
Can AI Do the Job? OpenAI Just Changed How We Answer That Question.
GDPval measures economic value over extended work, not test scores. The results are revealing, and uncomfortable.

We face a persistent gap between impressive AI demos and disappointing results. You’ve seen the ChatGPT screenshots that make the rounds on Twitter. You’ve sat through vendor pitches promising to automate entire departments. Then you try to deploy it, and yeah, not so much.

OpenAI just released a benchmark where their own model came in second. But that’s not the interesting part. The interesting part is what they’re actually measuring, and what happens when you stop evaluating AI like a student taking tests and start evaluating it like an employee doing work.
GDPval measures model performance on “economically valuable” tasks across 44 occupations. These aren’t quick coding challenges or multiple-choice questions. These are multi-hour tasks that mirror actual knowledge work, complete with access to the same tools humans use: search, code execution, documentation. The name itself is blunt. GDP value. Economic output. Can this thing do work that matters to your bottom line?
Early results show Claude 4.1 Opus topping most categories, approaching or beating human industry experts. GPT-5 “high,” presumably OpenAI’s most capable internal model, trails behind. The benchmark is public, methodology included, and OpenAI is positioning this as a key metric for policymakers and labor market forecasting. Larry Summers is involved, which tells you this isn’t just another ML leaderboard.
For tech leaders weighing AI and agentic systems for their companies, GDPval isn’t just another data point. It’s a framework that forces you to ask better questions, and some of those questions are uncomfortable.
Why Economic Value, Not Intelligence?
Traditional benchmarks measure potential. MMLU tests broad knowledge across academic subjects. HumanEval measures coding ability on isolated problems. These tell you if a model is smart. They don’t tell you if it can do a job.
The shift mirrors what tech leaders actually need to know. Not “can this model answer trivia questions?” but “can this replace or meaningfully augment my $150K analyst?” Not “can it write a function?” but “can it debug a production issue at 2 AM and document the fix?”
Multi-hour tasks with tool access change the evaluation entirely. A model that scores brilliantly on isolated questions might completely fall apart when asked to maintain context over a three-hour research task. One that can generate clean code in a sandbox might fail when it needs to navigate your actual codebase, search Stack Overflow, and read through legacy documentation.
The 44 occupations span knowledge work where companies are actually piloting AI. We’re not talking about theoretical capabilities. We’re talking about roles where you’re already wondering if you should hire your next analyst or invest in AI infrastructure instead.
OpenAI is moving the goalposts from “is AI smart?” to “is AI economically deployable?” This matters because it changes how you evaluate ROI on AI investments. You’re no longer comparing benchmark scores. You’re comparing cost per unit of work output, factoring in quality, reliability, and the overhead of human supervision.
The Human Expert Comparison, and What It Reveals
“Approaching or beating human experts” sounds incredible. It’s the kind of claim that gets repeated in board meetings and funding pitches. But what does it actually mean?
The details matter enormously here. Which tasks are we talking about? Which occupations? Research synthesis and report generation? Financial modeling? Legal document review? Software architecture decisions? The complexity and stakes vary wildly.
If available data breaks down performance by occupation category, pay attention to where AI leads and where it trails. My guess, and this is speculation without the full data, is that AI performs strongest on high-volume, pattern-matching work and weakest on tasks requiring judgment calls with incomplete information or significant downside risk.
Multi-hour complexity is the real test. Can the model maintain quality and coherence over extended work? Does it drift off task? Does it forget context from hour one by hour three? Humans get tired, but they also course-correct when they realize they’re going down the wrong path. Does AI?
Here’s the deployment question that matters most: If AI scores 85% of expert performance, which 15% of tasks still need humans? And critically, are those the most important 15%?
This is where benchmark performance diverges sharply from production reliability. “Approaching expert” might mean “great at 80% of the work, catastrophically wrong on 5%, and mediocre on the rest.” The economic calculation gets complicated fast. Even at 90% expert performance, if the 10% failures require expert oversight anyway, have you actually saved money? Or have you just added a review layer to your workflow?
Consider a legal research task. If AI can draft 90% of a memo correctly but occasionally hallucinates case law or misinterprets precedent, you need a lawyer to review everything anyway. You might have sped up the drafting process, but you haven’t eliminated the expensive human. You’ve changed their role from writer to editor, which is valuable but not transformative.
Or take financial analysis. If a model can build sophisticated models but sometimes makes subtle errors in assumptions that cascade through the analysis, someone needs to check the work. And checking complex analytical work isn’t much faster than doing it yourself.
The benchmark gives you signal about capability. It doesn’t give you certainty about reliability. And in production systems, reliability often matters more than peak performance.
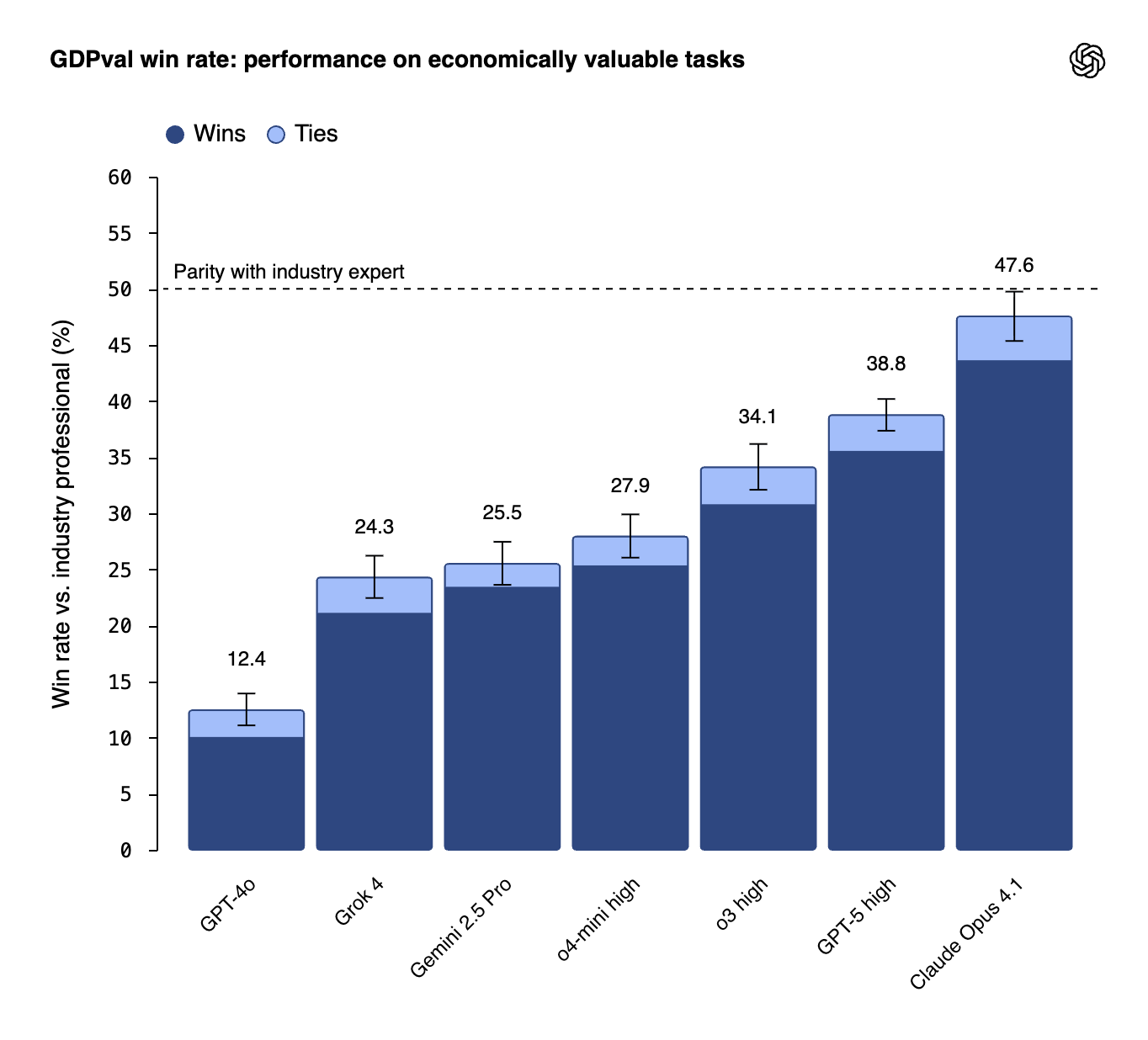
Claude Wins, GPT-5 Trails. What This Tells Us
OpenAI created the benchmark. Anthropic’s Claude 4.1 Opus leads most categories. GPT-5 “high” underperforms. This isn’t just ironic. It’s a signal about what actually matters in sustained, complex work.
For procurement decisions, the brand name isn’t winning on work-like tasks. That should give any tech leader pause if they’ve been defaulting to OpenAI models because “everyone uses GPT.” Different architectures matter, and they matter in ways that don’t show up in traditional benchmarks.
Claude’s approach involves constitutional AI, longer context windows, and different training strategies. These design choices may be better suited to the kind of multi-hour, multi-step tasks that GDPval measures. It’s possible Claude trades raw capability on narrow tasks for consistency and reliability on complex ones.
Tool use integration could be the differentiator. How each model handles search results, executes code, and navigates documentation might matter more than underlying intelligence. An extremely capable model that struggles to effectively use tools loses to a slightly less capable model that integrates tools seamlessly.
This raises questions for anyone building agentic systems. Are you testing the right things in your AI pilots? If you’re running evals that look like traditional benchmarks, quick tasks, isolated problems, clean data, you might be optimizing for the wrong thing. Your production environment looks more like GDPval: messy, multi-step, tool-dependent work that unfolds over hours.
Should you be evaluating multiple models for different task types? Maybe Claude for sustained analytical work, GPT for creative brainstorming, specialized models for domain-specific tasks. The era of “we’re a GPT shop” or “we’re all-in on Claude” might be ending. The winning strategy could be orchestration across models based on task characteristics.
The competitive dynamics are also worth watching. If Anthropic continues to lead on economically valuable tasks while OpenAI leads on benchmarks measuring raw capability, that tells you something about the deployment gap. It suggests that the path from “impressive model” to “reliably productive model” involves more than scaling. It might involve fundamental choices about architecture, training, and design philosophy.
The Public Methodology: Transparency or Marketing?
OpenAI making GDPval public with full methodology is notable. They don’t have to do this. Most AI labs keep their evals internal or release only summary results. So why the transparency?
Several possible motivations, and they’re not mutually exclusive.
Policy play. Larry Summers’ involvement signals that this is aimed at economists and policymakers, not just AI researchers. If you’re trying to influence AI policy and labor market planning, you need a framework that policymakers trust. Public methodology builds that trust. It also establishes GDPval as the benchmark for economic impact before competitors can define alternatives.
Standard-setting. First mover advantage in measurement frameworks is real. If GDPval becomes the accepted way to evaluate AI’s economic impact, OpenAI shapes the conversation even if their models don’t lead the benchmark. It’s like creating the test everyone else has to take.
Trust-building. OpenAI has faced criticism about closed evaluations and cherry-picked benchmark results. Radical transparency on methodology counters that narrative. It says “we’re showing our work, come verify it yourself.”
Competitive pressure. Here’s the cynical read: If GPT-5 can’t win on internal testing, better to set the terms of evaluation publicly and make it about economic value rather than raw capability. If you’re going to lose, lose on your own scoreboard.
https://openai.com/index/gdpval/
For tech leaders, the transparency is genuinely useful. But approach it with questions:
Who selected the 44 occupations? Look for bias toward certain types of knowledge work. Are they overweighting tasks that AI happens to be good at? Are they underweighting interpersonal work, creative synthesis, ethical judgment, or other areas where humans maintain clear advantages?
How were “expert” benchmarks established? What does “human expert” mean here? Someone with five years of experience? Ten? Twenty? Industry experts vary widely in capability. If you’re comparing AI to median experts rather than top performers, the bar is lower.
What’s missing? GDPval focuses on economically valuable tasks, which implicitly means tasks that produce measurable output. That’s a lot of knowledge work, but not all of it. Leadership, mentorship, culture-building, cross-functional collaboration, these matter economically but resist easy measurement.
Can you reproduce these tests with your own use cases? The real value of a public methodology is that you can adapt it. If GDPval measures general occupational tasks, what would a benchmark look like for your specific workflows, your data, your quality standards?
The methodology matters more than the results. Results will change as models improve. A good evaluation framework lasts.
The Uncomfortable Truth
GDPval forces a question most tech leaders prefer to avoid. We’ve been asking “can AI do this job?” when we should be asking “at what cost can AI do enough of this job to change our workforce strategy?”
The first question is about capability. It’s interesting academically, impressive in demos, and largely useless for decision-making. The second question is about economics. It’s harder to answer, uncomfortable to ask publicly, and essential for actually deploying AI at scale.
OpenAI just gave us a framework to answer that question. The methodology is public. The occupations are defined. The tasks are realistic. You can adapt this approach to your specific context. You can measure before you invest, and you can measure again after you deploy to see if the results hold up.
Whether we like the answer or not, we now have a way to get it. That’s progress. Uncomfortable progress, but progress nonetheless.
The real test isn’t whether AI can beat humans on GDPval. The real test is whether companies can figure out what to do with that information. Most won’t. They’ll keep running impressive demos and wondering why results disappoint. A few will take this seriously, build proper evaluation frameworks, make hard decisions about workforce strategy, and gain real competitive advantage.
Which camp you’re in depends on whether you’re willing to ask uncomfortable questions and act on honest answers.