context that asked the wrong questions of the vendor, returns notes with fabricated medications. Both kinds ship. Both sit under the same three-word label.
The anatomy of holding the AND
AI in medicine is incredibly useful. AI in medicine is incredibly dangerous. Not a contradiction the field will resolve into one answer. Both arrive together every week, in different ratios. The instinct is to collapse to one. The discipline is not collapsing.
This isn’t a stance I’m asking you to adopt. It is how the people doing the work talk about the work. Adam Rodman is a senior author on the Science paper that ran the ER study. He is at the same hospital where the ER arm was conducted. He is also the person quoted in IEEE Spectrum, after the paper landed, saying he gets “a little queasy about how some of these results might be used,” and that the models are equally convincing whether they are right or wrong. One person. Both camps. On the record.
What that person is doing, when he holds both at once, is asking three questions. The questions don’t bend to which way the story is going. The answers shift. The asking is the muscle.
What question survives the headline? Whether the news is “AI beats doctors” or “AI invents medications,” the same things stay on the table. Where is this system most likely to be wrong, and how would I know. Ask it of o1, and the paper’s own data answers: where information is full and the decision is actually being made. Ask it of Ontario, and the audit answers: in production, on real conversations, with no required clinician attestation that the note was ever reviewed.
Who’s on the hook when it’s wrong? The accountability geometry is different for the two stories, which is part of the lesson. For o1, the authors are accountable for the methodology, the model maker is accountable for the system, and no clinician is yet accountable because the system isn’t deployed. For Ontario, the vendors are accountable but lightly. The procurement agency is accountable but the criteria were public. The Ministry of Health is accountable but the program is optional. The regulator is accountable, except Ontario has no analog to the UK’s MHRA. The geometry collapses. That collapse is itself a finding.
What moves if the answer flips? Force yourself to price the stakes before you take a side. If the information-gradient holds and o1’s edge stays non-significant at admission, “deploy o1 as a triage tool” becomes a different proposition from “deploy o1 anywhere.” If Ontario reweighted accuracy from 4 percent to 30 percent and required passing thresholds, nine of the twenty approved vendors might not have been approved. The question forces you to notice you’ve been taking a side without naming what the side costs.

The sharper version of the AND, raised by Eric Topol and others recently, is that the benchmark wins are demonstrated and the patient outcome wins are scarce. Most of what we call “useful” is workflow-level, not outcome-level. Burnout reduction is a workflow outcome. Time-with-patient is a workflow outcome. Mortality, readmission, diagnostic accuracy in real care over time, the things patients care about, are mostly absent from the evidence base. That gap is the AND with the sharpest edge.
The questions don’t change. The answers do. The asking is the muscle.
Close
Next week there will be two more headlines. Utah’s medical licensing board recommended last month that the state suspend an autonomous AI prescription pilot. Pennsylvania’s state board sued a chatbot company for unlicensed practice. The FDA issued its first warning letter to a drug manufacturer for using AI agents to generate manufacturing records without quality-unit review. A researcher fabricated an eye condition called Bixonimania, including citations to Starfleet Academy, and watched four commercial chatbots cite it as a real disease, after which a peer-reviewed journal published a paper about it before retracting. All of this is from the last two months. None of it will be the story the next Science paper or auditor report displaces.
The work doesn’t end with one answer. The work is keeping three questions sharp.
What question survives the headline.
Who’s on the hook when it’s wrong.
What moves if the answer flips.