
Decoding AI in Cancer Research
A Practical Guide to Interpretability and What’s Next

Understanding the evolution of AI interpretability in cancer research and why it matters for the future of medicine
In 2024, AlphaFold’s creators won the Nobel Prize in Chemistry. The AI had predicted structures for over 214 million proteins, a feat that would have taken human researchers centuries. But here’s the fascinating part: we still don’t fully understand how it works.
This isn’t a crisis. It’s the natural next frontier in AI development.
As foundation models grow more powerful in oncology and biological research, a critical question emerges: How do these systems actually work? If you’re going to participate in conversations about AI in cancer research, here’s what you need to understand.
The Power: What Foundation Models Are Achieving
The capabilities are real and transformative.
ESM3, a 98-billion-parameter protein language model, created a novel fluorescent protein with only 58% sequence similarity to known fluorescent proteins. This represents approximately 500 million years of evolutionary distance. AlphaFold 3 achieved a 50% improvement over specialized tools for predicting protein-ligand interactions. These aren’t incremental advances. They’re genuine breakthroughs.
The real-world impact is equally striking.
Success Story: Insilico Medicine
Insilico Medicine’s AI-designed drug candidate, ISM001-055, reached Phase IIa clinical trials in under 30 months, compared to the typical 4-6 year timeline for traditional drug discovery. The Phase IIa results for idiopathic pulmonary fibrosis showed dramatic differences: patients on the highest dose (60 mg once daily) showed a mean improvement of 98.4 mL in forced vital capacity, while the placebo group showed a mean decline of -62.3 mL.
This represents a potential disease-modifying treatment discovered and developed primarily through AI-driven approaches.
Success Story: IDx-DR
In 2018, IDx-DR became the first FDA-approved autonomous AI diagnostic system. Validated on 900 patients across 10 primary care sites, it achieved approximately 87% sensitivity and 90% specificity for detecting diabetic retinopathy. This outperformed typical ophthalmologist screening (33-73% sensitivity).
These models are not replacing human expertise. They’re augmenting it, handling complexity beyond human cognitive limits, and accelerating research by finding patterns in millions of patient records.
The Architecture: A Brief Primer
To understand the interpretability challenge, you need to grasp one key concept: the difference between dense and sparse neural networks.
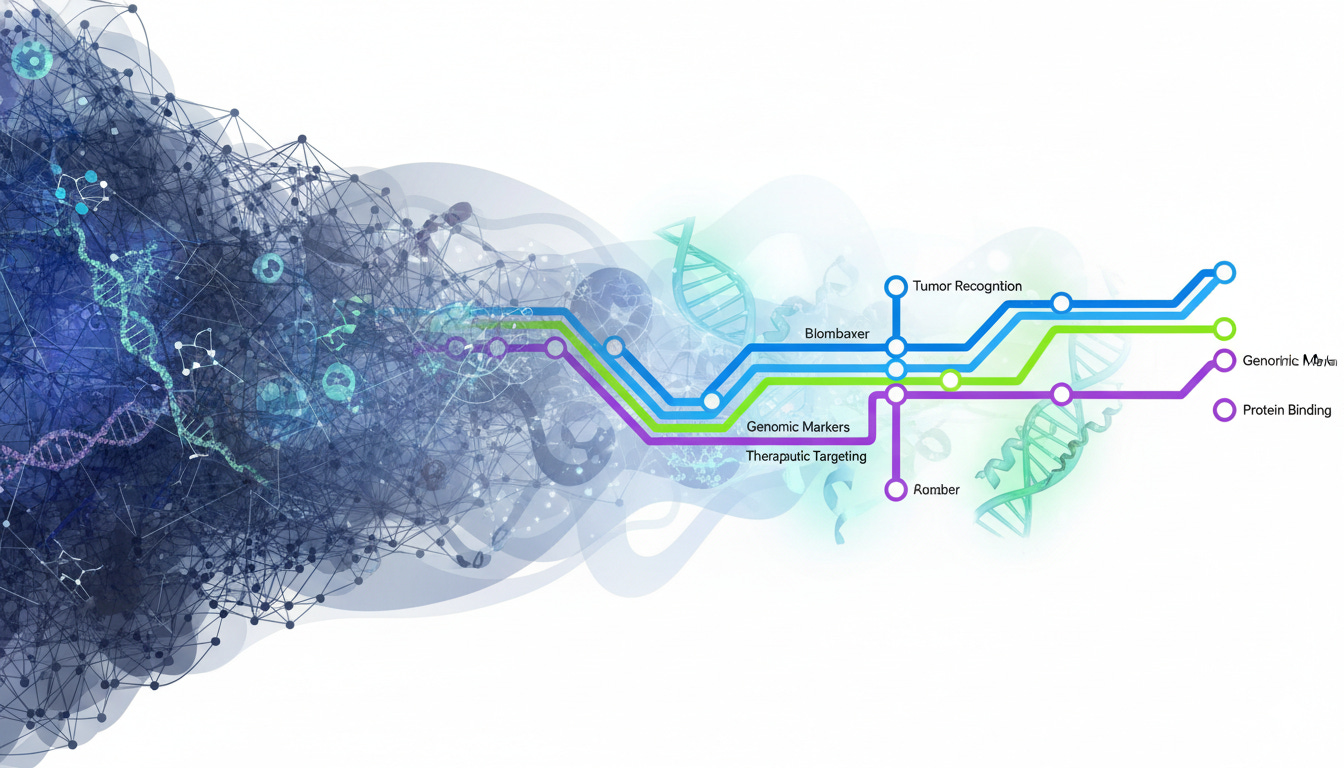
The Subway Map Analogy
Dense Networks (Traditional Approach): Think of a tangled web where every station connects to every other station. Billions of connections with no clear logic. We can see the inputs (patient data) and outputs (predictions), but the reasoning path between them is opaque. This is the “black box” phenomenon.
Sparse Circuits (Emerging Approach): Think of a clean subway map with dedicated lines. Each “circuit” has a clear function: one line for tumor recognition, another for genomic markers. You can trace exactly how the system traveled from evidence to conclusion.

The Key Insight
Old assumption: Performance requires complexity (opacity).
New evidence: Sparse models can match or exceed dense models while being interpretable.
Concrete Example: In a 2024 OpenAI research paper, researchers demonstrated a sparse transformer that learned to complete programming quotes (like matching “ with “ or ‘ with ‘) using an incredibly minimal circuit. Just 5 information channels, 2 decision-making neurons, and 1 attention mechanism.
Think of it like a simple recipe with four steps:
Recognize when you see a quote mark
Remember what type it is (single or double quote)
Find the previous quote in the code
Predict the matching closing quote
The remarkable part: when researchers removed everything else from the model except this tiny circuit, it still worked perfectly. This proves the circuit is both complete (it does the whole job) and understandable (we can explain each step).
This challenges the old assumption that AI models must be complex and opaque to be powerful.
The Interpretability Toolkit: Where We Are Today
Researchers have developed three main approaches to understanding AI models, each with different strengths and limitations.
1. Post-hoc Explanations
These methods are applied after training to explain decisions.
SHAP (SHapley Additive exPlanations) and LIME show which features mattered most for a prediction. It’s like asking someone to explain their decision after they’ve made it. They’re useful but computationally expensive and struggle with correlated features (common in biological networks).
Attention visualization and saliency maps show what the model “looks at” in images or sequences. For example, the TITAN model (Transformer-based pathology Image and Text Alignment Network) has attention heads that specialize. One focuses on dense tumor regions, another on surrounding stroma. TITAN, trained on 335,000 whole-slide images from 20 organs, can generate natural language pathology report summaries.
These methods are useful but don’t reveal the underlying mechanism.
2. Biology-Informed Architectures
The concept: build biological knowledge into the structure from the start.
BINNs (Biologically Informed Neural Networks) have nodes that represent actual biological entities: proteins and pathways from databases like Reactome and KEGG. They achieved 98.6% accuracy for classifying sepsis-induced acute kidney injury subphenotypes using only thousands of parameters (versus millions in dense networks). The architecture is inherently interpretable because its structure mirrors biology.
P-NET and DrugCell use similar pathway-aware architectures. P-NET achieved 83% accuracy (0.93 AUC) for prostate cancer prediction and often outperformed traditional machine learning approaches while maintaining full interpretability. You can trace predictions through known biological pathways.
The advantage: these models speak the language of biology from the start.
3. Mechanistic Interpretability: The Frontier
The goal: reverse-engineer models into human-understandable algorithms.
Sparse Autoencoders (SAEs) disentangle “superposed” features, where multiple biological concepts are packed into single neurons. The InterPLM framework applied SAEs to protein language models and discovered thousands of interpretable features representing binding sites and structural motifs. Researchers can even “steer” protein properties by activating specific features.
Circuit extraction identifies minimal functional subnetworks: the smallest set of neurons and connections needed for a specific task. This reveals what the model actually learned versus what we think it learned.
Why this matters: it catches models learning shortcuts instead of biology.
The Shortcut Problem: A Learning Opportunity
A 2024 study by Bushuiev et al. examined 32 published deep learning methods for protein-protein interaction prediction, all claiming 90-99% accuracy on standard benchmarks. When data leakage was eliminated (ensuring minimal sequence overlap between training and test sets), all 32 methods dropped to approximately 50% accuracy (random chance).
They had learned shortcuts: sequence similarity patterns and node degree biases (exploiting the fact that some proteins only appeared in positive or negative sample sets) rather than actual biological binding mechanisms. Twelve of the 32 methods had no available source code, highlighting reproducibility issues.
This isn’t a failure of AI. It’s a lesson in implementation. Interpretability catches these failures before deployment.
Success Stories in Oncology
MICE: Multimodal Integration
MICE (Multimodal data Integration via Collaborative Experts), published in 2025, combines whole-slide pathology images, genomic data, and clinical text for cancer prognosis. Analyzing 11,799 patients across 30 cancer types, it improved prognostic accuracy (C-index) by 3.8-11.2% on internal validation and 5.8-8.8% on external validation.
The model uses interpretability methods including SHAP analysis, saliency mapping, and gene enrichment analysis. It validated known biology and generated new hypotheses, such as flagging neuroactive ligand-receptor interactions in breast cancer. This suggests new research avenues.
The AlphaFold Lesson
AlphaFold’s success wasn’t just about accuracy. It was about confidence scores (pLDDT) that tell researchers when to trust predictions. This transparency accelerated adoption across over 2 million researchers in 190+ countries.
When users can assess reliability, they can make informed decisions about how to use predictions in their research.
The Regulatory Reality: Separating Fact from Fiction
Let’s be clear about what regulations actually require.
FDA (United States)
On January 7, 2025, the FDA published draft guidance titled “Artificial Intelligence-Enabled Device Software Functions: Lifecycle Management and Marketing Submission Recommendations.”
What it requires:
Clear information on logic and explainability
Providers must be able to “independently review the basis for recommendations”
Documentation of performance metrics, known limitations, and bias management strategies
What it does NOT require: Full mechanistic interpretability. The bar is “explainability,” not “complete understanding.”
In practice, this means validation, audit trails, and performance monitoring. Interpretability is an advantage that accelerates approval, but it’s not always a mandatory requirement.
EU AI Act (August 2026)
The EU AI Act enters force August 1, 2024, with most provisions fully enforceable August 2, 2026 (extended to August 2, 2027 for medical AI in regulated products).
Requirements for high-risk medical AI:
Risk management systems throughout the AI lifecycle
Technical documentation and record-keeping
Human oversight mechanisms
Guarantees of accuracy, robustness, and cybersecurity
GDPR Article 22 provides the right to contest automated decisions, requiring audit trails and documentation.
The Clinical Adoption Factor
Regulations are one thing; clinician trust is another.
Interpretability accelerates adoption even when it’s not required for approval. The real driver: Can a physician explain the recommendation to a patient?
When a model highlights perineural invasion on a pathology slide, clinicians can verify with their own eyes. Trust builds. The AI transforms from an opaque oracle into a collaborative partner whose work can be verified.
The Future: Where Interpretability Is Heading
The field is moving fast, and the convergence of performance, interpretability, and regulatory compliance is creating new possibilities.
Sparse Circuits at Scale
The vision: pre-train foundation models to be sparse from initialization, building interpretability in from the ground up rather than retrofitting it later.
Early evidence suggests larger sparse models can be both more capable AND more interpretable, challenging the old performance-transparency trade-off.
Automated Circuit Discovery
Meta-interpretability: using AI to find circuits in AI. The InterPLM framework uses language models to automatically label discovered protein features, scaling human understanding through automation.
Interactive Interpretability
Visual Question Answering (VQA) allows users to ask models “Why did you predict this?” and receive real-time explanations in natural language.
MUSK (Multimodal transformer with Unified maSKed modeling), a 2025 Stanford model, was trained on 50 million pathology images and 1 billion text tokens. It achieves 73% accuracy on visual question answering tasks, enabling interactive probing of the model’s understanding. Users can ask about cancer types, biomarker predictions, and treatment suggestions.
TITAN generates pathology reports explaining its reasoning, bridging the gap between AI predictions and clinical communication.
Biology-First Design
The convergence: architecture + biology + interpretability as one integrated approach.
Models where connectivity mirrors biological hierarchies (proteins to pathways to cells to tissues). Attention mechanisms that focus on biologically meaningful regions. Priors based on gene regulatory networks.
This isn’t three separate goals (performance + interpretability + compliance). It’s one integrated approach from the start. The competitive advantage goes to those who build all three together.
Practical Takeaways: How to Engage in the Conversation
Key Concepts to Understand
1. Black box ≠ Bad
It’s a design choice with trade-offs. Dense models can be powerful; sparse models can be interpretable. The field is moving toward having both.
2. Interpretability is a Spectrum
From post-hoc explanations (SHAP, attention maps) to architecture-based approaches (BINNs, pathway-aware models) to mechanistic understanding (circuit extraction, SAEs).
3. Regulatory Requirements Are Evolving
Focused on explainability and documentation, not necessarily full mechanistic transparency. Interpretability accelerates approval and adoption.
4. The Field Is Moving Fast
Sparse circuits and SAEs are recent breakthroughs (2023-2025). Multimodal oncology models are just emerging. What’s cutting-edge today will be standard tomorrow.
Questions to Ask When Evaluating AI in Oncology
Validation: Single-site or multi-site? Retrospective or prospective?
Training Data: How diverse? What are potential biases?
Interpretability Methods: Post-hoc, architecture-based, or mechanistic?
Explainability: Can the model explain its reasoning? To what degree?
Failure Modes: What are the known limitations? (Every model has them)
The Balanced Perspective
Be Bullish on Potential
The capabilities are real and transformative. We’re seeing genuine breakthroughs in drug discovery, diagnostics, and research acceleration. AlphaFold, ESM3, Insilico Medicine’s drug candidates: these represent fundamental advances in how we approach biological problems.
Be Critical of Implementation
Not all AI is created equal. Validation matters more than hype. Diverse training data and multi-site testing are essential. The 32 protein interaction models that failed when properly tested remind us that impressive benchmark performance doesn’t always translate to real-world capability.
Demand Transparency
Not because black boxes are inherently bad, but because understanding accelerates progress. Interpretability catches shortcuts, builds clinical trust, and enables scientific discovery. It transforms AI from a prediction engine into a hypothesis generator.
Engage with the Science
The more people understand these systems, the better they become. Informed conversations drive better research and better tools. The future of AI in oncology isn’t about choosing between power and transparency. It’s about building systems that deliver both.
The Real Question
The question isn’t “Can we trust AI in oncology?”
It’s “How do we build AI in oncology that we can understand, validate, and improve?”
We’re moving toward a future where AI doesn’t just predict outcomes but reveals mechanisms. Where models are collaborative partners in discovery, not opaque oracles. Where the power of AI and the clarity of human understanding work together.
For researchers: Invest in interpretability from the start, not as an afterthought.
For clinicians: Engage with these tools, ask questions, demand explanations.
For everyone: Participate in the conversation with facts, not fear.
That’s the conversation worth having.