
From Tokens to Concepts
Understanding the Shift from LLMs to LCMs

I've been exploring the world of Large Language Models for a while now, learning about prompt engineering, fine-tuning techniques, and deployment strategies. Recently, I came across the ideas of Large Concept Models (LCMs) and found it to be an interesting evolution in how AI systems process language. I'd like to share what I've learned about this emerging approach and consider how it might apply to fields like biopharma research.

Breaking Down LLMs vs. LCMs: The Core Difference
LLMs and LCMs represent different approaches to language processing. LLMs work by analyzing and generating text token-by-token (typically word parts), predicting each token based on previous ones. LCMs, on the other hand, process entire sentences or ideas as single conceptual units. This is somewhat like the difference between reading word-by-word versus absorbing whole ideas at once - a potentially important distinction in how machines process language.
Under the Hood: The Technical Architecture of LCMs
Based on Meta's research papers, LCMs use a modular architecture consisting of three main components:
An encoder that translates input text into conceptual representations
A reasoning core that operates on these concepts
A decoder that converts concepts back into human language
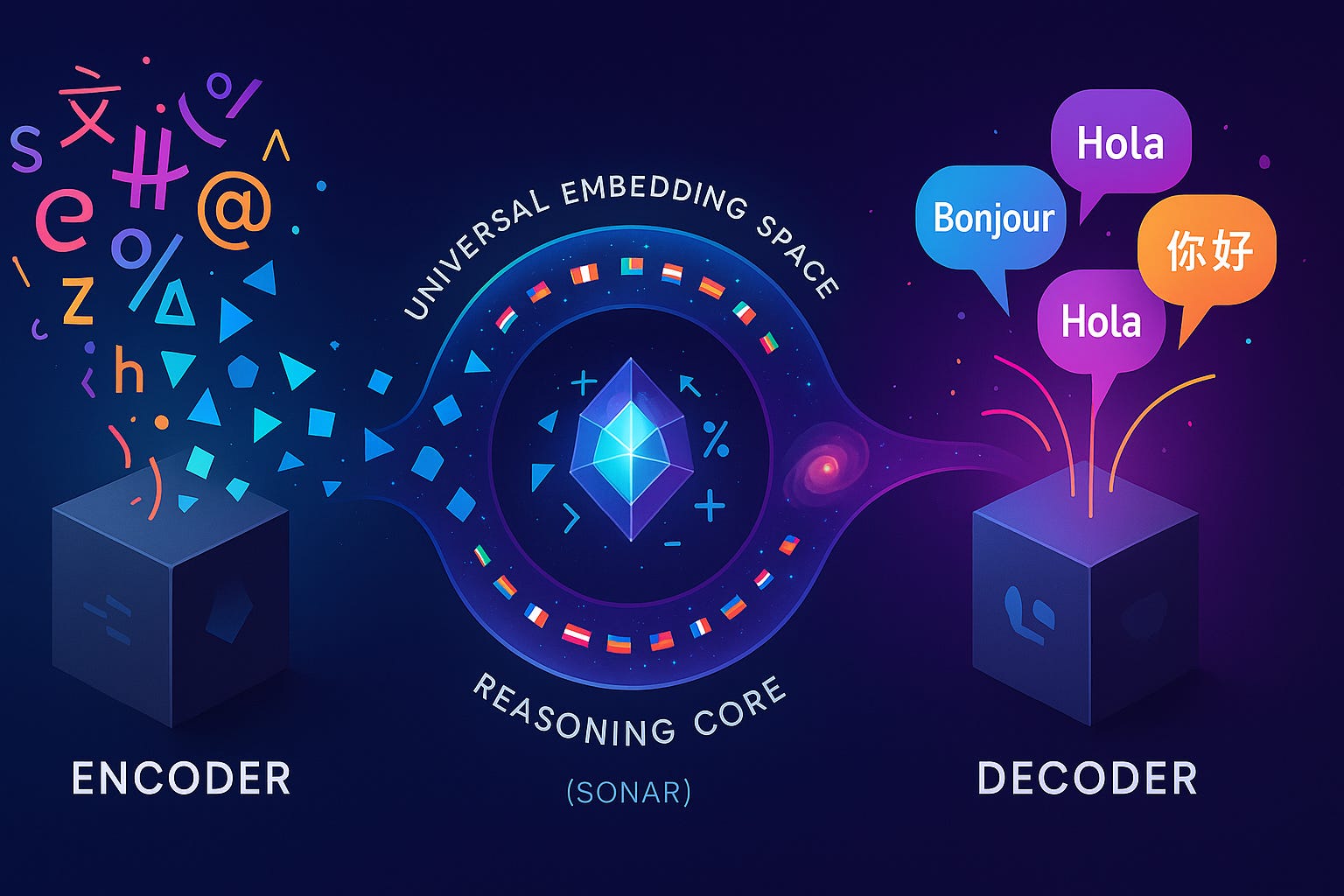
The architecture relies on a universal embedding space (such as Meta's SONAR) that maps sentences from over 200 languages into the same semantic space. This approach suggests several potential advantages:
Coherence over long passages: By maintaining a thread of concepts rather than generating one word at a time, LCMs could potentially maintain consistency better in extended outputs. This addresses a common limitation I've observed with current LLMs that sometimes lose track of their original point in longer responses.
Language agnosticism: The concept-level processing theoretically allows for handling multiple languages within the same model framework, as the concept space is language-independent.
Multimodal integration: The same concept space could encode information from text, speech, and potentially other modalities, which might simplify working with diverse data types.
It's important to note that these advantages are currently more theoretical than proven at scale. Current LCM implementations (like Meta's 7B parameter model) are still relatively small compared to frontier LLMs, and researchers acknowledge they don't yet match the largest LLMs across all benchmarks.
From what I understand, there may be efficiency benefits to processing information in larger conceptual chunks rather than individual tokens, but this would need to be demonstrated as these models mature and scale.
The Current Ecosystem: Available Tools and Resources
The LCM ecosystem is quite nascent compared to the well-established LLM landscape. For those interested in exploring this technology, here's what's currently available:
Meta has open-sourced both the SONAR embedding system and reference code for their concept model on GitHub. These resources are primarily research-oriented rather than production-ready tools. The documentation suggests you'll need substantial computational resources to run even the base models effectively.
There don't appear to be any dedicated cloud APIs or platforms offering LCM capabilities yet, though this might change as the technology develops. Currently, LCMs remain primarily in the research domain rather than readily available for practical applications.
Case Study: Biopharma R&D and LCMs
While considering potential applications of this technology, I found biopharma R&D—particularly oncology research—to be an interesting case study. This field deals with complex, multimodal, conceptually rich information that might benefit from LCMs' proposed capabilities:
Clinical Trial Document Summarization
Clinical trial protocols are lengthy, technical, and often dispersed across multiple documents. Researchers typically spend significant time manually extracting key information from these files.
An LCM could potentially read an entire oncology trial report and produce a coherent summary highlighting treatment methods, response rates, side effects, and conclusions—while maintaining the logical flow better than token-based models might. The concept-level understanding could help compare outcomes across multiple studies, supporting meta-analyses that currently require extensive human effort.
Integrating Imaging and Textual Data
One of the challenges in oncology research is the need to consider both visual data (radiology scans, pathology slides) and textual information (reports, clinical notes) simultaneously.
While current LCMs don't yet support image modalities, their architecture is designed to potentially allow this extension. The possibility of encoding both a pathology image and its accompanying report into the same concept space could enable reasoning about them together—similar to how a human doctor integrates different types of information.
Biomarker Discovery Through Conceptual Connections
Perhaps the most intriguing potential application is in biomarker discovery, which often involves connecting diverse information—genomic data, clinical outcomes, biochemical pathways—to identify meaningful patterns.
An LCM-based system might be able to identify when certain patterns (like a gene expression signature and an imaging finding) frequently appear together in cases where a particular treatment was effective, suggesting a potential biomarker. By operating at the concept level, such a system could potentially find non-obvious connections across different studies and data types.
A hypothesis worth exploring: Concept-level processing might be better suited for finding connections across disparate data sources than token-level processing, which could accelerate discovery in complex research domains.
What's particularly appealing about this application is how it aligns with the way researchers already think—connecting concepts and ideas rather than just analyzing words and phrases.
Reflections and Future Directions
Learning about LCMs has been an interesting journey that's expanded my understanding of different approaches to AI language processing. While the technology is still emerging, it represents a noteworthy direction in how AI systems might evolve to handle information more conceptually.
The shift from token-based to concept-based processing addresses some limitations of current LLMs and suggests new possibilities, particularly for specialized domains like healthcare and scientific research. However, it's too early to definitively say how significant this approach will prove to be in practice.
For those interested in this area, keeping an eye on Meta's SONAR implementation and other developments in concept-based processing could be worthwhile. As with any emerging technology, maintaining realistic expectations about current capabilities while recognizing future potential seems the most balanced approach.
I'm curious to see how this field develops and particularly how concept-level processing might complement other approaches to AI. The potential applications in domains like biopharma research are particularly interesting to consider as these models mature.