
How AI Is Learning to Think, Not Just Talk
Why a 100-page academic paper on AI has me excited, and what it means for the rest of us.

I spent some time this weekend with a new academic paper, and it’s one I think is worth talking about. At over 100 pages, "A Survey of Reinforcement Learning for Large Reasoning Models" is a serious read. What makes it so interesting is its focus on a fundamental shift in AI: moving beyond models that just predict language to ones that can actually reason through complex problems.
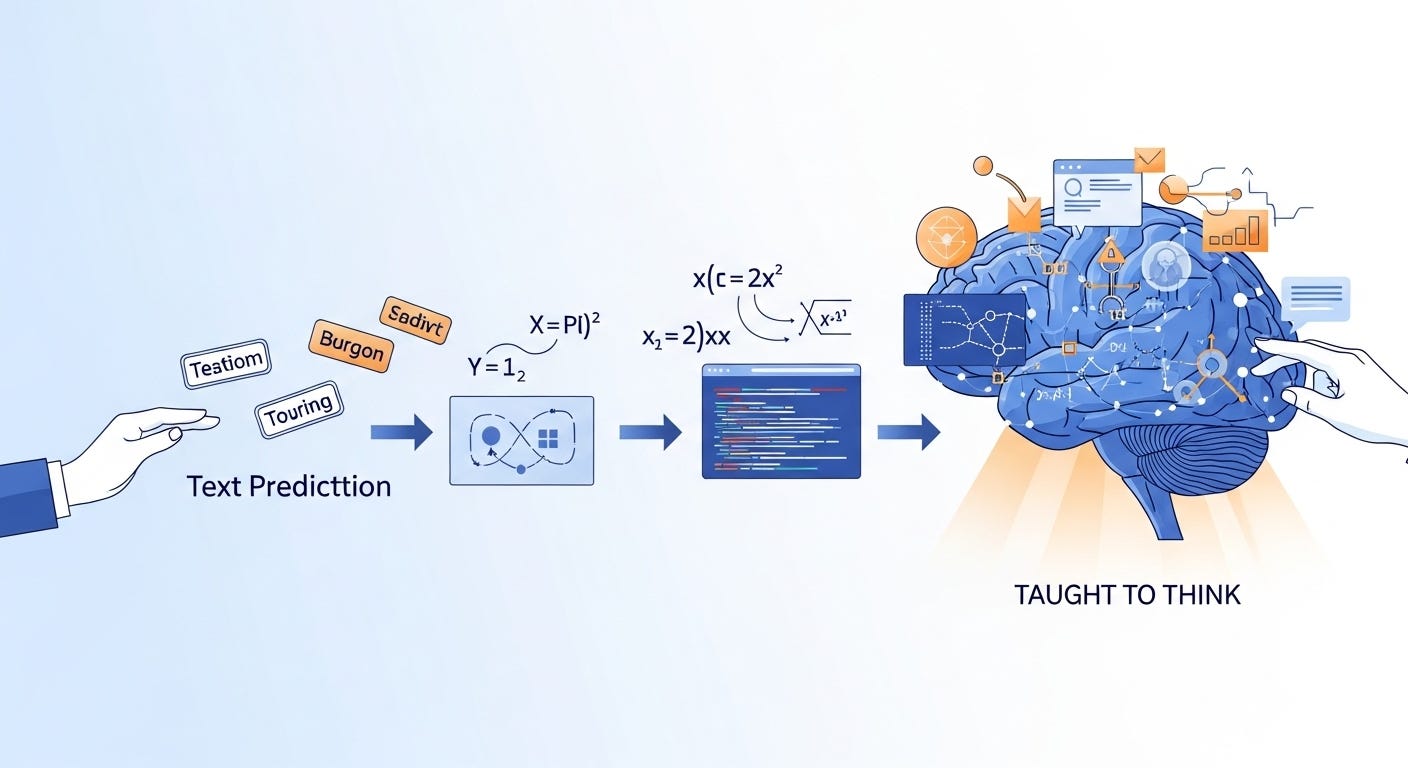
Many of us in business and science use AI every day, but it can be hard to see where the technology is truly headed next. This paper provides a clear map. My goal here is to summarize its main points for anyone curious about this next step, without requiring a deep technical background. For those who want to delve into the technical specifics, I've also written a companion post that provides much more detail.
From Predicting Words to a Process of Reasoning
So, what is the core idea?
Imagine you're teaching a student a difficult math concept. You wouldn't just show them the final answer. You would guide their process, pointing out where their logic is strong and helping them learn from their missteps.
This is essentially the approach behind using reinforcement learning (RL) to train AI. A detailed new survey from researchers at Tsinghua University and other institutions explains how this coaching method is helping create what they call Large Reasoning Models (LRMs). These are AI systems specifically designed to tackle multi-step logical challenges in fields like mathematics and programming.
Moving from an Answer Machine to a Problem Solver
Most of us know AI like ChatGPT for its ability to generate text. At their core, these models work by predicting the most probable next word in a sequence. This is incredibly effective for writing and conversation, but it has limitations when a task requires logic, planning, and a sequence of correct steps.
Reinforcement learning addresses this limitation directly. It’s the same technique that taught AI to master complex strategy games like Chess and Go. Instead of simply rewarding a correct final answer, RL trains the model on the process itself. The AI learns to:
Break down a problem into a series of smaller steps.
Evaluate the quality of its own chain of thought.
Learn from its failures to adjust its strategy.
Develop a systematic approach to solving problems.
This is already leading to significant progress in several areas:
Mathematics: Solving proofs and equations that require abstract steps.
Coding: Writing and debugging software more reliably.
Scientific Analysis: Assisting with logical deduction and forming hypotheses.
Planning: Handling complex tasks that depend on sequential thinking.
The survey points to models like DeepSeek-R1 as a key example of this progress. It was one of the first models to clearly demonstrate that RL could help an AI achieve human-level reasoning on certain tasks, showing this approach was more than just a minor tweak.
The Hurdles on the Path Forward
While the progress is compelling, the paper is also realistic about the challenges.
High Computational Cost: Training an AI to reason through trial and error requires an immense amount of computing power, which is both expensive and energy-intensive.
Need for Better Algorithms: Many current RL algorithms were not designed for the subtleties of human language and logic. New methods are needed to teach abstract thinking effectively.
The Data Bottleneck: High-quality training requires great data. It is difficult and expensive to create large datasets that include examples of both good and bad reasoning processes.
Complex Infrastructure: The hardware and software required to support these advanced models are becoming a major engineering challenge in their own right.
The Long Term Goal: Capable, Analytical AI
The ultimate aim of this work isn't just to build a slightly better assistant. The research is a step toward creating Artificial Superintelligence (ASI), or systems that could eventually reason more effectively than humans across many fields. The survey's authors view RL-based reasoning as a foundational piece of that puzzle.
This direction brings up critical questions for all of us:
Alignment: How do we ensure these highly capable systems operate in ways that are beneficial and aligned with human values?
Safety: What safeguards do we need as AI's analytical abilities continue to grow?
Access: How can we manage the development of these powerful tools so they benefit society broadly?
Why This Matters for Your Work
This shift from information retrieval to genuine problem solving will have practical implications for many of us.
In Education: AI tutors could help students learn how to think, not just find answers.
In the Workplace: AI assistants could help solve complex logistical problems, not just schedule meetings.
In Research: AI could act as a collaborator, helping researchers find new avenues for discovery.
The work described in this survey shows a clear direction for AI development. It’s a move away from AI that simply knows information to AI that can figure things out. Understanding this shift is the first step toward preparing for what comes next.
Want to dive deeper? The full survey is available at https://hf.co/papers/2509.08827, and the researchers have put together an excellent collection of resources on their GitHub repository