
Sunday Deep Dive: Reckoning Is Not Judgment

Every Sunday I pick one paper or release that’s worth your time, break it apart, and tell you why it matters. No hype. No summaries of summaries. Just the idea, explained.
The Headline
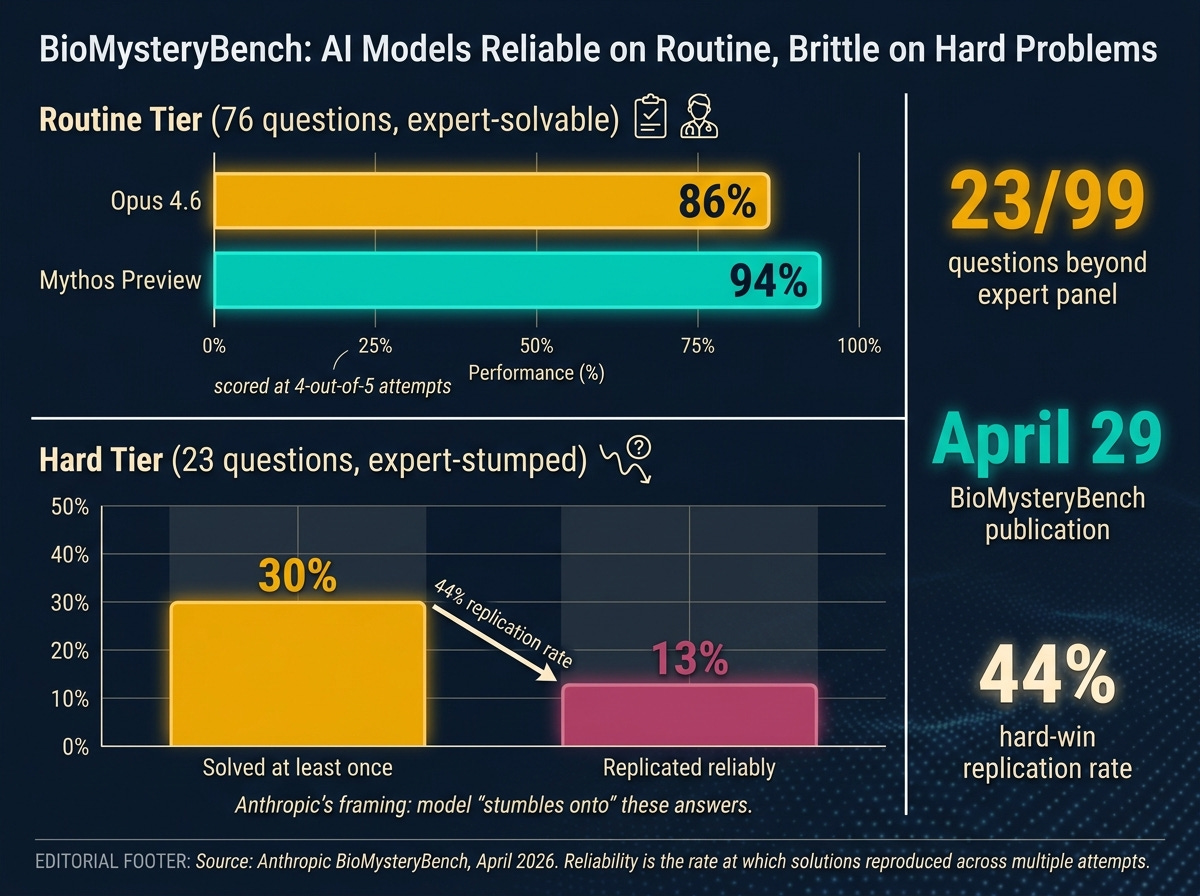
On April 29, Anthropic published BioMysteryBench, a 99-question bioinformatics evaluation built with domain experts. Claude Opus 4.6 matched expert baselines on the routine work. Their unreleased “super model,” which Anthropic refers to as Mythos Preview, occasionally solved problems an expert panel could not. Three weeks earlier, on April 9, Surag Nair and the Genentech computational biology team had published a parallel benchmark, CompBioBench, with the same instinct.
This is the first benchmark cluster I’ve seen that grades bioinformatics the way bioinformatics is actually done. The methodology is the story. The numbers are interesting. The honest reading of what the numbers mean is more interesting still.

The Problem Bioinformatics Poses to Benchmarks
Bioinformatics is a brutal benchmark target.
Most AI evaluations want a single right answer with a clean grading rubric. Bioinformatics workflows almost never look like that. A scRNA-seq analysis can run through Seurat, Scanpy, or a custom pipeline and produce three slightly different cluster assignments, all of them defensible. A variant-calling pipeline can use BWA-MEM, Bowtie2, or minimap2, with GATK, DeepVariant, or Strelka2 downstream. The right answer is not “the cluster” or “the variant.” It’s the experimental finding the data points to.
Bioinformatics work is method-plural and answer-singular. Most benchmarks invert that and reward method conformity instead of biological truth.
Existing science benchmarks dodge this by asking textbook questions. GPQA tests graduate-level multiple choice. HumanEval-bio tests function completion. Both measure recall. Neither measures the messy thing a working bioinformatician actually does on Tuesday morning, which is take a CSV nobody documented, a PI who wants an answer by Friday, and a public dataset that may or may not be the one cited in the methods section.
That’s the gap BMB and CompBioBench are trying to close. It’s a hard problem and they are genuinely trying to move the field.
What BioMysteryBench Did Right
Three design choices set BMB apart from the GPQA-style benchmarks AI labs usually run.
Method-agnostic evaluation. The model gets unrestricted tool access. It can hit NCBI, Ensembl, GEO, download whatever it needs. Anthropic does not score the path the model took. They score whether the answer it landed on matches the ground truth. That single decision carries the rest. You cannot grade a bioinformatician on which aligner they chose, only on whether the answer came out right.
Experimental ground truth, not researcher claims. This is the move that matters most. The right answer for each question is anchored to a verifiable experimental finding, not the conclusion the original paper drew. If a paper claimed gene X drove phenotype Y, but the underlying knockout data showed gene Z, the ground truth is Z. That sidesteps the worst failure mode of literature-based benchmarks, which is grading the model on whether it can recover the human’s interpretation rather than the biology.
Superhuman question generation. Twenty-three of the 99 questions were intentionally beyond the human expert panel. Most benchmarks cap at human ceiling because that’s where the labelers stop. BMB broke that ceiling by using validation notebooks that confirm a signal is in the data without requiring a human to solve the problem first.
The benchmark spans WGS, scRNA-seq, ChIP-seq, metagenomics, proteomics, and metabolomics. Real assays, real noise, real ambiguity. Genentech’s CompBioBench, which actually shipped first on April 9, runs a parallel methodology over a different 100-task spread and arrives at directionally similar numbers. Anthropic explicitly acknowledged it in the BMB write-up. Two industry teams, working in parallel, converged on the same shape of benchmark in the same window. That convergence matters more than either result on its own. The field is doing the work to keep itself honest.
New Doesn’t Mean Better
Here is the line that should give any AI-for-science leader pause.
On April 28, Surag Nair posted an update on CompBioBench that most people scrolled past. Anthropic’s newer Opus 4.7 slightly underperforms Opus 4.6 on CompBioBench. Not a dramatic regression, but a real one, on a domain-specific eval that didn’t exist a month earlier.
This is exactly why benchmarks matter, and exactly why we need more of them. A model card tells you the trajectory is up and to the right on the aggregate evals. A domain-specific benchmark tells you that on this particular slice of biology, the newer model is slightly worse. Both can be true, because frontier models are trained on overlapping but distinct objectives, and per-domain capability moves unevenly across releases.
New doesn’t mean better. If you are running a computational biology team and you upgrade the API call in your pipeline the day a new model ships, you may be regressing on the work that matters most to you and you would not know it without a benchmark like this one.
This is not a knock on Anthropic. They published the data that lets you see the regression. It’s a knock on the assumption that bigger numbers in the model card translate to better answers in your domain. The cure is exactly what BMB and CompBioBench are doing: domain-specific evaluation that moves at the speed of model releases.
The Numbers
Three numbers carry the rest of the story. They are worth pausing on individually because they measure different things.
86% is Opus 4.6’s accuracy on the 76 human-solvable questions, scored at four out of five attempts. That tier is decision-grade. Cell-type identification, gene-knockout detection, pathway inference on standard data. A generally available frontier model handles it with the consistency of a competent postdoc.
94% is Mythos Preview’s reliability on the same routine tier. The next-generation model improves on the routine work, which is what you would expect.
30% is Mythos Preview’s accuracy on the 23 problems the expert panel could not solve. That number is the one that ran on AI Twitter, and it is interesting. The first time I have seen a credible claim that a frontier model solved real scientific problems beyond what a panel of working scientists could solve.
The number Anthropic put quietly in the consistency section is the one that changes the deployment calculus.
44%, the rate at which Mythos Preview’s wins on the human-difficult tier replicated across multiple attempts.
When the model solved a hard problem, it reproduced that solve less than half the time. The wins count. They are also brittle. Roughly six out of ten times the model arrived at the right answer once and could not reliably get there again. Anthropic’s own framing for this is that the model “stumbles onto” these answers. That is a careful word. It admits the model is occasionally getting the right answer for reasons even Anthropic cannot fully reconstruct.
Brittle wins are not the same as no wins. They are also not capability you can deploy in the path of a research decision.
Routine bioinformatics tasks are decision-grade. Hard problems are tantalizing and brittle. The replication rate is the deployment-relevant number.
Reckoning Is Not Judgment
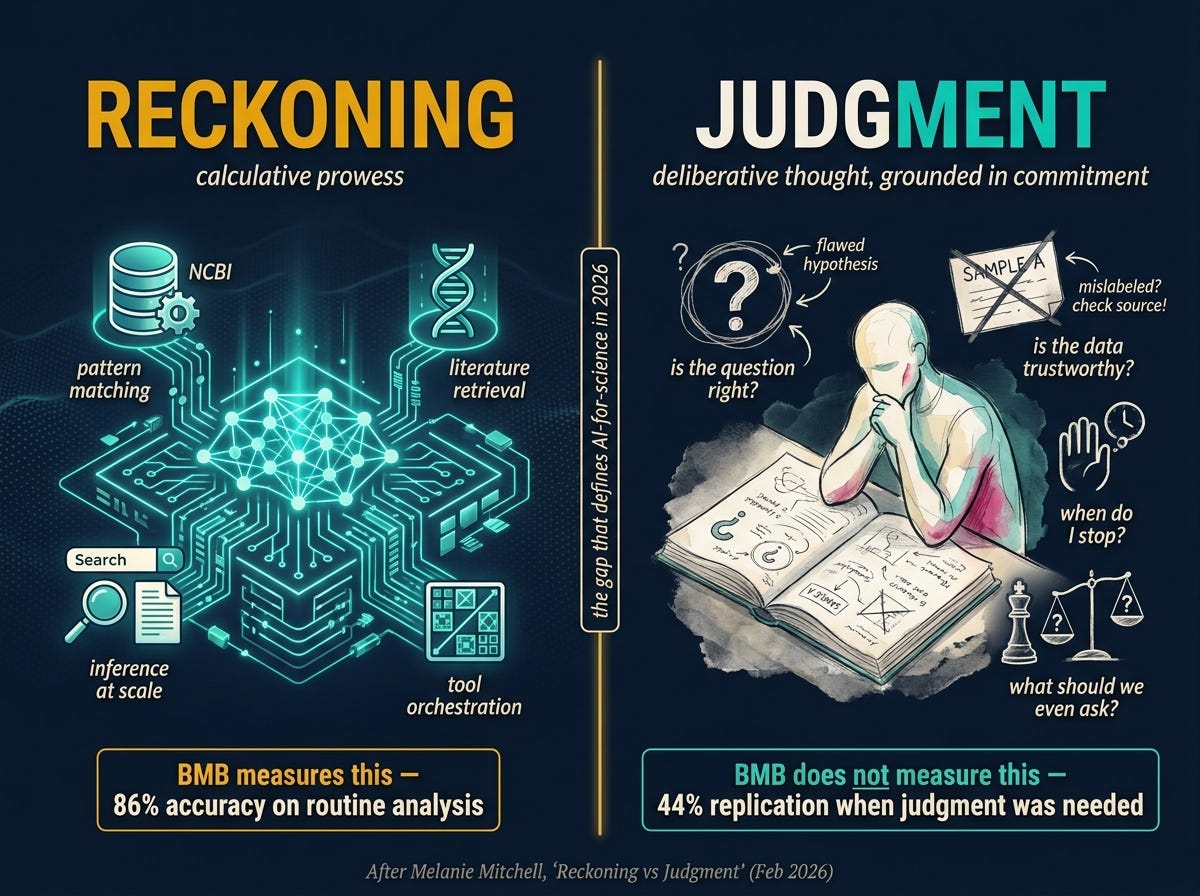
Melanie Mitchell wrote the cleanest philosophical anchor for what BMB is and isn’t measuring. In a February essay she drew a distinction between reckoning and judgment.
Reckoning is calculative prowess. Judgment is a form of dispassionate deliberative thought, grounded in ethical commitment and responsible action.
Reckoning is the thing AI systems excel at. Pattern matching, retrieval, inference over large corpora. Judgment is knowing which question to ask. Knowing which answer to trust. Knowing when to stop.
BMB is a reckoning benchmark. It measures whether a model can take a CSV, hit the right databases, run the right inference, and land on the experimental finding the data supports. That’s calculative retrieval at scale, and frontier models are now genuinely good at it. The 86% number says so.
What BMB does not measure is judgment. It does not test whether the model recognizes the question is malformed. It does not test whether the model knows the public dataset has six samples mislabeled, which it does, because everyone who works with public datasets knows that one. It does not test whether the model understands why the experiment was designed this way and whether the original design can answer the question being asked.
The bimodality in the BMB numbers maps onto Mitchell’s distinction almost perfectly. The 86% tier is reckoning. The 44% replication on hard problems is what happens when reckoning runs out and judgment is what’s needed. The model occasionally lucks into a judgment-shaped answer through reckoning machinery, and roughly six times out of ten it cannot find that answer again because the machinery never had judgment in it to begin with.
This is the frame that will outlive the benchmark. Whatever the next model scores on the next eval, the question is the same. How much of this is reckoning, and how much is judgment, and which one does the work actually require?
After Melanie Mitchell, Feb 2026. Bioinformatics work happens on both sides of the line. Benchmarks only grade the left.
This is where the free preview ends. Below the fold: what changes in your lab next week, what to watch over the next 90 days, and the bigger pattern this release fits into.
