
The $2B Bet on the 90/90 Rule - Thinking Machines and Tinker
Why Fine-Tuning Infrastructure Matters More Than You Think

Generic foundation models are impressive, but frustratingly generic. GPT-5 can write elegant prose about protein folding, but it doesn’t know your lab’s experimental protocols. Claude explains CRISPR mechanisms beautifully, but can’t interpret your clinical trial data the way your researchers do. Llama knows chemistry textbook facts, but doesn’t understand your proprietary compound library or safety assessment frameworks.

This gap between general intelligence and specific utility is where billions of R&D dollars get stuck.
Your computational biologists spend more time correcting AI outputs than writing analyses from scratch. Your clinical documentation AI almost captures the right diagnosis codes, but the 15% error rate makes it unusable. Your drug discovery models generate candidates that violate constraints obvious to your medicinal chemists but invisible to the AI.
Three approaches have emerged for customizing AI: prompt engineering (quick but limited), RAG (good for facts, can’t change reasoning), and fine-tuning (rewires behavior to think like your scientists).
The market signal that matters: Thinking Machines Lab raised $2 billion at a $12 billion valuation before shipping a product, then launched Tinker on October 1, 2025. That’s venture capital betting model customization infrastructure becomes as fundamental as databases are to web applications.
What Tinker Actually Does
The pitch: Write Python code on your laptop, send it to Tinker’s API, run it on distributed GPU clusters, download your custom model.
Most managed services force an uncomfortable choice. “Upload your data and we’ll train your model” platforms give you convenience but sacrifice control. DIY GPU clusters give you control but require a dedicated ML ops team.
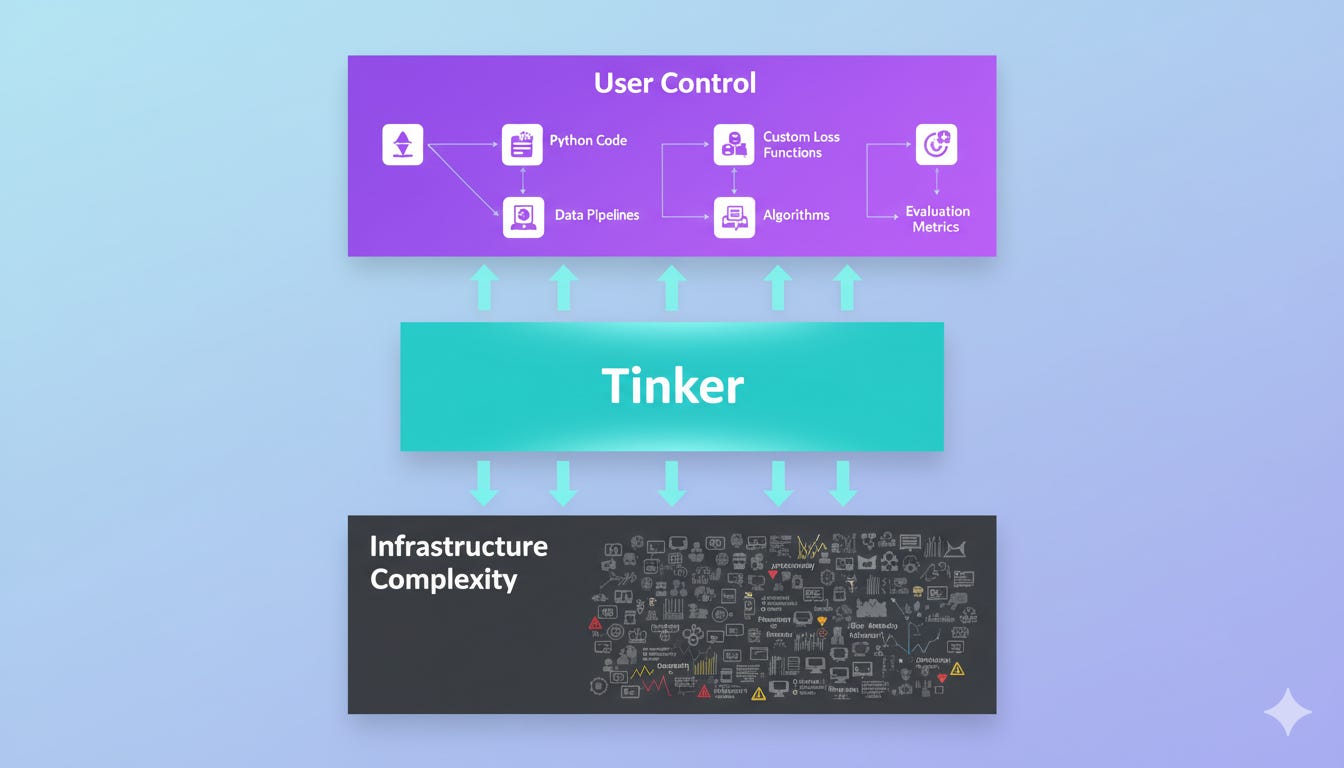
Andrej Karpathy described Tinker’s positioning as finding “a more clever place to slice up the complexity of post-training,” providing roughly 90% of algorithmic control while removing roughly 90% of infrastructure pain.
Tyler Griggs from Berkeley’s SkyRL group: “Tinker lets us focus on the research, rather than spending time on engineering overhead. That’s something no amount of raw GPU credits can substitute.”
How It Works
You write training loops as if running locally, with full control over:
Loss functions
Data processing
Evaluation metrics
Novel algorithm implementation
Tinker handles automatically:
GPU orchestration and scheduling
Distributed training coordination
Failure recovery and checkpointing
Resource allocation
Think of it like AWS for model training. You write code that runs locally, AWS makes it scale. Tinker applies the same principle: you write training logic locally, Tinker runs it on massive GPU clusters.
Who Built This
The team matters enormously in infrastructure.
Mira Murati (CEO): Former OpenAI CTO who led ChatGPT, DALL-E 2/3, and Codex development.
John Schulman (Chief Scientist): OpenAI co-founder who invented PPO and TRPO, foundational algorithms for reinforcement learning.
This isn’t a startup figuring things out. It’s the team that built the original systems now building infrastructure for others to customize them. Backed by Andreessen Horowitz (lead), NVIDIA, AMD, and Accel. Seven months from founding to first product.
The Problem with Generic Models for Science
The “almost but not quite” problem hits hardest in scientific contexts:
Your protein structure prediction almost identifies binding sites correctly, but 8% error rate means manual validation of everything
Your clinical notes summarization almost captures diagnostic reasoning, but misses subtle decision points that matter for complex cases
Your materials science literature mining almost extracts synthesis conditions, but confuses your notation with standard nomenclature
These aren’t cosmetic failures. When your CRISPR design AI suggests guide RNAs that violate your lab’s efficiency criteria learned from thousands of experiments, you’ve wasted a week of experimental time.
The Infrastructure Barrier
A computational biology lab at a top university might have brilliant researchers and proprietary data, but not $3,200/month per model for GPU costs, and certainly not headcount for distributed training infrastructure.
Industry research groups fare better on budget but worse on bandwidth. Your medicinal chemists should design molecules, not debug CUDA out-of-memory errors.
The Control Problem
Black-box services work if your task matches their assumptions. But what if:
You need multi-modal data (imaging + genomics + clinical history)?
Your loss function accounts for false negatives costing 10x more than false positives?
You want to implement a novel training approach from a recent paper?
The strategic framing: Fine-tuning converts institutional knowledge into a competitive moat. Your proprietary data, validated protocols, and domain expertise refined over years—fine-tuning encodes all of that into a model that reasons like your organization reasons.
What Fine-Tuning Actually Delivers
The ROI numbers from enterprise deployments tell a clear story:
Telecommunications: 68% reduction in escalations (models understand specific service tiers and troubleshooting procedures)
Manufacturing: Quality control accuracy 54% → 78%, generating $2.3M in annual savings (models trained on specific defect patterns, not generic standards)
Financial Services: Contract review time 45 minutes → 3 minutes (models fine-tuned on institution’s contract library and risk frameworks)
Cross-industry: Organizations implementing fine-tuning well see roughly $3.70 return per dollar invested, with 13-month average payback periods.
Healthcare: Clinical Documentation
Let’s make this concrete. Clinical documentation consumes ~50% of physician time, pulling doctors from patients and driving burnout. Generic models can generate notes but don’t understand institution-specific protocols, abbreviations, workflows, or compliance standards.
A major health system deployed a fine-tuned model trained on their historical patterns, institutional terminology, local workflow requirements, and compliance standards.
Results:
Documentation time ↓ 70%
Less burnout, more patient time
Coding accuracy improved (better reimbursement)
Compliance violations decreased
The difference: Generic models know medical facts from textbooks. Fine-tuned models know how your institution practices medicine. When Dr. Smith writes “pt c/o CP,” the model knows she means chest pain with a specific differential based on patient history. It generates notes that pass your coding auditors because it learned from thousands of examples that passed review.
Academic Research Wins
Princeton’s Goedel team: Mathematical theorem proving with 80% less training data than full-parameter approaches
Stanford’s chemistry group: IUPAC-to-formula conversion accuracy 15% → 50% on domain-specific reasoning
Berkeley’s SkyRL: Custom multi-agent RL scenarios impossible with black-box services
The pattern: Clear problem + proprietary data + consistent generic model failures + evaluation frameworks = measurable returns.
Where Tinker Fits in the Market

Tinker occupies the “high control, low complexity” quadrant—a rare combination.
When Fine-Tuning Isn’t the Answer
RAG (Retrieval-Augmented Generation) works extremely well for dynamic knowledge. If you’re building a scientific literature assistant needing yesterday’s papers, RAG updates instantly without retraining. Great for “know our facts,” can’t change reasoning patterns.
Prompt engineering suffices for style adjustments and formatting. Zero infrastructure, instant iteration. But effectiveness plateaus quickly and can’t inject domain expertise.
Hybrid approach (40% of enterprise AI applications): Fine-tune for reasoning patterns + RAG for updating facts + prompts for task-specific tweaks. Example: Legal analyzer fine-tuned on firm’s reasoning style, RAG for case law updates, prompts for client instructions.
Decision framework:
Need facts? → RAG
Need behavioral change? → Fine-tuning
Need simple adjustments? → Prompts
Need sophisticated apps? → Hybrid
Important limitations to acknowledge:
Small datasets create overfitting risks
Aggressive niche training causes catastrophic forgetting (models lose general knowledge)
Fine-tuning can compromise safety alignment (GPT-3.5 jailbroken with 10 examples for $0.20)
Not for knowledge injection—RAG handles that better
The Innovation: Finding the Right Abstraction
Tinker’s real innovation isn’t LoRA (that existed before). It’s recognizing where to draw the abstraction boundary.
Cloud computing succeeded by abstracting infrastructure while preserving developer control. AWS didn’t say “describe your app, we’ll build it.” AWS said “write code like it’s local, we’ll make it scale.”
What Tinker Abstracts Away
GPU orchestration
Distributed training coordination
Failure recovery
Resource allocation
What Tinker Preserves
Loss function control
Data processing pipelines
Algorithm implementation
Evaluation metrics
John Schulman framed it philosophically, quoting Alfred North Whitehead: “Civilization advances by extending the number of important operations which we can perform without thinking of them.”
Making infrastructure automatic isn’t laziness. It’s how innovation accelerates.
The Open Science Strategy
Most competitors treat fine-tuning recipes as proprietary secrets. Tinker publishes everything in an open-source cookbook on GitHub: battle-tested implementations, working hyperparameters, evaluation frameworks, integration patterns.
This isn’t altruism, it’s strategic:
Community trust: Transparency builds credibility (especially vs. OpenAI’s increasing closedness)
Talent attraction: Researchers want to work where knowledge is shared
Ecosystem building: Public recipes lower adoption barriers
Competitive moat: Community engagement creates defensible advantages
Murati left increasingly closed OpenAI to build something aligned with open-science values. In infrastructure, openness wins through community and ecosystem.
What This Means Going Forward
The Infrastructure Bet
VCs invested $2B before seeing product because fine-tuning infrastructure becomes a critical layer, comparable to databases for web applications. Not temporary, permanent requirement because specialization creates competitive advantage.
Trajectory:
2025-2026: Experimentation phase (test use cases, measure ROI)
2026-2028: Institutionalization (build internal capabilities)
2028+: Competitive requirement (not having custom models = disadvantage)
Compound Systems and Agentic AI
AI applications are evolving from monolithic models to compound systems combining multiple techniques. Organizations need platforms supporting hybrid approaches.
The agentic AI connection: As AI agents execute tasks autonomously, fine-tuning provides behavioral customization for reliability. A procurement AI agent needs to understand your approval hierarchies, your vendor relationships, your budget constraints, not generic best practices.
Organizations are also developing private evaluation frameworks encoding quality standards specific to their domains. Your evaluation framework itself becomes institutional knowledge competitors lack.
The Democratization Reality
Be honest: Tinker lowers barriers but doesn’t eliminate them. Still requires Python expertise and ML understanding. True democratization would need no-code interfaces (sacrificing the control that makes Tinker valuable).
Current reality: Democratizing access for technical teams at resource-constrained organizations, not enabling non-technical users.
Organizations still need ML talent. Budget for talent and infrastructure, not infrastructure instead of talent.
The Strategic Takeaway
Tinker represents a bet on the right balance point: neither black-box convenience nor DIY complexity, but controlled flexibility with managed infrastructure.
For Leaders in Scientific Organizations
Ask four questions:
Do we have specific problems where generic models consistently fall short?
Do we have proprietary data encoding institutional knowledge?
Do we have (or can we acquire) ML talent to leverage fine-tuning?
Are we prepared to invest in evaluation frameworks and safety monitoring?
If yes to all four: Fine-tuning infrastructure becomes strategic investment.
If no to any: Consider simpler alternatives (RAG, prompts) first.
The strategic position: Not “should we explore fine-tuning” but “how quickly can we build institutional fine-tuning capabilities before competitors do.”
Organizations moving first accumulate knowledge about what works in their domains. That knowledge compounds and becomes increasingly difficult to catch up with.
The Bigger Picture
Tinker’s real innovation isn’t the underlying technology and LoRA existed before. The innovation is recognizing where to draw the abstraction boundary. That insight, the 90/90 rule of maintaining control while removing complexity, may prove more valuable than the product itself.
The question isn’t whether this specific company wins. The question is whether they’ve identified the right way to make fine-tuning accessible to organizations with valuable data and real problems but limited patience for infrastructure complexity.
That bet, backed by $2 billion before proving product-market fit, suggests sophisticated investors believe the answer is yes.