
OpenAI Unveils o3 and o4-mini
A New Chapter in AI Reasoning

Yesterday marked another significant moment in AI's rapid evolution as OpenAI released two new models that genuinely captured my attention: o3 and o4-mini. As someone who's spent years working with AI tools, I found myself both excited and reflective about what these advancements might mean for developers like us.
What OpenAI Actually Released
OpenAI's announcement introduced two distinct models with different strengths and use cases:
o3 appears to be their most advanced reasoning model to date, designed to tackle complex, multi-step problems. It works across text and images while integrating tools like web search, Python, and image generation. It's available now to ChatGPT Plus, Pro, and Team users, with an o3-pro variant promised in the coming weeks.
o4-mini is positioned as a smaller, faster, and more cost-effective alternative that still excels at math, coding, and visual analysis. It offers an interesting balance of capability and efficiency for those who might not need the full power of o3.
Perhaps most interesting to me as a developer was the release of Codex CLI, a lightweight open-source coding agent that works alongside these new models and runs locally in your terminal. This feels like a significant step toward making AI a more integrated part of our development workflows.
The Technical Reality Behind the Hype
Looking past the marketing language, these releases represent OpenAI's response to increasing competition in the AI space. They appear to be building on their o1 series (from December 2024) and GPT-4.1 (just released on April 14), refining their approach to reasoning and multimodal capabilities.
What struck me most was how these models were evaluated under OpenAI's revised preparedness framework, featuring a new safety system specifically designed to block prompts related to biological and chemical risks. This suggests OpenAI is at least attempting to balance capability with responsibility - though how effectively remains to be seen.
Model Comparison: Understanding Where o3 and o4-mini Fit
Before diving deeper into public reaction, I think it's helpful to understand how these new models compare to their predecessors and competitors. My experience has taught me that token economics can significantly impact how you integrate these models into your workflow:
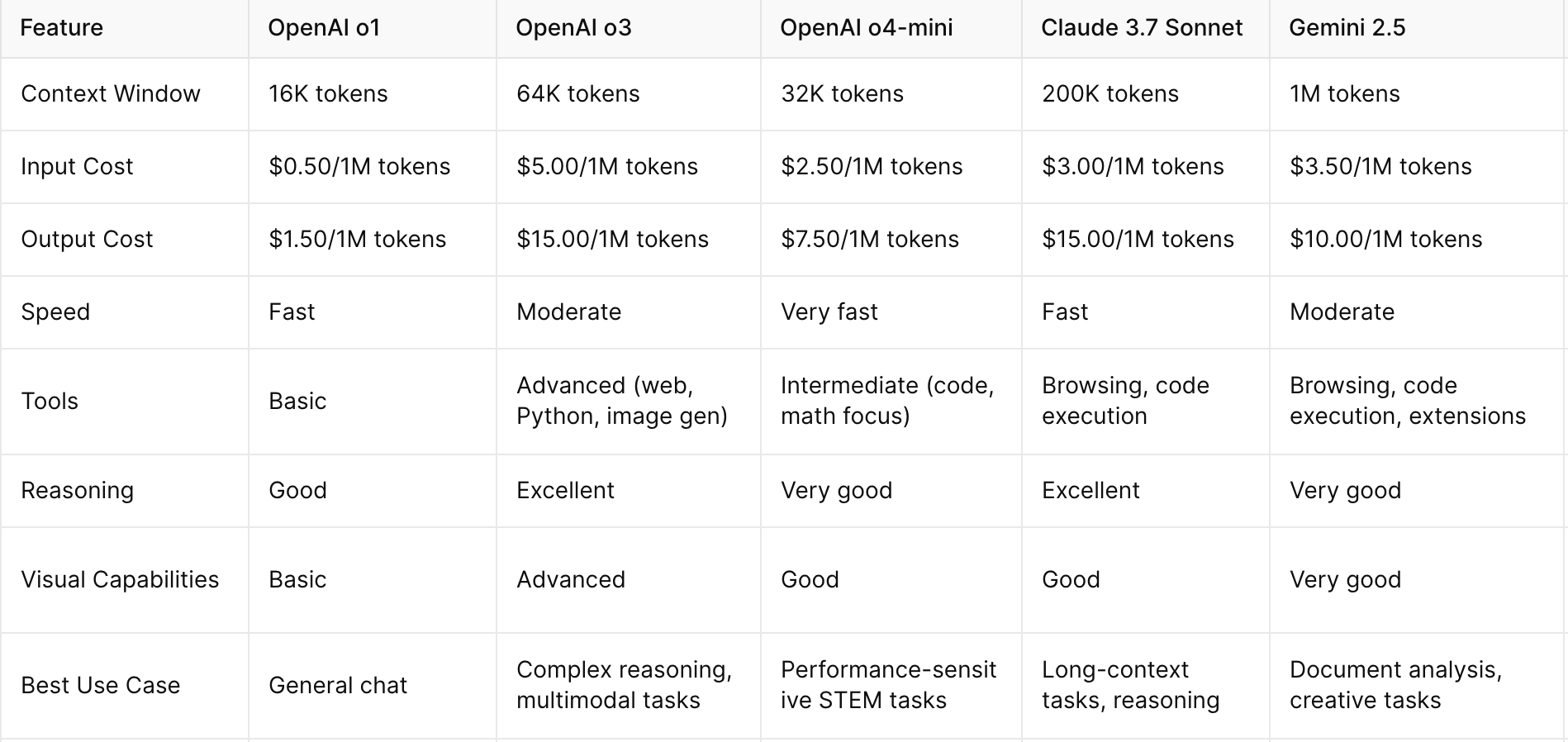
I've found that these pricing structures have a tangible impact on how I approach different projects. For a recent data analysis task, I started with the more expensive model for the exploratory phase where reasoning quality was crucial, then switched to a cheaper model once I had established my approach and was just running variations of similar prompts.
Token economics aren't just abstract numbers—they've directly influenced my architectural decisions. For instance, when building a document processing pipeline last month, I implemented a pre-filtering step to reduce the input token count before sending content to the more expensive models. This reduced our costs by roughly 40% with minimal impact on quality.
The X.com Reaction: Enthusiasm Meets Analysis
The reaction on X has been fascinating to watch unfold. Many users expressed genuine excitement about the capabilities, particularly the models' agentic nature. One user described o3 as an AI that "doesn't just chat, it does stuff, sees, acts, and handles tasks like a boss," highlighting the shift toward AI that takes action rather than just responding.
Others were more analytical, placing these releases in a competitive context. Some posts framed the release as a strategic move to counter rivals like DeepSeek, whose R1 model had challenged OpenAI with cost-effective reasoning capabilities.
I found it telling that these models were specifically noted as "not GPT-5" but still representing significant advancements. This suggests OpenAI is deliberately managing expectations while still trying to maintain its perceived lead in the AI race.
What I didn't see much of in the X discourse was deep discussion about OpenAI's safety measures, like their "deliberative alignment" technique and biorisk monitoring - features highlighted in the technical announcements but seemingly overlooked in public conversation.
My Personal Take: Promise and Pragmatism
Having worked through multiple generations of AI models, I've learned to separate genuine advancement from incremental improvement. The o3 and o4-mini releases seem to offer real progress in several areas:
Tool integration: The ability to seamlessly use web search, Python, and image analysis feels like a meaningful step toward AI that can truly augment our workflows rather than just generate content.
Reasoning capabilities: Several users highlighted how these models are "setting new benchmarks across math, coding, science & multimodal reasoning," suggesting practical utility beyond chatbot-style interactions.
Developer focus: The Codex CLI shows OpenAI is thinking about how these models integrate into real development environments - something I've found lacking in previous releases.
However, I'm approaching these advances with cautious optimism. Some researchers have criticized OpenAI for prioritizing speed over safety, a concern that resonates with my own experience of seeing capabilities outpace governance.
What This Means For Developers
For those of us building with AI, these models represent both opportunity and challenge. The improved reasoning capabilities could make AI assistants more valuable for complex tasks like debugging, architecture planning, and data analysis. The multimodal nature opens new possibilities for processing visual information alongside text and code.
Looking at the token pricing, I'm struck by how o4-mini seems positioned as a more accessible entry point to advanced reasoning. At roughly half the cost of o3, it could be the sweet spot for many applications where the highest-tier reasoning isn't needed but basic models don't quite cut it.
I've already started rethinking how I architect AI pipelines because of these pricing differences. For instance, a chatbot I maintain could use o4-mini for the initial query understanding and routing, only escalating to o3 when complex reasoning is required. This tiered approach could substantially reduce costs while maintaining quality where it matters most.
At the same time, we face the ongoing challenge of adapting to a rapidly evolving landscape. OpenAI's broader strategy suggests integration into diverse applications, meaning we'll likely need to continuously reassess how these technologies fit into our stack.
Looking at the comparison table above, I'm struck by how each model seems to be carving out a distinct niche. While Gemini 2.5 and Claude 3.7 Sonnet offer larger context windows, the o3 and o4-mini models appear to be doubling down on reasoning quality and tool integration. This suggests we might be moving toward more specialized AI assistants rather than one-size-fits-all solutions.
I'm particularly interested in hands-on testing to validate the claims about performance in STEM fields. For coding specifically, looking at detailed benchmarks like SWE-Bench might provide more concrete insights than the general enthusiasm we're seeing on social media.
Looking Forward
These releases feel like another step in AI's transition from tools that generate content to systems that reason, act, and integrate across modalities. Whether they represent a genuine leap forward or just incremental improvement will become clear as developers like us put them through their paces in real-world applications.
The token economics outlined in my comparison table shouldn't be underestimated—they'll shape how these models get used in practice. I've already started sketching out revised architectures for some of my projects, looking for ways to leverage the strengths of each model while managing costs. Sometimes the "best" model technically isn't the best choice economically, and finding that balance is becoming an increasingly important skill.